В мире разработки программного обеспечения постоянно появляются новые подходы к построению систем. Event-Driven архитектура выступает одним из наиболее перспективных решений для создания гибких и масштабируемых приложений.
В этой статье мы расскажем о реализации Event-Driven архитектуры (EDA) с использованием FastAPI и паттерна Publish/Subscribe. Рассмотрим основные концепции, компоненты и практические примеры кода для создания масштабируемой системы обмена сообщениями.
Что такое Event-Driven архитектура (EDA)?
Event-Driven архитектура (EDA) — это архитектурный стиль, в котором компоненты системы взаимодействуют путем генерации, обнаружения и обработки событий. Событие — это значимое изменение состояния, о котором оповещаются все заинтересованные компоненты. Этот подход позволяет создавать слабосвязанные системы, где компоненты могут развиваться независимо друг от друга.
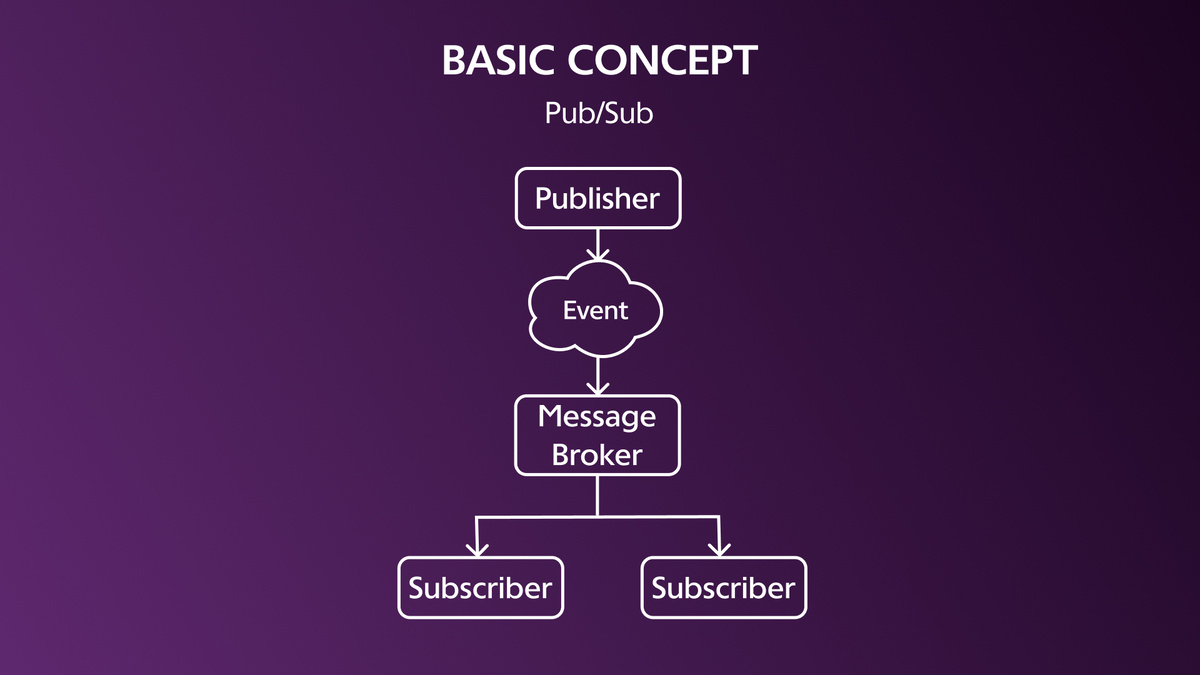
Главный принцип Pub/Sub заключается в разделении отправителей сообщений (издателей) и получателей (подписчиков), что позволяет им взаимодействовать без прямой зависимости друг от друга. Основные сущности:
Издатель (Publisher) — источник сообщений, который:
- Формирует сообщения определенного формата
- Публикует их в одну или несколько тем/каналов
- Не имеет информации о том, кто получит сообщения
- Не ожидает ответа от получателей
- Может быть любым компонентом системы, генерирующим события или данные
Подписчик (Subscriber) — получатель сообщений, который:
- Выражает интерес к конкретным темам через механизм подписки
- Получает сообщения только из тем, на которые подписан
- Обрабатывает сообщения по мере их поступления
- Может динамически подписываться и отписываться от тем
- Может фильтровать получаемые сообщения по дополнительным критериям
Брокер сообщений (Message Broker) — ключевой посредник, который:
- Обеспечивает инфраструктуру для передачи сообщений
- Хранит информацию о подписках
- Управляет темами/каналами сообщений
- Выполняет маршрутизацию сообщений от издателей к соответствующим подписчикам
- Может обеспечивать надежность доставки (гарантии доставки сообщений)
- Часто включает механизмы буферизации сообщений при временной недоступности подписчиков
Тема (Topic) / Канал (Channel) — именованный канал для категоризации сообщений:
- Представляет логическую категорию или группу сообщений
- Служит фильтром при доставке: подписчики получают сообщения только из выбранных тем
- Может иметь иерархическую структуру (например, "orders/new", "orders/processed")
- Может поддерживать фильтрацию по шаблонам (например, "orders/*")
Сообщение (Message) — единица передачи информации:
- Содержит полезную нагрузку (payload)
- Может включать метаданные (временные метки, идентификаторы, заголовки)
- Имеет определенную структуру и формат (JSON, XML, бинарный и т.д.)
