Всем привет! Я — практикующий исследователь данных, и на этом канале делюсь тем, что реально работает в IT. Никакой сухой теории, только личный опыт, рабочие инструменты и грабли, на которые я уже наступил за вас. Рад, что вы здесь!
Скажу честно, я когда пришел в аналитику данных я не учил статистику, конечно у меня была какая-то база с универа, но к тому времени уже прошло более 10 лет и многое позабылось. Но со временем я, следуя здравому смыслу начал углубляться в статистику, первым делом я прочитал книгу, кстати реально крутую и получилось очень быстро, буквально за неделю. Книга "Голая статистика", автор Чарльз Уиллан (на очень простом языке, для новичков, в стиле "просто о сложном").
Впоследствие стало ясно, что статистика — это буквально как GPS для аналитика данных: без неё ты просто тыкаешься в датасет и надеешься на удачу (конечно некоторые вещи делаешь на автомате, но физический смысл методов понимать очень полезно). За годы работы я понял, что без базовых статконцепций не вытащить инсайты, не построить модель и не убедить бизнес, что ты не просто "графики рисуешь". В этой статье я разберу ключевые концепции статистики, которые реально нужны аналитикам, покажу, как их применять, и поделюсь лайфхаками, кстати которые часто пригождаются на собеседованиях.
Почему статистика — база
Статистика даёт тебе язык, чтобы объяснить, что твои выводы не случайны, и инструменты, чтобы копать глубже. Без неё ты не отличишь сигнал от шума. Да и в целом в нем много ключевых слов и понятий которые часто применяют не только аналитики данных, но и маркетологи, продуктовые аналитики, бизнес аналитики и не только. С базой по Статистике можно здорово облегчить себе жизнь и лучше понимать коллег по цеху.
Основные концепции и как их использовать
1. Описательная статистика: что твои данные пытаются сказать
Описательная статистика — это база: среднее, медиана, мода, дисперсия, стандартное отклонение. Они помогают понять, что за зверь твой датасет.
- Пример кода, с помощью Python можем быстро глянуть базовые метрики:
import pandas as pd
import numpy as np
df = pd.read_csv('sales_data.csv')
print(df['revenue'].describe()) # Среднее, медиана, мин, макс
print(f"Дисперсия: {np.var(df['revenue'])}")
print(f"Стандартное отклонение: {np.std(df['revenue'])}")
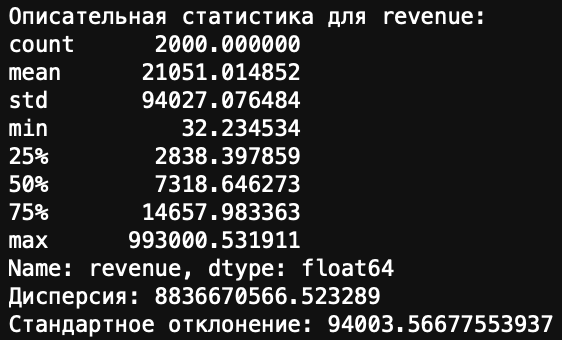
- Применение:
Если средний чек 10 000 рублей, а медиана 2 000 — у тебя куча мелких заказов и пара огромных. Это уже инсайт: возможно, VIP-клиенты тянут среднее. Дисперсия и стандартное отклонение покажут, насколько данные разбросаны. Если разброс огромный, жди выбросы. - Лайфхак: На собесе часто спрашивают, чем медиана отличается от среднего. Отвечай: "Медиана устойчива к выбросам, а среднее — нет". И добавь пример, как выше (чтобы лучше понимать медиану: если построить все данные в ряд по возрастанию, медианное значение окажется ровно посреди ряда: половина остальных значений меньше, половина больше. Со средним думаю всё понятно).
2. Распределения: как данные себя ведут
Распределение данных — это их "характер". Самое известное — нормальное распределение, но в реальной жизни данные часто скошены (например, доходы или время на сайте).
