Сейчас разработчикам стало проще, чем когда-либо раньше, пользоваться возможностями искусственного интеллекта благодаря крупным языковым моделям вроде GPT-4 и GPT-3.5 Turbo от ChatGPT. Эти технологии открыли новую эпоху стремительного развития программного обеспечения. Благодаря усилиям OpenAI теперь каждый может легко создавать удивительные приложения — остаётся лишь придумать, что именно создать с имеющимися инструментами.
Эти модели искусственного интеллекта умеют гораздо больше, чем просто вести диалоги. Разработчики могут применять их способности понимать человеческий язык для создания приложений, распознающих желания пользователей и превращающих фантазии в реальные продукты. Новые инструменты позволяют программам воспринимать и обрабатывать даже изображения. Например, можно сделать умных помощников, которые постоянно учатся и приспосабливаются, или образовательные сервисы, учитывающие индивидуальные особенности каждого ученика. Языковые модели GPT открывают перед нами целую вселенную новых идей и решений.
Что же такое эти GPT-модели? Эта статья создана специально для того, чтобы объяснить вам их суть, историю появления и главные возможности. Когда вы поймёте основы этих технологий искусственного интеллекта, вы сможете уверенно разрабатывать новые поколения приложений, основанных на больших языковых моделях.
Эта статья познакомит вас с основными элементами, лежащими в основе разработки GPT-моделей. Вы узнаете всё необходимое о больших языковых моделях, обработке естественного языка, архитектуре трансформеров, разбиении текста на части и предсказании последующих элементов. Но дело не только в тексте! Появление GPT-4 Vision расширяет возможности этих моделей, позволяя им работать не только с текстом, но и с изображениями. Теперь GPT-4 способен не только читать тексты, но и понимать смысл картинок.
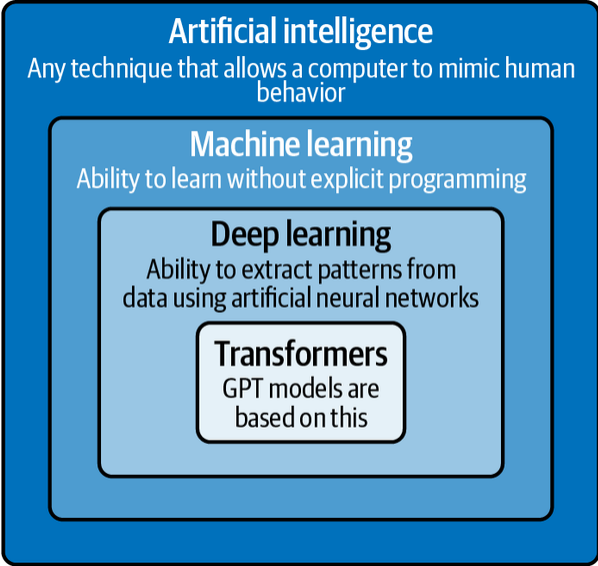
Для понимания GPT-моделей важно сначала познакомиться с основами обработки естественного языка (NLP), которая относится к сфере машинного обучения и искусственного интеллекта. Искусственный интеллект включает создание компьютерных систем, выполняющих задачи, традиционно требующие человеческого ума. Многие современные алгоритмы попадают под определение искусственного интеллекта. Например, программы, прогнозирующие трафик в навигаторе или принимающие решения в стратегиях видеоигр, воспринимаются людьми как обладающие интеллектом.
Машинное обучение (ML) — это часть искусственного интеллекта, где задача заключается не в написании конкретных правил поведения системы, а в создании алгоритмов, позволяющих ей учиться самостоятельно. Такие методы начали активно развиваться ещё с 1950-х годов. Среди них особенно выделяются алгоритмы глубокого обучения, вдохновленные структурой мозга. Их называют искусственными нейронными сетями. Они способны анализировать огромные объёмы данных и отлично справляются с задачами распознавания изображений, голоса и текста.
Модели GPT построены на основе архитектуры Transformers, впервые представленной в работе группы исследователей из Google в 2017 году. Трансформеры работают подобно устройствам чтения, применяя механизм внимания, позволяющий выделять важные фрагменты текста и лучше понимать контекст. За счёт этого они точнее определяют значения слов в предложениях, что делает их эффективными в задачах перевода, анализа текста и составления содержательных ответов. На иллюстрации 1.1 показано, как эти принципы помогают трансформерам справляться с разнообразными языковыми задачами.
Обработка естественного языка (NLP) — это направление искусственного интеллекта, целью которого является научить компьютеры понимать, интерпретировать и генерировать человеческую речь. Современные подходы к решению задач NLP основываются на методах машинного обучения (ML).
