Сравнительный анализ производительности Polars и pandas при обработке больших данных

В условиях стремительного роста объемов данных эффективность инструментов для их обработки становится критически важной. В современной аналитике Python-библиотеки pandas и Polars играют ключевую роль, однако при работе с большими наборами данных (Big Data) различия между ними становятся существенными. Данное исследование направлено на сравнение производительности этих двух библиотек в задачах чтения, фильтрации, группировки и агрегации данных, подкрепленное экспериментальными данными и техническими объяснениями механизмов их работы.
Одним из наиболее критичных аспектов производительности является скорость выполнения базовых операций. Исследования показывают, что Polars значительно превосходит pandas в таких задачах, как чтение CSV-файлов, фильтрация данных и агрегация. Например, при работе с датасетом, содержащим около 17 миллионов строк, Polars читает CSV-файл за 7.79 секунд ± 1.11 секунды, тогда как pandas требует 1 минуту 27 секунд ± 2.43 секунды. Это означает, что Polars в более чем 10 раз быстрее выполняет данную операцию. Аналогичные результаты наблюдаются и в других задачах: например, фильтрация по условию 'Traffic_Signal == True' занимает у pandas в среднем 3.8 секунды ± 2.45 секунды, тогда как Polars выполняет эту же операцию за 1.37 секунды ± 1.18 секунды.
Дополнительным преимуществом Polars является поддержка многопоточности, которая реализуется автоматически без необходимости ручной конфигурации. Это позволяет эффективно использовать все доступные ядра процессора, что особенно заметно при выполнении сложных операций, таких как группировка и агрегация.Технические причины такого превосходства Polars заключаются в его архитектуре. Библиотека написана на языке программирования Rust, который известен своей высокой производительностью и безопасностью памяти. Кроме того, Polars использует формат Apache Arrow, обеспечивающий векторизованную обработку данных без необходимости их копирования в памяти. Это особенно важно при работе с большими файлами формата Parquet или CSV, где использование нулевого копирования позволяет значительно сократить время загрузки данных.
Такие показатели особенно важны для проектов, связанных с машинным обучением или бизнес-аналитикой, где скорость обработки данных напрямую влияет на общую производительность системы.Преимущества Polars также подтверждаются тестами на датасете Covertype, содержащем 581,012 строк и 54 столбца. В задаче фильтрации данных Polars оказался в 4.05 раза быстрее pandas (0.0741 секунд у pandas против 0.0183 секунд у Polars). При выполнении агрегации Polars продемонстрировал еще более впечатляющие результаты, будучи в 22.32 раза быстрее pandas (0.1863 секунды у pandas против 0.0083 секунды у Polars).
Таким образом, выбор между pandas и Polars должен основываться на конкретных требованиях проекта и характеристик данных.Однако стоит отметить, что pandas остается предпочтительным выбором для работы с небольшими датасетами. Несмотря на свою зрелость и обширную экосистему интеграций, pandas демонстрирует приемлемую производительность в задачах, не требующих обработки больших объемов данных. Например, для датасетов размером менее 1 ГБ разница в скорости между pandas и Polars может быть менее значимой, особенно если учетывается время, необходимое для адаптации кода под новый инструмент.