- Может содержать информацию о приоритете или времени жизни
Где применяется (микросервисы, аналитика, IoT)
Микросервисы: EDA является фундаментальным подходом в архитектуре микросервисов, позволяя сервисам взаимодействовать через события, а не через прямые вызовы API. Это усиливает автономность сервисов и помогает избежать каскадных отказов. Технологии, такие как Kafka, RabbitMQ и NATS, часто используются для реализации EDA в микросервисных архитектурах.
Аналитика и обработка данных: В аналитических системах EDA позволяет обрабатывать потоки данных в реальном времени. Это особенно полезно для мониторинга бизнес-событий, обнаружения аномалий и создания динамических дашбордов. Системы, такие как Apache Flink, Apache Spark Streaming и Elasticsearch, часто применяются в таких решениях.
Интернет вещей (IoT): В IoT-системах множество устройств генерируют постоянный поток событий, которые нужно обрабатывать и анализировать. EDA идеально подходит для обработки этих событий, позволяя системе масштабироваться до миллионов устройств. Платформы, такие как AWS IoT, Azure IoT Hub и Google Cloud IoT, используют принципы EDA для обработки данных IoT.
Другие области применения:
- Финансовые системы (обработка транзакций, обнаружение мошенничества)
- Электронная коммерция (обработка заказов, управление инвентарем)
- Игровые платформы (взаимодействие игроков, обновление состояния игры)
- Системы мониторинга и оповещения
EDA становится все более распространенной по мере того, как компании стремятся создавать более масштабируемые, гибкие и отказоустойчивые системы.
Альтернативы Kafka: когда выбрать RabbitMQ или NATS?
При построении Event-Driven архитектуры (EDA) выбор брокера сообщений имеет критическое значение. Хотя Apache Kafka часто становится стандартным выбором, существуют ситуации, когда RabbitMQ или NATS могут быть более подходящими альтернативами. Каждое решение имеет уникальные характеристики, которые делают его оптимальным для определенных сценариев.
Сравнение брокеров сообщений
Три основных брокера сообщений — Kafka, RabbitMQ и NATS — обладают различными архитектурными подходами и моделями доставки сообщений.
Apache Kafka изначально разрабатывался как распределенный журнал коммитов, ориентированный на высокую пропускную способность и долговременное хранение данных. Он использует модель "публикация-подписка" с разделенными на партиции топиками.
RabbitMQ — более традиционный брокер сообщений, поддерживающий различные шаблоны обмена сообщениями через концепцию обменников (exchanges) и очередей. Он следует спецификации AMQP и предлагает гибкие возможности маршрутизации.
NATS — это легковесная система обмена сообщениями, ориентированная на простоту и скорость. Предлагает как классическую модель "запрос-ответ", так и потоковую передачу данных через NATS Streaming (или JetStream в новых версиях).
