Представьте интернет-магазин: покупатель оформляет заказ, и дальше надо одновременно сообщить складу о снижении товара, бухгалтерии — о проведении оплаты, а службе доставки — о новом отправлении. Как все эти разные сервисы могут узнать о заказе, не вызывая напрямую друг друга? Здесь на помощь приходит брокер сообщений – своеобразный «почтовый узел» в мире программного обеспечения, который принимает сообщения от одних систем и передает их другим. В этой статье мы простым языком объясним, что такое брокер сообщений, какие они бывают (Kafka, RabbitMQ, Redis Streams, Amazon SQS и другие), чем они отличаются, и рассмотрим их особенности. Также сравним их по ключевым параметрам – производительность, надежность, простота использования и возможности для анализа данных – а в конце приведем типичные вопросы, которые могут задать на собеседовании по этой теме.
Что такое брокер сообщений?
Брокер сообщений – это программный посредник, который управляет обменом данными между разными приложениями или сервисами. Проще говоря, это центр связи: отправитель передает свои данные брокеру, а брокер уже отвечает за доставку этих данных получателю (или получателям). Благодаря этому приложения могут обмениваться информацией асинхронно (независимо по времени) и взаимонезависимо.
Представьте брокер сообщений как почтовое отделение. Отправитель (продюсер) опускает письмо (сообщение) в ящик – он не беспокоится, где сейчас получатель и готов ли он принять письмо. Почтовое отделение (брокер) получает все письма, сортирует их и хранит, если нужно, а затем раздает получателям (потребителям) когда они готовы забрать почту. Получатели могут прийти в удобное для них время – письмо будет их ждать. Такая система избавляет отправителей и получателей от необходимости быть на связи одновременно и знать подробности друг о друге.
Брокер сообщений повышает надежность и гибкость архитектуры: если получатель временно недоступен, сообщение не пропадет, а полежит в брокере; если отправителей или получателей несколько, брокер организует доставку всем нужным адресатам. Кроме того, брокер может преобразовать формат или протокол сообщения, проверять его и гарантировать, что оно рано или поздно будет доставлено.
Как работает брокер: очереди vs. публикация-подписка
Брокеры сообщений используют две основные модели доставки: очередь сообщений (point-to-point) и публикация/подписка (pub/sub). Рассмотрим их на простых схемах.
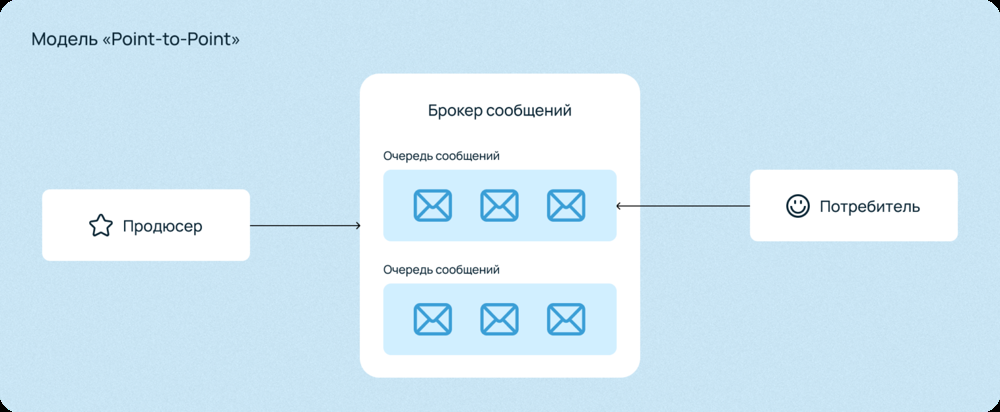
Модель «Point-to-Point» (точка-точка): один отправитель ставит сообщения в очередь брокера, откуда только один получатель их забирает. Каждое сообщение потребляется единожды одним получателем. В этой модели сообщение адресовано одному потребителю. Продюсер (например, сервис оплаты) отправляет данные транзакции в определенную очередь. Брокер хранит сообщения в порядке поступления (как в очереди за билетами) до тех пор, пока потребитель (скажем, сервис бухгалтерии) не заберёт их. Каждое сообщение будет обработано ровно одним получателем. Такой режим удобен для задач, где каждый элемент должен быть обработан один раз (например, выполнение задачи, обработка заказа одним сервисом). Если потребителей несколько, они обычно распределяют сообщения между собой (каждый следующий заказ возьмет следующий свободный сервис-потребитель).