Сравнительный анализ потребления памяти Polars и pandas
В современных задачах анализа данных эффективность управления оперативной памятью играет ключевую роль, особенно при работе с большими датасетами. В этом контексте библиотека Polars демонстрирует значительные преимущества по сравнению с pandas в части потребления RAM, что обусловлено фундаментальными различиями в подходах к хранению и обработке данных. Одним из основных факторов является использование Polars Columnar-формата хранения данных на основе Apache Arrow, который обеспечивает более компактное размещение информации и минимизирует накладные расходы на выполнение операций. В отличие от pandas, где данные хранятся в виде блоков строк (row-based), формат Polars позволяет выполнять операции над столбцами напрямую, что снижает объем используемой памяти10. Например, при выполнении операций фильтрации или агрегации Polars резко уменьшает необходимость создания промежуточных объектов в памяти, что делает его более подходящим для работы с массивами данных размером более 10 ГБ
Исследования показывают, что Polars способен существенно снизить потребление RAM при решении аналогичных задач. Так, при выполнении агрегации и фильтрации временных рядов пользователи отмечают уменьшение использования памяти на порядок по сравнению с pandas. Это достигается благодаря строгому контролю типов данных и оптимизации внутреннего представления информации. Например, при работе с числовыми данными типа int64 или float32 Polars эффективно управляет выделением памяти, что особенно важно для задач, требующих точного контроля над ресурсами системы. При использовании pandas часто возникают ситуации, когда неявное преобразование типов данных приводит к увеличению потребления памяти. В свою очередь, Polars исключает подобные проблемы за счет строгого ограничения на смешивание типов данных в одном столбце, что хотя и усложняет миграцию существующих проектов, но повышает стабильность и предсказуемость работы с памятью.
Тем не менее, этот подход обеспечивает большую ясность и упрощает отладку кода.Ограничение на использование гибридных типов данных в Polars может быть как преимуществом, так и недостатком. С одной стороны, оно минимизирует ошибки, связанные с некорректным преобразованием типов, и улучшает производительность операций. С другой стороны, миграция проектов с pandas на Polars может потребовать дополнительных усилий для реструктуризации данных, особенно если исходные датасеты содержат смешанные типы данных. Например, разделение строковых и числовых значений, таких как 'lease_left' и 'freehold', ранее объединенных в pandas, требует переработки логики обработки данных.
Тип данных оказывает значительное влияние на использование памяти в обеих библиотеках. Например, при работе с числовыми значениями типа float32 Polars демонстрирует меньшее потребление RAM по сравнению с pandas, где преобладают типы данных с большим объемом выделенной памяти, такие как float64. Это особенно важно для задач машинного обучения и анализа больших временных рядов, где эффективное использование памяти напрямую влияет на скорость выполнения операций. Поларс также предоставляет возможность использовать ленивые вычисления, которые позволяют создавать граф запросов и оптимизировать выполнение операций без создания промежуточных объектов.
Однако эти затраты оправданы для задач, где требуется высокая производительность и эффективное использование ресурсов системы.Несмотря на очевидные преимущества Polars, следует отметить, что переход на эту библиотеку может потребовать адаптации к новому синтаксису и подходам к программированию. Например, использование LazyFrames добавляет сложности в процесс отладки и требует глубокого понимания принципов работы с ленивыми вычислениями
Многопоточность и автоматическая параллелизация в Polars: преимущества, ограничения и практическое применение
В современной эпохе больших данных обработка массивов информации становится все более зависимой от эффективного использования многоядерных процессоров. Одним из ключевых подходов к улучшению производительности вычислений является многопоточная обработка данных, которая позволяет распределить нагрузку между несколькими ядрами CPU для достижения более высокой скорости выполнения операций. Библиотека Polars, написанная на Rust, предлагает встроенную поддержку многопоточности и автоматическую параллелизацию, что делает её особенно привлекательной для задач анализа данных, требующих высокой производительности. В отличие от pandas, который работает в однопоточном режиме, Polars максимально использует доступные аппаратные ресурсы без необходимости дополнительной конфигурации пользователя, что значительно упрощает разработку кода для работы с большими датасетами
Сравнение подходов Polars и pandas показывает, что первая библиотека имеет значительное преимущество в области автоматической параллелизации. Например, при выполнении операций группировки и агрегации данных Polars демонстрирует существенное ускорение даже на одном доступном ядре процессора. Экспериментальные данные, собранные Saar Berkovich, показывают, что Polars выполняет операцию группировки и агрегации на 33% быстрее pandas на одном vCore, а при увеличении числа ядер до четырех разрыв увеличивается до 50%. Это подтверждает эффективность архитектуры Polars, которая оптимизирована для использования всех доступных аппаратных ресурсов. Подобный подход позволяет достичь значительного улучшения производительности без необходимости вручную настраивать распараллеливание задач, что часто требуется при использовании дополнительных библиотек, таких как Dask, для работы с pandas.