Характеристика: Модель сообщений
- Kafka: Журнал событий с партициями
- RabbitMQ: Обменники и очереди
- NATS: Публикация-подписка и запрос-ответ
Характеристика: Хранение данных
- Kafka: Долговременное, распределенное
- RabbitMQ: Временное (в памяти или на диске)
- NATS: В памяти (JetStream для хранения)
Характеристика: Пропускная способность
- Kafka: Очень высокая (100K+ сообщений/сек)
- RabbitMQ: Средняя (10-20K сообщений/сек)
- NATS: Высокая (до миллионов сообщений/сек)
Характеристика: Латентность
- Kafka: Низкая до средней (мс)
- RabbitMQ: Низкая (мс)
- NATS: Очень низкая (мкс)
Характеристика: Гарантии доставки
- Kafka: Точно один раз, минимум один раз
- RabbitMQ: Минимум один раз, точно один раз
- NATS: Минимум один раз (гарантии в JetStream)
Характеристика: Сложность настройки
- Kafka: Высокая
- RabbitMQ: Средняя
- NATS: Низкая
Характеристика: Потребление ресурсов
- Kafka: Высокое
- RabbitMQ: Среднее
- NATS: Низкое
Плюсы и минусы каждого решения
Apache Kafka отлично справляется с большими объемами данных и обеспечивает надежные потоки событий с высокой пропускной способностью. Его главное преимущество — долговременное хранение исторических данных, что делает его идеальным для аналитических систем и корпоративных шин событий. Однако Kafka требует значительных вычислительных ресурсов и имеет сложную архитектуру, увеличивая затраты на внедрение и обслуживание. Для простых сценариев обмена сообщениями это решение может быть избыточным.
RabbitMQ выделяется гибкостью и низким порогом входа. Этот брокер поддерживает различные паттерны обмена сообщениями и легко интегрируется с разными системами благодаря поддержке множества протоколов. Хорошо подходит для микросервисных архитектур с умеренной нагрузкой. Слабые стороны: ограниченные возможности хранения исторических данных, потенциальные проблемы производительности при высоких нагрузках и риск потери сообщений при сбоях без дополнительной настройки.
NATS привлекает простотой и минимальными требованиями к ресурсам. Обеспечивает самую низкую латентность, что делает его идеальным для обработки сообщений в реальном времени. Хорошо работает в системах с множеством микросервисов и в облачных средах. Однако базовый NATS предлагает ограниченные гарантии доставки и не имеет встроенных механизмов долговременного хранения сообщений. Экосистема инструментов вокруг NATS менее развита по сравнению с другими решениями.
Когда выбирать каждое решение
Выбирайте Kafka, когда:
- Необходимо обрабатывать большие объемы данных (Big Data)
- Важно долговременное хранение и воспроизведение событий
- Нужны гарантии порядка сообщений и обработки ровно один раз
- Разрабатываете систему аналитики в реальном времени или IoT-платформу
Выбирайте RabbitMQ, когда:
- Требуется сложная маршрутизация сообщений
- Важна поддержка различных протоколов обмена сообщениями
- Работаете с микросервисами среднего масштаба
- Нужен простой и быстрый запуск системы обмена сообщениями
Выбирайте NATS, когда:
- Критична сверхнизкая латентность (реал-тайм системы)
- Необходима простота развертывания и обслуживания
- Ограничены ресурсы инфраструктуры
- Создаете систему микросервисов с преобладанием паттерна запрос-ответ
В современных распределенных системах нередко используется комбинация различных брокеров для решения разных задач в рамках единой архитектуры.
Реализация Pub/Sub-архитектуры на примере сервиса по обработке заказов
В ходе этой статьи мы разработаем простую систему заказов. При создании заказа пользователи, подписанные на рассылку, должны получить уведомление по email о том, что заказ создан. Соответственно, у нас будет два сервиса:
- orders - отвечает за создание заказов и отправку отправку события (event)
- notifications - отвечает за возможность подписаться на определенные события и обработку сообщений о создании заказа.
Основные компоненты:
- FastAPI — основной web-сервер, на нем будут реализованы наши сервисы
- Kafka брокер — распределённая платформа потоковой обработки событий
- PostgreSQL - база данных для хранения заказов и подписок пользователей
- Pydantic модели — описание структуры событий
Разработка Publisher (FastAPI) — отправка событий
В качестве фреймворка был выбран fast api. Он идеально подходит для разработки микросервисов, за счет своей простоты, скорости и асинхронности. В основе структуры проекта используется слоистая архитектура, которая предполагает разбиение приложение на слои и внедрение зависимостей, где каждый внешний слой ничего не знает о внутреннем. Основные слои это:
- Router (Контроллеры / Веб-слой): обработка HTTP-запросов и ответов.