Модель «Publish/Subscribe» (публикация-подписка): издатель публикует сообщение в определённую тему (топик), и каждый подписчик этой темы получает копию сообщения. Здесь продюсер не отправляет данные конкретному получателю, а скорее объявляет их в «эфир» на определённую тему. Все потребители, которые подписались на эту тему, получают сообщение. Например, сервис заказа в нашем интернет-магазине публикует событие «Новый заказ» в топик. Подписчиками на него могут быть склад, служба доставки, аналитический сервис – каждый получит уведомление о новом заказе и обработает его по-своему. Такой паттерн идеален для рассылки уведомлений, событий, логирования, когда одно и то же сообщение нужно доставить множеству систем.
Брокеры часто поддерживают оба паттерна. Например, RabbitMQ позволяет как выстраивать очереди (point-to-point), так и использовать обменники/топики для pub/sub. Kafka изначально строится вокруг модели публикация-подписка (темы с несколькими потребителями), но может реализовывать поведение очереди через группы потребителей (когда одна группа совместно читает тему, и каждое сообщение внутри группы получает только один член группы). Главное понимать: очередь гарантирует единичное потребление, топик – широковещательную доставку.
Популярные брокеры сообщений и их особенности
Существует множество брокеров сообщений. Рассмотрим несколько самых популярных, объясняя их особенности простыми словами и аналогиями.
Apache Kafka
Apache Kafka – это высокопроизводительный распределенный брокер сообщений, изначально разработанный в LinkedIn для работы с большими потоками данных. Если продолжить аналогию, Kafka – это скорее библиотека газет, нежели почтовый ящик. Каждое сообщение (как выпуск газеты) не исчезает после прочтения – Kafka хранит публикации в журналах (топиках) на диске. Подписчики могут не только получать новые сообщения, но и при необходимости «поднять архив» и перечитать старые, перематывая лог событий назад.
Основные черты Kafka:
- Журнал событий: Сообщения записываются последовательно в тему (лог), разделенную на разделы (partitions). Каждый сообщения имеет смещение (offset) – как номер страницы в журнале. Потребители сами отслеживают, до какого места дочитали.
- Высокая пропускная способность: Благодаря кластерной архитектуре Kafka умеет обрабатывать миллионы сообщений в секунду, масштабируясь горизонтально. Несколько брокеров Kafka работают вместе, разрезая потоки данных на части и обрабатывая параллельно.
- Хранение и репликация: Данные сохраняются на диск и могут реплицироваться на несколько узлов. Это как если бы каждая газета хранилась в нескольких библиотеках одновременно – потерять информацию трудно. История событий может храниться дни, недели и даже годы (по настроенному времени или объему).
- Использование: Kafka часто используют для аналитики и обработки потоков данных: сбор логов, телеметрия IoT-датчиков, трекинг действий пользователей, event sourcing в микросервисах. Там, где нужно и доставить данные быстро, и сохранить их для последующего анализа, Kafka подходит идеально.
Простыми словами: Kafka – это как черный ящик самолета: все события записываются подряд и надежно хранятся. Позже можно воспроизвести события сколько угодно раз, как воспроизведение пленки, и проанализировать их. В реальном времени Kafka раздает новые записи всем подписчикам, кто слушает соответствующую тему.