Особое внимание следует уделить роли Lazy API в Polars, который дополняет преимущества многопоточной обработки за счет создания графа выполнения перед запуском реальных вычислений. Lazy API позволяет оптимизировать запросы, выполняя только те операции, которые действительно необходимы, и минимизируя использование памяти. Например, при выполнении группировки данных по колонке 'State' и подсчете количества ID, Lazy API выполняет задачу за 1.27 секунды ± 203 миллисекунды, тогда как Eager API требует 8.42 секунды ± 1.19 секунды. Это делает Lazy API ключевым инструментом для работы с данными, превышающими доступную память, обеспечивая дополнительное ускорение за счет предварительной оптимизации запросов1. Однако стоит отметить, что освоение LazyFrames может оказаться сложным для новых пользователей, так как они требуют явного управления вычислениями, а ошибки в их работе могут быть трудноотлаживаемыми.
Эти факторы необходимо учитывать при принятии решения о внедрении Polars в рабочие процессы аналитиков.Несмотря на очевидные преимущества Polars, переход на эту библиотеку не всегда является простым решением. Ограничения, такие как невозможность смешивания типов данных в одном столбце, могут усложнить миграцию существующих проектов с pandas, где такая практика была допустимой11. Кроме того, хотя Polars обеспечивает высокую производительность благодаря своей архитектуре, основанной на Apache Arrow, он пока не имеет такой же глубокой поддержки временных зон и сложных типов данных, как pandas.
Функциональные особенности и удобство использования Polars: Сравнительный анализ с pandas.
Данный раздел направлен на подробное рассмотрение функциональных особенностей Polars, включая сравнение его API с pandas, оценку удобства использования и анализа реальных сценариев применения.В современной аналитике данных библиотеки для работы с табличными данными играют ключевую роль. Одной из наиболее популярных библиотек долгое время оставался pandas, однако в последние годы появился ряд альтернатив, среди которых выделяется Polars. Особенности его архитектуры и API позволяют рассматривать Polars как мощный инструмент для обработки больших датасетов, хотя переход с pandas требует освоения новых подходов к написанию кода
Одним из основных отличий между Polars и pandas является структура их API. В pandas фильтрация данных часто выполняется через булевы маски, тогда как в Polars используется метод .filter(). Например, чтобы отфильтровать строки, где значение колонки 'Traffic_Signal' равно True, в pandas применяется выражение df[df['Traffic_Signal'] == True], тогда как в Polars это выглядит как df.filter(pl.col('Traffic_Signal') == True). Такой подход делает код более читаемым и последовательным, особенно при использовании сложных цепочек операций. Однако этот синтаксис может потребовать времени на освоение для пользователей, привыкших к pandas5
Пользователи, переходящие с pandas на Polars, отмечают определенную кривую обучения, связанную с необходимостью адаптации к новому синтаксису. Особенно это касается тех, кто активно использует ленивые вычисления (Lazy API). Например, вместо метода read_csv в pandas для чтения данных в Polars рекомендуется использовать scan_csv, что позволяет оптимизировать запросы перед их выполнением. Хотя такой переход не требует значительного переобучения, он все же предполагает изучение новых концепций и подходов к организации кода
Еще одной важной особенностью Polars является отказ от традиционной индексации строк, характерной для pandas. В pandas индексация часто становится источником ошибок, таких как несоответствие состояния индекса после операций фильтрации или группировки. В Polars данные рассматриваются исключительно как двумерная таблица с гетерогенными типами данных, что делает поведение библиотеки более предсказуемым. Например, операции ресемплирования в Polars выполняются явно указанными методами, что упрощает понимание логики обработки данных
Простота создания конвейеров обработки данных в Polars также заслуживает внимания. Благодаря поддержке цепляемых выражений (chainable expressions), Polars позволяет записывать сложные преобразования данных в компактной и легко читаемой форме. Например, задача фильтрации, группировки и агрегации данных может быть выполнена в одной строке кода: df.filter(pl.col('Traffic_Signal') == True).groupby('State').agg(pl.count('ID')). Это значительно упрощает восприятие и повторное использование кода, особенно в проектах с большим количеством этапов обработки данных.
