RHEL 10 перемещает базовые системные требования на x86-64-v3, то есть Intel Haswell или новее или AMD Excavator и более поздние версии. Вашим x86-компьютерам понадобится Intel AVX2, а также Fused Multiply-Add и несколько других современных расширений ЦП, которые Red Hat описала в январе 2024 года. AlmaLinux 10 уже находится в стадии бета-тестирования почти шесть месяцев, а Rocky Linux 10, как ожидается, выйдет к концу мая. Между тем, Oracle Linux 10 в се еще находится в стадии Developer Preview. ®
Векторные регистры — это области хранения в ядре ЦП, которые содержат операнды для векторных вычислений, а также результаты. Размер векторных регистров определяет уровень инструкций SIMD, которые могут поддерживаться ЦП данного процессора. Например, для поддержки набора инструкций AVX векторные регистры в процессоре Intel должны быть шириной не менее 256 бит. Такие регистры могут содержать четыре 64-битных двойных числа или восемь 32-битных чисел с плавающей точкой.
На рисунке ниже показаны различные наборы инструкций SIMD, которые Intel поддерживала в своих процессорах с течением времени, и размеры векторных регистров, связанные с каждым из них.
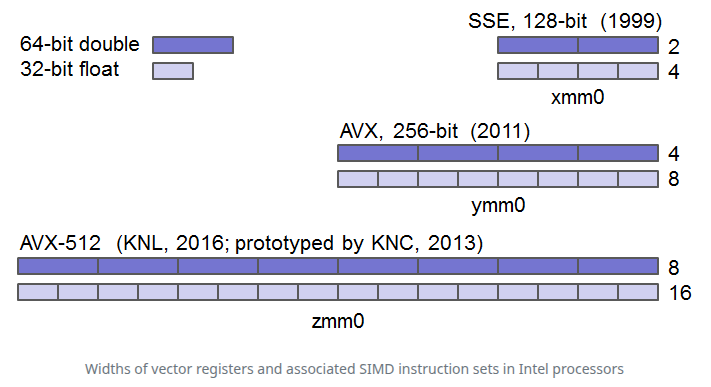
Intel® Advanced Vector Extensions 2.0 (Intel® AVX2) — это расширение набора инструкций Intel. Intel® AVX2 расширяет Intel® Advanced Vector Extensions (Intel® AVX) 256-битными целочисленными инструкциями, инструкциями с плавающей точкой Fused Multiple-Add (FMA) и операциями Gather. 256-битные целочисленные векторы приносят пользу программному обеспечению для обработки математики, кодеков, изображений и цифровых сигналов. FMA повышает производительность при распознавании лиц, профессиональной обработке изображений и высокопроизводительных вычислениях. Операции Gather расширяют возможности векторизации для многих приложений. Помимо векторных расширений, это поколение процессоров Intel добавляет новые инструкции по битовой манипуляции, полезные при сжатии, шифровании и программном обеспечении общего назначения.
Для получения дополнительной информации об Intel® AVX см. http://www.intel.com/software/avx
Intel® Advanced Vector Extensions (Intel® AVX) разработаны для достижения более высокой пропускной способности для определенных целочисленных и плавающих операций. Из-за различных характеристик мощности процессора использование инструкций AVX может привести к тому, что
a) части будут работать ниже базовой частоты
b) некоторые части с технологией Intel® Turbo Boost Technology 2.0 не смогут достичь какой-либо или максимальной турбочастоты.
Производительность зависит от оборудования, программного обеспечения и конфигурации системы, и вам следует обратиться к производителю вашей системы за дополнительной информацией.
===============================
Что означает аббревиатура SIMD
===============================
Single instruction, multiple data (SIMD) — тип параллельной обработки в таксономии Флинна. SIMD описывает компьютеры с несколькими элементами обработки, которые выполняют одну и ту же операцию над несколькими точками данных одновременно. SIMD может быть внутренним (частью аппаратного дизайна) и может быть напрямую доступен через архитектуру набора инструкций (ISA), но его не следует путать с ISA.
Такие машины используют параллелизм на уровне данных, но не concurrency : есть одновременные (параллельные) вычисления, но каждый блок выполняет точно такую же инструкцию в любой момент времени (просто с разными данными). Простым примером является сложение многих пар чисел вместе, все блоки SIMD выполняют сложение, но у каждого из них есть разные пары значений для сложения. SIMD особенно применим к общим задачам, таким как настройка контрастности цифрового изображения или настройка громкости цифрового звука. Большинство современных конструкций ЦП включают инструкции SIMD для повышения производительности использования мультимедиа. В последних ЦП блоки SIMD тесно связаны с иерархиями кэша и механизмами предварительной выборки, которые минимизируют задержку во время операций с большими блоками. Например, процессоры с поддержкой AVX-512 могут предварительно выбирать целые строки кэша и применять объединенные операции умножения-сложения (FMA) в одном цикле SIMD.