- Пример кода:
import seaborn as sns
import matplotlib.pyplot as plt
sns.histplot(df['revenue'], kde=True)
plt.title('Распределение выручки')
plt.show()
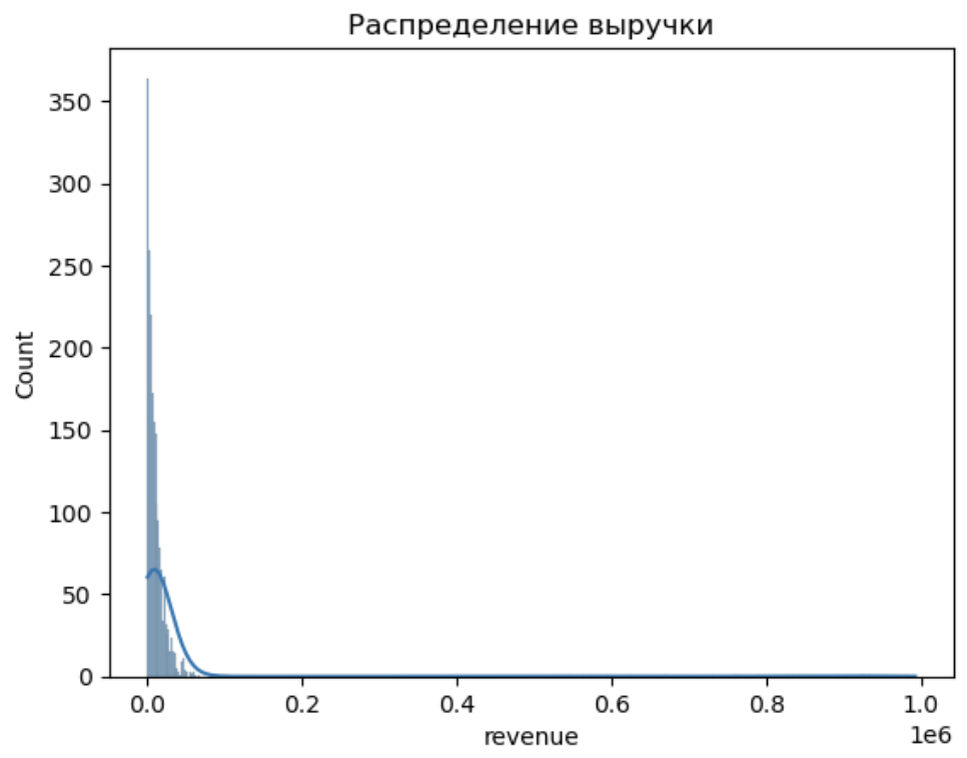
- Применение:
Если распределение нормальное, можно использовать t-тесты или ANOVA. Если скошенное — лучше непараметрические тесты (например, тест Манна-Уитни). Для A/B-теста я проверяю распределение метрик: если оно не нормальное, стандартные тесты могут врать. - Лайфхак: Нарисуй гистограмму с KDE (как выше) перед любым тестом. Если график похож на колокол — нормальное, если хвосты длинные — копай глубже.
3. Гипотезы и p-value: доказываем, что мы не угадали
Проверка гипотез — это сердце статистики. Ты ставишь нулевую гипотезу (H0, типа "разницы нет") и альтернативную (H1, "разница есть"), а потом считаешь p-value, чтобы понять, насколько твой результат случайный.
- Пример кода:
from scipy.stats import ttest_ind
# A/B-тест: контрольная и тестовая группы
control = df[df['group'] == 'control']['revenue']
test = df[df['group'] == 'test']['revenue']
stat, p_value = ttest_ind(control, test)
print(f"p-value: {p_value}")
if p_value < 0.05:
print("Есть значимая разница!")
# Пример вывода: "p-value: 0.07623541984643233"
- Применение:
Допустим, ты тестируешь новую кнопку на сайте. Если p-value < 0.05, ты с 95% уверенностью говоришь: "Новая кнопка работает лучше". Но если p-value 0.07 (как в нашем примере) — разница, скорее всего, случайна (но стоит убедиться на других данных более полных данных). - Лайфхак: На собесе могут спросить: "Что если p-value = 0.06?" Отвечай: "Не отвергаем H0, но результат близкий, стоит собрать больше данных".