RabbitMQ
RabbitMQ – один из самых известных традиционных брокеров сообщений. Если Kafka – это библиотека журналов, то RabbitMQ похож на умного почтового диспетчера. Он получает сообщения и кладет их в очереди, но перед этим может по-разному их маршрутизировать: например, сделать копии в несколько очередей или отфильтровать по теме. RabbitMQ поддерживает протокол AMQP и изначально был разработан для надежной передачи сообщений в финансовых системах.
Особенности RabbitMQ:
- Гибкая маршрутизация: В RabbitMQ есть понятие обменников (exchange) – точек входа для сообщений. Обменник по правилам распределяет входящие сообщения по очередям. Есть разные типы обменников: директ (прямая маршрутизация по ключу), топик (по шаблону темы, как хэштеги), фанаут (рассылка во все очереди) и др. Это позволяет настроить сложные сценарии доставки. Например, одно сообщение о транзакции может одновременно пойти в очередь обработки платежа и в очередь логирования.
- Очереди и подтверждения: Сообщения хранятся в очередях до получения. RabbitMQ гарантирует доставку: получатель должен послать подтверждение (ACK), и лишь после этого сообщение удаляется из очереди. Если получатель упал, брокер передаст сообщение другому. Это обеспечивает надежность – задачи не потеряются.
- Протоколы и интеграция: Помимо AMQP, RabbitMQ поддерживает другие протоколы (MQTT, STOMP, даже HTTP через плагины), что делает его универсальным. Существуют готовые клиентские библиотеки практически для всех языков программирования, что упрощает интеграцию.
- Производительность: RabbitMQ способен обрабатывать десятки тысяч сообщений в секунду на одной ноде (при правильной настройке и использовании подтверждений/пакетов). Хотя по максимальной пропускной способности он уступает Kafka, для большинства веб-приложений его скорости достаточно.
- Использование: Часто RabbitMQ применяют в микросервисной архитектуре для координации задач: постановка заданий в очередь (например, отправка писем, обработка изображений), обмен событиями между сервисами, где не нужна долговременная сохранность каждой записи. Также он популярен там, где нужна сложная маршрутизация сообщений или совместимость с разными протоколами.
Простыми словами: RabbitMQ – это почтовый сортировщик. Он может по содержимому решить, в какой ящик (очередь) положить письмо, может разослать копии письма в несколько ящиков сразу. Каждое письмо будет выдано кому-то одному – тому, кто заберет из ящика первым. Если получатель не подтвердил получение, сортировщик передаст письмо другому. Эта система очень надежна для доставки и позволяет настроить разные правила распределения почты.
Redis Streams
Redis Streams – относительно новый механизм потоковых сообщений в сверхбыстрой базе данных Redis. Redis известен как in-memory хранилище (все данные хранятся в оперативной памяти для максимальной скорости), и Streams добавляет к нему функциональность брокера сообщений. Если сравнить с аналогиями, Redis Streams – это доска объявлений в офисе: на нее быстро наклеивают стикеры (сообщения) и несколько команд могут параллельно снимать эти стикеры для обработки.
Особенности Redis Streams:
- Встроено в Redis: Streams – это просто новый тип структуры данных Redis (как списки, множества и т.д.). Чтобы воспользоваться, достаточно запустить сервер Redis – дополнительного сложного ПО не нужно. Это удобно, если у компании уже есть Redis для кеша или сессий: можно использовать ту же инфраструктуру для очередей.
- Высокая скорость: Поскольку Redis работает в памяти, операции добавления и чтения сообщений происходят очень быстро – миллионы операций в секунду на обычном сервере под небольшими нагрузками. Это подходит для случаев, где нужна минимальная задержка между отправителем и получателем.
- Consumer Groups (группы потребителей): Redis Streams поддерживает группы потребителей, похожие на Kafka: несколько потребителей могут совместно читать один поток, и Redis обеспечит, что каждое сообщение из потока получит только один член группы. Это реализует модель очереди (point-to-point) при необходимости распределить работу между несколькими воркерами. При этом другие группы или индивидуальные потребители могут независимо читать тот же поток – то есть можно сочетать и широковещательную модель.