Основные направления применения NLP:
- Классификация текста: разделение текста на заранее определённые категории. Например, анализ настроения помогает компаниям определить отношение потребителей к своим услугам, а фильтрация писем сортирует входящие сообщения на личные, социальные, рекламные и спам.
- Автоматический перевод: перевод текста между разными языками, иногда даже перевод кода с одного языка программирования на другой (например, с Python на C++).
- Ответы на вопросы: получение нужных ответов на вопросы, исходя из предоставленного текста. Онлайн-сервисы поддержки клиентов часто используют такие модели для автоматической обработки запросов пользователей.
- Генерация текста: создание последовательного и значимого текста на основании вводных данных, называемых подсказками.
Большие языковые модели (LLM) — это разновидности моделей машинного обучения, предназначенные для генерации текста и выполнения связанных задач. Они позволяют компьютеру эффективно взаимодействовать с человеком, обрабатывая, понимая и создавая человеческий язык. Для достижения этого результата модели проходят обучение на огромных массивах текстовых данных, таких как Википедия, Reddit, архивы книг и даже сам Интернет. Во время обучения модели выявляют закономерности и связи между словами, чтобы впоследствии предсказывать следующие слова и формировать осмысленный ответ. Современные крупные языковые модели, такие как последние версии GPT, обладают огромным количеством внутренних параметров и способны непосредственно выполнять большинство задач обработки естественного языка, включая классификацию текста, машинный перевод и ответы на вопросы.
OpenAI разработал ряд языковых моделей, среди которых на сегодняшний день лидируют модели семейства GPT-4. Помимо стандартных функций обработки текста, GPT-4 Vision выделяется своей способностью работать с мультимодальными данными, принимая на входе не только текст, но и изображения. Интерпретация изображений осуществляется благодаря специальной архитектуре трансформера, известной как ViT (Vision Transformer). Последняя версия модели, GPT-4o, сделала очередной шаг вперед, научившись не только обрабатывать и генерировать текст и изображения, но и работать с аудиоданными.
Развитие крупных языковых моделей (LLMs) стартовало в 1990-е годы с простейших подходов, таких как n-граммы. Эти ранние модели пытались предсказать следующее слово в предложении, основываясь исключительно на частоте встречаемости предыдущего слова. Несмотря на успешное начало, они столкнулись с проблемами в понимании контекста и грамматической структуры предложений, приводящими к несогласованности в созданных ими текстах.
Затем появились более продвинутые подходы, такие как рекуррентные нейронные сети (RNNs) и сети с долгой краткосрочной памятью (LSTMs). Эти модели улучшили способность учитывать более длинные цепочки слов и контекст, но оставались ограничены в масштабировании на большие объемы данных. Тем не менее, RNNs и LSTMs длительное время считались наилучшими методами и широко применялись, например, в системах автоматического перевода.
Архитектура трансформера совершила настоящий прорыв в области обработки естественного языка (NLP), решив одну из главных проблем предшествующих моделей, таких как рекуррентные нейронные сети (RNNs). Предыдущие модели испытывали трудности с обработкой длинных последовательностей текста и сохранением контекста. А вот трансформеры смогли успешно справиться с этими задачами.
Основополагающим принципом успеха трансформеров стал механизм внимания. Он позволяет модели сосредоточиваться на наиболее важных словах в каждом конкретном контексте, делая прямую связь между отдалёнными частями текста. Таким образом, последняя фраза способна учесть влияние первой без потери смысла, чего не хватало предыдущим архитектурам типа RNNs.
Механизмы перекрестного внимания и само-внимания являются ключевыми компонентами архитектуры трансформера и повсеместно применяются в современных языковых моделях (LLMs). Именно использование этих блоков позволило значительно повысить качество обработки текста и вывести модели на принципиально новый уровень эффективности.
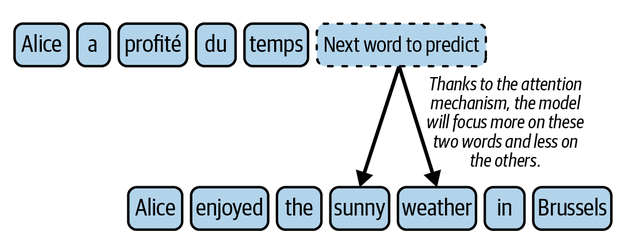
Перекрестное внимание позволяет модели выбирать самые значимые элементы исходного текста для правильного подбора следующего слова в переведённом предложении. Представьте это как фонарь, высвечивающий нужные слова и пропускающий неважные детали.