- Service (Бизнес-логика): основная логика приложения (без привязки к API или БД).
- Repository (Доступ к данным): работа с базой данных или другим хранилищем.
Нам необходимо создать следующую структуру проекта:
alembic
- Миграции базы данных.
- alembic.ini — конфигурационный файл Alembic для работы с миграциями.
api
- Слой представления (presentation layer) — маршруты FastAPI.
- v1/ — версия API (позволяет в будущем легко поддерживать разные версии).
- orders.py — роуты для работы с заказами.
db
- Работа с базой данных.
- db.py — инициализация подключения к базе данных.
events
- Работа с событиями в рамках паттерна Pub/Sub.
- create_topics.py — создание топиков Kafka.
- kafka_topics.py — описание топиков Kafka.
- publisher.py — логика публикации событий (паблишер Kafka).
- schemas.py — схемы для сообщений, которые отправляются через Kafka.
models
- Модели базы данных (ORM модели).
- orders.py — модель заказа.
repositories
- Репозитории — слой доступа к данным.
- abc_repositories.py — абстрактные классы репозиториев (интерфейсы).
- orders_repository.py — конкретная реализация репозитория заказов.
schemas
- Pydantic-схемы для валидации входных и выходных данных API.
- order.py — схемы для работы с заказами.
services
- Бизнес-логика приложения.
- orders_service.py — сервисный слой для обработки заказов.
В этой статье мы не будем подробно останавливаться на этапах реализации всех слоёв приложения, так как нас интересует взаимодействие с брокером. В качестве брокера используется Apache Kafka — мощная платформа для реализации Event-Driven Architecture, которая обеспечивает надёжную передачу, хранение и обработку событий. Правильная настройка Kafka критически важна для построения масштабируемой и отказоустойчивой системы. В этом разделе мы рассмотрим ключевые аспекты конфигурации Kafka для эффективной работы с событиями в EDA.
Данный брокер поддерживает 3 политки гарантий доставки сообщений:
Гарантии доставки сообщений
Тип гарантии: At Most Once
- Описание: Сообщение доставляется не более одного раза. Возможна потеря данных.
- Преимущества: Низкая задержка, высокая пропускная способность.
- Недостатки: Риск потери сообщений.
Тип гарантии: At Least Once
- Описание: Сообщение доставляется как минимум один раз. Возможны дубликаты.
- Преимущества: Надежность, отсутствие потерь.
- Недостатки: Необходима обработка дубликатов.
Тип гарантии: Exactly Once
- Описание: Сообщение доставляется ровно один раз. Ни потерь, ни дубликатов.
- Преимущества: Максимальная надежность.
- Недостатки: Высокие накладные расходы.
Для различных задач могут быть использованы разные семантики доставки. Как правило, золотой серединой является At Least Once — он обеспечивает баланс между надежностью и производительностью. Для критических систем, например платежей, рекомендуется использовать Exactly Once.
Политика Exactly Once достигается за счет:
- Идемпотентности продюсера (enable.idempotence=true) – предотвращает дубли при отправке.
- Транзакционной моделью между Producer и Consumer (isolation.level=read_committed).
Перед запуском приложения нам необходимо убедиться, что созданы топики — это категории или потоки сообщений, к которым публикуются данные. Каждое событие относится к определённому топику (подобно таблицам в базе данных или очередям в системах обмена сообщениями).
Кроме того, у каждого топика есть партиции — это единицы параллелизма в Kafka, которые позволяют распределять обработку данных между несколькими потребителями.
Если нужные топики отсутствуют, их нужно создать. В нашем случае мы будем использовать скрипт, который будет запускаться при старте приложения. Обратите внимание, что это демонстрационный пример: в промышленной эксплуатации, как правило, для этого применяются инструменты автоматизации инфраструктуры, такие как Terraform, Ansible и другие.