Несмотря на свои преимущества, Polars не всегда является универсальным решением. Например, pandas остается предпочтительным выбором для работы с временными рядами и категориальными данными благодаря глубокой интеграции с экосистемой Python, включая библиотеки визуализации и машинного обучения. Работа с временными интервалами или вложенными структурами в Polars может потребовать дополнительных усилий, что делает pandas более подходящим для определенных задач.
Интеграция Polars с экосистемой Python: Совместимость, Ограничения и Практические Рекомендации
Такая интеграция значительно упрощает использование Polars в существующих рабочих процессах анализа данных, предоставляя пользователям возможность визуализировать большие объемы информации с минимальными затратами ресурсов.Введение в интеграцию Polars с экосистемой Python демонстрирует значительные преимущества этой библиотеки для работы с большими данными. Благодаря использованию Apache Arrow в качестве основы для внутреннего представления данных, Polars обеспечивает высокую производительность и эффективную интеграцию с ключевыми инструментами Python. Однако существуют определенные ограничения, особенно в области обработки разреженных данных, что требует детального рассмотрения при выборе между Polars и альтернативными решениями, такими как pandas7. Одним из ключевых аспектов интеграции является совместимость Polars с популярными библиотеками визуализации. Например, библиотека Narwhals предоставляет универсальный интерфейс для работы с различными DataFrame-системами, включая Polars, Pandas и Modin. Это позволяет использовать Polars непосредственно с такими инструментами визуализации, как Plotly и Altair, без необходимости конвертации данных. В предстоящем выпуске Plotly v6 добавлена поддержка Narwhals, что делает Polars практически родным форматом для этой библиотеки.
Интеграция Polars с системами машинного обучения, такими как Scikit-learn и TensorFlow, также заслуживает внимания. В Scikit-learn версии 1.4+ Polars поддерживается во всех трансформерах, а функция set_output позволяет сохранять формат Polars при выводе данных. Однако не все функции Scikit-learn используют преимущества Polars в полной мере из-за внутренних ограничений, связанных с копированием данных. Например, Pipeline пока не полностью оптимизирован для работы с Polars, что может привести к снижению производительности в задачах машинного обучения, где требуется минимизация накладных расходов. Кроме того, Polars не поддерживает разреженные данные, что ограничивает его применимость в сценариях, связанных с категориальными данными и one-hot-encoding. Разработчики Polars намеренно избегают добавления специфических функций для разреженных массивов, чтобы сохранить простоту и производительность библиотеки6. Этот подход контрастирует с pandas, который предлагает более широкий набор функциональностей за счет снижения производительности. Для преодоления ограничений, связанных с разреженными данными, Polars предлагает использование типа данных pl.UInt8 в методе to_dummies, что является более эффективным решением для представления значений 0 и 1 по сравнению с pl.Boolean. Это связано с тем, что машинное обучение обычно работает с uint8, что исключает необходимость дополнительного копирования данных. Данное решение демонстрирует компромисс между оптимизацией памяти и совместимостью с численными библиотеками, такими как TensorFlow или PyTorch.
Конвертация DataFrame между Polars и pandas через Apache Arrow представляет собой еще один важный аспект интеграции. Использование Arrow Table позволяет минимизировать накладные расходы за счет zero-copy reads, что особенно важно при работе с объемными данными. Например, преобразование между pandas и Polars через Arrow Table значительно снижает нагрузку на систему, что делает этот подход предпочтительным для задач, требующих высокой производительности. Однако стоит отметить, что такие преобразования могут быть неэффективны для очень больших датасетов из-за дополнительного использования памяти. Поларс также демонстрирует значительный потенциал для задач анализа данных в облачных сервисах. Несмотря на отсутствие конкретной информации об интеграции с Google Colab или AWS SageMaker, его архитектура, основанная на ленивых вычислениях и многопоточности, делает его подходящим выбором для обработки больших объемов данных в облачной среде. Например, Polars успешно справляется с обработкой файла размером 50 ГБ, который может распаковываться до 150–200 ГБ в оперативной памяти, без сбоев. Это выгодно отличает его от pandas, где большие объемы данных часто приводят к ошибкам памяти.