Перекрестное внимание позволяет модели выбирать самые значимые элементы исходного текста для правильного подбора следующего слова в переведённом предложении. Представьте это как фонарь, высвечивающий нужные слова и пропускающий неважные детали.
Например, возьмем фразу на английском: «Алиса наслаждалась солнечной погодой в Брюсселе», которую нужно перевести на французский («Alice a profité du beau temps à Bruxelles»). Если мы хотим правильно подобрать французское слово «ensoleillé» ("солнечная"), то перекрестное внимание обратит особое внимание на английские слова «sunny» ("солнечная") и «weather» ("погода"). Осознавая важность этих терминов, модель сможет точно воспроизвести соответствующий фрагмент перевода.
Самовнимание — это способность модели акцентировать своё внимание на разных элементах входящего текста. Применительно к обработке естественного языка (NLP), модель оценивает значимость каждого слова в предложении относительно остальных слов. Это позволяет ей выявить связи между словами и формировать новые понятия на основе комбинации нескольких слов.
Пример: в предложении «Алиса получила похвалу от своих коллег» модель должна понять значение слова «она». Самовнимание распределяет разные веса каждому слову, подчеркивая ключевые моменты. Здесь наибольший вес получат слова «Алиса» и «коллеги». Таким образом, модель формирует понятие «коллеги Алисы», показанное на схеме.
Преимущество трансформеров над рекуррентными архитектурами состоит в том, что они поддерживают параллельное выполнение операций. Это значит, что трансформеры могут одновременно обрабатывать сразу несколько частей входного текста, не ожидая завершения предыдущей операции. Такая особенность ускоряет вычисления и обучение модели, так как её составляющие могут функционировать независимо друг от друга.
Параллельная структура трансформеров прекрасно сочетается с особенностями графических процессоров (GPU), предназначенных для одновременного выполнения множества расчётов. GPU идеальны для обучения и эксплуатации трансформерных моделей благодаря их высокому уровню параллелизма и мощности вычислений. Это нововведение позволило аналитикам обучать модели на огромных наборах данных, заложив основу для появления больших языковых моделей (LLMs).
Transformer — это последовательность компонентов, изначально созданная для задач перевода, таких как машинный перевод. Типичный трансформер состоит из двух основных частей: кодировщика и декодера, обе из которых используют механизмы внимания.
Кодировщик занимается обработкой входного текста, извлечением полезных признаков и созданием осмысленных векторных представлений (встраиваний). Декодер принимает эти вложения и генерирует вывод, такой как перевод или резюме.
Предварительно обученные генеративные трансформеры, известные как GPT, основаны на архитектуре трансформера, но используют преимущественно его декодирующую часть. У GPT отсутствует кодировщик, поэтому нет нужды в кросс-внимании для объединения встроенной информации. В итоге GPT целиком зависит от механизма самовнимания в декодере для формирования представлений и прогнозов с учётом контекста.
Другие известные модели, такие как BERT, базируются на кодирующей части трансформера, однако в данной книге они не рассматриваются. Эволюция различных типов моделей представлена на рисунке 1.4.
Раскрываем тайну этапов токенизации и прогнозирования в моделях GPT
Как работает процесс генерации текста в LLM?
Большие языковые модели получают текстовую подсказку и создают на её основе продолжение. Этот процесс известен как завершение текста. Например, подсказка может звучать так: «Сегодня погода хорошая, поэтому я решил...», а модель продолжит её предложением «...выйти прогуляться».
Вы можете задаться вопросом, каким образом модель создаёт итоговый текст на основе введённой подсказки. Оказывается, это главным образом сводится к вопросам вероятности.
При поступлении подсказки в LLM, она разбивается на небольшие единицы, называемые токенами. Токены могут представлять отдельные слова, части слов, пробелы или знаки препинания. Например, приведённая выше подсказка может быть разобрана следующим образом: ["The", "wea", "ther", "is", "nice", "today", ",", "so", "I", "de", "ci", "ded", "to"].
Каждая языковая модель обладает собственным токенайзером. Так, токенайзер, используемый в сериях GPT-3.5 и GPT-4, доступен на платформе OpenAI для тестирования пользователями.
Полезный совет:
Обычно принято считать, что примерно каждые 100 токенов соответствуют около 75 словам на английском языке. Однако для других языков соотношение может отличаться, и количество токенов может оказаться большим для аналогичного числа слов.
Благодаря принципу внимания и архитектуре трансформера, большая языковая модель (LLM) обрабатывает токены и определяет связи между ними, учитывая общий смысл полученного запроса. Архитектура трансформера позволяет модели эффективно выявлять важную информацию и контекст внутри текста.