4. Корреляция: кто с кем дружит
Корреляция показывает, как связаны переменные. Коэффициент Пирсона (-1 до 1) — для линейных связей, Спирмена — для нелинейных.
- Пример кода:
corr = df[['revenue', 'quantity']].corr(method='pearson')
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('Корреляция')
plt.show()
- Применение:
Если корреляция между revenue и quantity 0.9, больше товаров = больше выручки. Но если корреляция 0.1 — связь слабая. Я однажды нашёл корреляцию между временем на сайте и конверсией — это помогло бизнесу пушить длинные сессии. - Лайфхак: Корреляция ≠ причинность. Если продажи и температура воздуха коррелируют, это не значит, что жара продаёт товары (хотя мороженщики могут не согласиться и еще пару человек 🥲, но не всегда всё идеально). Копай глубже.
5. Центральная предельная теорема: почему всё становится нормальным
Центральная предельная теорема (ЦПТ) гласит: если взять много выборок, их средние будут нормально распределены, даже если исходные данные — хаос.
- Применение:
ЦПТ спасает, когда данные не нормальные, но выборка большая. Например, в A/B-тесте средние конверсии групп будут нормальными, если n > 30. Это позволяет использовать t-тесты. - Лайфхак: На собесе могут спросить: "Когда ЦПТ работает?" Отвечай: "При больших выборках (n > 30) и независимых наблюдениях".
6. Выбросы: друг или враг
Выбросы — это аномалии в данных, которые могут всё испортить. Их находят через IQR (межквартильный размах) или z-score.
- Пример кода:
Q1 = df['revenue'].quantile(0.25)
Q3 = df['revenue'].quantile(0.75)
IQR = Q3 - Q1
outliers = df[(df['revenue'] < Q1 - 1.5 * IQR) | (df['revenue'] > Q3 + 1.5 * IQR)]
print(f"Выбросы: {len(outliers)} строк")
# Пример вывода: "Выбросы: 501 строк"
- Применение:
Если в продажах есть заказ на 999999 рублей при среднем чеке 5000, это выброс. Я проверяю: баг это или реальный VIP-заказ. Удалять выбросы бездумно — ошибка. Однажды я сохранил такие "аномалии" — оказалось, это ключевые клиенты. - Лайфхак: Перед удалением выбросов спроси бизнес: "Это баг или реальная сделка?" Это покажет твой подход.
Типичные грабли и как их избежать
- Игнор p-value. Однажды я обрадовался что произошел "рост конверсии", а p-value был 0.3. Всегда проверяй значимость.
- Слепое доверие нормальности. Если данные скошены, t-тест врёт. Проверяй распределение.
- Удаление выбросов без проверки. Это может убить важные данные.
- Корреляция как причинность. Не говори "X вызывает Y" без доказательств.
- Забыл документировать. Записывай выводы: "p-value = 0.04, отвергаем H0" — это спасёт на презентации.
Лайфхаки для аналитиков
- Рисуй графики. Визуализация (гистограммы, боксплоты) помогает быстрее понять данные.
- Учи собес-вопросы. Типичные: "Что такое p-value?", "Когда использовать непараметрические тесты?", "Объясни ЦПТ".
Итоги
Статистика — это не просто формулы, а билет к инсайтам и доверию бизнеса. Описательная статистика даёт картину, распределения показывают характер данных, гипотезы доказывают выводы, корреляции находят связи, ЦПТ спасает тесты, а выбросы учат копать глубже. Освой эти концепции, и ты будешь не просто аналитиком, а рок-звездой данных. 🥲
Я не претендую на истину в последней инстанции, просто рассказываю, как иду по пути аналитика. Спасибо, что дочитали! 😎 Подписывайтесь 👇👇👇, лайкайте 👍🏽👍🏽, пишите в комментах пожелания, вопросы, замечания. Буду рад любой активности. Впереди разборы инструментов, навыков и IT-фишек!