.На основе вышеизложенного можно предложить несколько практических рекомендаций по использованию Polars в реальных рабочих процессах. Во-первых, следует оценить характер данных и задачи проекта. Если работа с разреженными данными критична, переход на Polars может быть нецелесообразным. Во-вторых, для задач бизнес-аналитики (BI) и A/B-тестирования, где требуется высокая скорость обработки данных, Polars может стать оптимальным выбором. В-третьих, использование Apache Arrow для конвертации данных между Polars и pandas позволит минимизировать накладные расходы и повысить эффективность рабочих процессов. Наконец, стоит учитывать, что переход с pandas на Polars связан с изучением нового синтаксиса, основанного на выражениях, что может показаться сложным для новичков. Однако этот подход обеспечивает большую гибкость и упрощает создание повторно используемых конвейеров обработки данных.
Сравнение Polars и pandas: когда стоит переходить на Polars
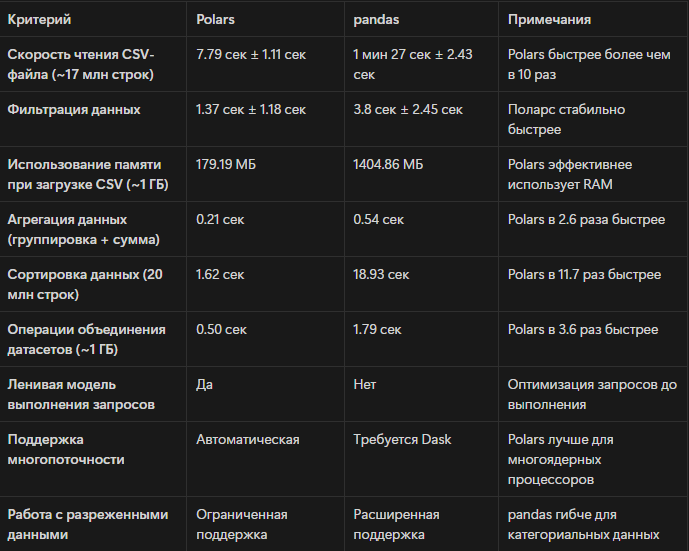
В таблице ниже представлено сравнение ключевых аспектов производительности и функциональности Polars и pandas. Эти данные помогают понять, в каких случаях переход на Polars целесообразен.
Заключение
Эти характеристики делают Polars идеальным выбором для проектов, где критичны скорость выполнения и использование аппаратных ресурсов.На основе проведенного анализа, Polars демонстрирует значительные преимущества перед pandas в задачах обработки больших данных, особенно в операциях чтения, фильтрации, группировки и агрегации. Его архитектура, основанная на Rust, Apache Arrow и автоматической многопоточности, позволяет достичь существенного улучшения производительности и эффективного использования памяти. Например, при работе с датасетами объемом более 1 ГБ Polars показывает скорость чтения в 16,4 раза выше, чем pandas, и потребляет вдвое меньше RAM12
Таким образом, выбор между pandas и Polars должен основываться на конкретных требованиях проекта, характеристиках данных и доступных аппаратных ресурсах.Тем не менее, pandas остается актуальным решением для задач, требующих работы с временными рядами, категориальными данными и разреженными массивами. Его зрелая экосистема и глубокая интеграция с инструментами Python обеспечивают гибкость и удобство использования, что особенно важно для небольших датасетов или проектов с ограниченными вычислительными ресурсами
Версию с кейсами из FinTech, E-commerce и SaaS (+шаблоны SQL/Python) вы найдёте в моём Telegram-канале @SeniorDataAnalyst.
#АналитикаДанных #Карьера #DataScience #Продуктивность #Обучение