Для создания нового предложения LLM прогнозирует наиболее вероятные последующие токены, основываясь на контексте ввода, предоставленном пользователем. Изначально компания OpenAI предлагала выбор между двумя вариантами размера окна ввода: 8192 токена и 32768 токенов. К началу 2024 года последние модели GPT-4 Turbo и GPT-4o увеличили размер окна ввода до 128000 токенов, что эквивалентно почти трём сотням страниц английского текста. В отличие от прежних рекуррентных моделей, которые плохо справлялись с длинными последовательностями, архитектура трансформера с механизмом внимания позволяет современным LLM учитывать весь контекст. Основываясь на нём, модель присваивает вероятность каждому потенциальному следующему токену, выбирая тот, чья вероятность максимальна. В нашем примере после фразы «Сегодня погода хорошая, поэтому я решил...» следующий лучший токен мог бы быть словом «выйти».
Примечание:
В следующей статье мы узнаем, что с помощью параметра `temperature` можно настроить модель так, чтобы она выбирала следующий токен не строго по максимальной вероятности, а случайным образом из набора токенов с высокими вероятностями. Это позволяет увеличить вариативность и креативность ответов модели.
Далее процесс повторяется снова, но теперь контекст становится «Сегодня погода хорошая, поэтому я решил выйти», включающим предыдущий предсказанный токен «выйти». Следующий токен, выбранный моделью, может быть, например, «на». Процесс продолжается до тех пор, пока не формируется полное предложение: «Сегодня погода хорошая, поэтому я решил выйти на прогулку». Вся эта процедура основана на способности LLM изучать наиболее вероятные слова из огромного объёма текстовых данных. Процесс иллюстрируется на Рисунке 1.5.
Интеграция зрения в большие языковые модели
Версия GPT-4 Vision добавила мультимодальность в серию GPT-4, расширив её функциональность за пределы обычного текста. Конкретные технические подробности реализации этой функции остаются закрытыми, однако понимание принципов возможно через аналогичные проекты с открытым исходным кодом, интегрирующие визуальную информацию. Изучив процессы, наблюдаемые в открытых источниках, можно представить, как интеграция изображений и текста реализована в GPT-4.
Основные этапы интеграции визуального компонента
Традиционно основным инструментом для обработки изображений служили свёрточные нейронные сети (CNN). Они зарекомендовали себя как высокоэффективные в задачах классификации изображений и обнаружения объектов, используя фильтры, скользящие по пикселям изображения. Эти слои фильтров сохраняют пространственную структуру изображения, начиная с простого выделения границ на ранних слоях и заканчивая сложными объектами на глубоких уровнях.
Однако, как и появление архитектуры трансформеров в 2017 году радикально изменило ландшафт обработки естественного языка, вытеснив RNN, так и в 2020 году трансформеры стали применяться и для обработки изображений. Исследование Google, представленное в статье "An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale" (Dosovitskiy et al., 2021), показало, что чистый трансформерный подход, известный как Vision Transformer (ViT), превосходит традиционные CNN в ряде задач классификации изображений.
Таким образом, GPT-4 Vision скорее всего сочетает в себе мощь трансформерных сетей для эффективного извлечения семантики как из текста, так и из изображений, дополняя традиционные техники обработки визуальной информации глубокими возможностями, характерными для современных языковых моделей.
Эти патчи изображения объединяются с текстовыми токенами в единую последовательность ввода. Без излишнего погружения в техническую сторону вопроса отметим, что при обработке текстовых данных LLM вначале проектирует все токены в пространство высоких измерений. Иначе говоря, каждый токен превращается в многомерный вектор, а отображающая функция между токенами и векторами рассчитывается в процессе обучения самой модели.
Практически аналогичный процесс применяется и к участкам изображения. Рассчитанная во время обучения отображающая функция ставит в соответствие каждой фиксированной площади изображения элемент пространства той же высокой размерности. Таким образом, и токены, и патчи оказываются помещены в единое пространство высоких измерений.
Полученная комбинированная последовательность текста и изображения далее проходит через архитектуру трансформера для предсказания следующего токена. Возможность интегрировать визуальные патчи с текстовыми токенами в одном пространстве высоких измерений позволяет применить механизмы само-внимания одновременно для обоих видов данных, что даёт модели возможность выдавать ответы, учитывающие как текстовую, так и визуальную информацию.
Для программистов на Python это открывает огромное пространство для взаимодействия пользователей с вашими приложениями искусственного интеллекта, например, в виде интуитивных чат-ботов или образовательных инструментов, способных понимать и объяснять содержание изображений.