- Хранение данных: По умолчанию данные Streams хранятся в памяти, но Redis может сбрасывать их на диск (снимками или журналом операций) для сохранности. Однако обычно Streams настроены на ограниченный retention – например, хранить последние N сообщений или последние X часов, очищая более старое. Это как доска объявлений, с которой убирают старые стикеры, чтобы не висели вечно. Поэтому Redis Streams не предназначен для долговечного хранения больших объемов событий (в отличие от Kafka), зато хорош для реальных времен и умеренных объемов.
- Использование: Redis Streams применяют, когда уже есть Redis и нужно простое решение для очередей или уведомлений: например, быстрый обмен событиями между микросервисами, отслеживание небольших потоков событий (логирование последней активности), распределение задач на несколько воркеров, где задержка минимальна. Это легковесная альтернатива тяжелым брокерам, хотя и с ограничениями по масштабу хранения.
Простыми словами: Redis Streams – это как быстрый курьер внутри одного офиса. Все записки мгновенно разносятся по отделам, потому что курьер носит их в руках (в памяти), а не возит на грузовике. Он помнит последние поручения, но старые может выбрасывать, чтобы не захламляться. Если задача должна быть выполнена одним из нескольких сотрудников – он отдаст записку первому свободному. Это решение для скорости и простоты, хотя если офис выгорит (сервер перезагрузится без сохранения) – записи пропадут, поэтому при критичных данных лучше настроить сохранность (резервные копии на диск или репликацию сервера).
Amazon SQS
Amazon SQS (Simple Queue Service) – это облачный брокер сообщений от Amazon Web Services. В отличие от предыдущих систем, SQS – полностью управляемый сервис: вам не нужно устанавливать и администрировать сервер, вы просто используете API для отправки и получения сообщений, а всю «почтовую инфраструктуру» обслуживает сам Amazon. Аналогия: SQS – это арендованный почтовый ящик в охраняемом почтовом центре. Вы доверяете обслуживание почты провайдеру и просто пользуетесь результатом.
Особенности Amazon SQS:
- Простота и надежность: Для разработчика SQS выглядит очень просто – есть очередь, в которую можно отправлять сообщения через интернет, и можно из нее читать. Amazon гарантирует, что сообщения надежно хранятся (в нескольких дата-центрах) пока не будут доставлены. Нет забот о настройке сервера, обновлениях – все это скрыто. SQS обеспечивает высокую доступность, беря на себя репликацию и отказоустойчивость.
- Два типа очередей: SQS предлагает Standard Queue (стандартная) и FIFO Queue (первым пришло – первым вышло). Стандартная очередь масштабируется практически без ограничений по throughput, но может доставлять сообщения нестрого по порядку и иногда с дубликатами (ат-литст уанс, "как минимум один раз" доставка). FIFO очередь гарантирует порядок и отсутствие дублей, но имеет ограниченную пропускную способность (до 300 сообщений/сек без батчинга, либо до 3000/сек с батчингом, либо выше с недавними расширениями). Выбирается тип в зависимости от требований приложения.
- Интеграция с AWS: SQS хорошо сочетается с другими сервисами AWS. Например, можно автоматически запускать функции AWS Lambda при приходе сообщений, или связать очередь SQS как триггер для обработчиков. Также есть поддержка Dead Letter Queue – отдельной очереди для сообщений, которые не удалось обработать (например, после нескольких неудачных попыток).
- Ограничения: SQS работает через интернет-запросы, поэтому есть небольшой латентность (десятки миллисекунд до сотен, в зависимости от сети). Также есть ограничения на размер сообщения (256 КБ), время хранения (по умолчанию 4 дня, максимум 14 дней), и на сами запросы (например, чтобы получать сообщения, клиент периодически опрашивает очередь или использует long polling).