Код реализующий создание топиков:
1) num_partitions (число разделов) - Этот параметр указывает, сколько разделов (partitions) будет у топика. Каждый раздел является независимым логическим блоком, в который записываются данные. Количество разделов влияет на параллельность обработки сообщений (больше разделов — больше параллельных потоков для записи и чтения). Однако чем больше разделов, тем сложнее управление топиком, так как увеличивается нагрузка на брокеры.
2) replication_factor (фактор репликации) - Этот параметр указывает, сколько копий данных в топике будет храниться на различных брокерах Kafka. Обычно, чем выше репликация, тем выше доступность и отказоустойчивость. В данном демонстрационном примере указано 1. В продакшн системах рекомендуется указывать минимум 3 реплики.
Правила именования топиков
При проектировании EDA важно следовать согласованным правилам именования:
1) Доменно-ориентированные имена:
- <домен>.<сущность>.<действие>
(пример: user.profile.updated)
- <микросервис>.<сущность>.<событие>
(пример: payment-service.transaction.completed)
2) Соглашения по форматированию:
- Используйте kebab-case (user-events) или точечную нотацию (user.events)
- Поддерживайте согласованность во всей системе
Реализация producer
Далее реализуем producer, который будет отвечать за отправку сообщений при создании заявки.
В данном случае при инициализации продюсера используется параметр acks=1, что обеспечивает политику доставки At Least Once. При такой настройке продюсер будет ожидать от брокера подтверждения о записи на диск одного брокера. Это гарантирует доставку как минимум один раз.
Если бы нам потребовалось ужесточить политику доставки, то необходимо:
1. Включить параметр: enable_idempotence=True и acks=’all’
2. При отправки сообщений использовать транзакции:
Теперь мы можем добавить в сервисный слой зависимость и реализовать отправку эвента при создании заявки:
Разработка Subscriber (Consumer) — обработка событий
Теперь необходимо реализовать сервис, который будет отвечать за отправку уведомлений. Его основная возможность — дать пользователю подписаться на уведомления и обрабатывать эвенты при создании заявки. Структура проекта будет та же, что и у orders. Основное отличие заключается в том, что на стороне notifications будет консьюмер, который будет обрабатывать эвенты о создании заявки.
Для начала реализуем сервис, который будет отправлять уведомления:
Здесь мы получаем все электронные почты пользователей, которые оформили подписку на уведомления, и отправляем им email о том, что была создана заявка.
Теперь реализуем консьюмер, который будет обрабатывать эвенты:
Заключение: когда стоит внедрять Event-Driven архитектуру?
Паттерн Pub/Sub в связке с Kafka и FastAPI позволяет строить масштабируемые и слабосвязанные системы.
Ключевые плюсы:
- Минимальная зависимость компонентов.
- Простота масштабирования.
- Гибкость в обработке событий.
С правильным управлением топиками, грамотной организацией продюсеров и консьюмеров можно обеспечить высокую надёжность доставки сообщений даже в сложных продакшн-системах.
Ссылки на репозитории:
https://github.com/aarbatskov/orders-example
https://github.com/aarbatskov/notifications-example
FAQ: ответы на частые вопросы о Event-Driven и Kafka
1) Какие задачи лучше решает Kafka, а какие — RabbitMQ?
Kafka лучше подходит для:
- Обработки больших потоков данных с высокой пропускной способностью
- Долговременного хранения и воспроизведения событий
- Аналитических систем и работы с большими данными
- Корпоративных шин событий с множеством потребителей
RabbitMQ лучше справляется:
- Классическими задачами обмена сообщениями с умеренной нагрузкой
- Разнообразными паттернами маршрутизации сообщений
- Системами, требующими низкого порога входа и быстрого внедрения
- Проектами, где критична гибкость протоколов и форматов сообщений
2) Как обеспечить надежность доставки сообщений в Pub/Sub?
Надежность доставки в Pub/Sub обеспечивается следующими методами:
- Правильная настройка подтверждений доставки (acks=all для Kafka)
- Использование достаточного количества партиций и фактора репликации
- Внедрение идемпотентности обработки на стороне потребителей
- Правильная стратегия обработки ошибок с механизмами повторных попыток
- Мониторинг отставания консьюмеров и своевременное масштабирование
- Регулярное тестирование сценариев отказа частей системы