- Использование: SQS отлично подходит для облачных приложений и микросервисов, особенно если вся архитектура развернута в AWS. Это вариант "не думать о брокере": нужно быстро организовать взаимодействие сервисов – создали очередь через консоль AWS и пользуетесь. Типичные сценарии – рассылка уведомлений, обработка фоновых задач, связка между распределенными компонентами (например, веб-сервер ставит задачу в очередь, а воркер в другом AWS-сервисе ее выполняет).
Простыми словами: Amazon SQS – это как банковская ячейка для обмена сообщениями. Вы кладете свое письмо в надежное хранилище у банка (Amazon), и ваш партнер потом его забирает. Банк следит, чтобы с письмом ничего не случилось, дублирует сейф на всякий случай. Да, за аренду ячейки вы платите (SQS платный), и вы ограничены правилами банка (размер письма, срок хранения), но взамен получаете удобство и уверенность, что все будет доставлено, даже если ваш собственный сервер упадет.
(Кроме перечисленных, существуют и другие брокеры сообщений: например, ActiveMQ (еще один популярный open-source брокер, похожий на RabbitMQ), IBM MQ (enterprise-решение, особенно в банковском секторе), облачные аналоги вроде Google Pub/Sub, Azure Service Bus, а также сверхлегковесные системы как NATS. Все они решают схожие задачи с разными уклонами, но в рамках обзора мы остановились на самых распространенных решениях.)
Сравнение брокеров по ключевым параметрам
Теперь, когда мы в общих чертах познакомились с Kafka, RabbitMQ, Redis Streams и Amazon SQS, сравним их по нескольким важным критериям: производительность, надежность, простота эксплуатации и возможности анализа данных. У каждого брокера свои сильные стороны, и выбрать подходящий можно, поняв, какие требования приоритетны для вашей задачи.
Производительность (скорость и масштабируемость)
- Apache Kafka: рассчитан на максимальную пропускную способность. В кластере Kafka из нескольких узлов можно стабильно пропускать миллионы сообщений в секунду. Его секрет – горизонтальное масштабирование: топики делятся на разделы, которые обрабатываются параллельно разными брокерами. К тому же Kafka эффективно работает с диском (последовательная запись/чтение, минимальные случайные операции). Задержки (latency) у Kafka могут быть несколько выше, чем у чисто memory-решений, но для потоковой обработки (где важнее throughput) Kafka лидер. Он отлично тянет нагрузки Big Data и справляется с потоком данных от тысяч устройств или событий в минуту.
- RabbitMQ: очень быстрый на умеренных нагрузках и обеспечивает низкие задержки доставки. Один сервер RabbitMQ может обрабатывать десятки тысяч сообщений в секунду (а в некоторых бенчмарках – сотни тысяч, в зависимости от конфигурации и железа). Он тоже позволяет кластеризацию, но масштабирование не такое прозрачное: отдельная очередь живет на одном узле, поэтому сверхбольшой поток не разделится автоматом между всеми нодами (в Kafka поток делится). Тем не менее, для большинства типичных веб-приложений производительности RabbitMQ достаточно с большим запасом. Его плюс – стабильность под нагрузкой и предсказуемое время доставки для небольших сообщений.
- Redis Streams: очень высокая скорость на одном инстансе за счет работы в памяти. В случаях, где нужно мгновенно реагировать на событие (миллисекунды), Redis покажет минимальную задержку. По сырой пропускной способности на одной машине Redis может опережать RabbitMQ, а иногда и Kafka (без учета сети и диска). Однако Redis обычно работает вертикально (масштабируется на мощность сервера). Хотя существуют Redis-кластеры, они шардингом распределяют разные ключи (потоки) по узлам; один поток не масштабируется на несколько серверов. Поэтому Redis Streams хорошо подходит для средних нагрузок (сотни тысяч сообщений в секунду) и обеспечивает мгновенную реакцию, но для удержания постоянного гигантского потока (гигабайты в секунду) Kafka-стратегия масштабирования лучше.
- Amazon SQS: производительность SQS зависит от типа очереди. Стандартные очереди SQS фактически масштабируются автоматически внутри AWS – вы можете отправлять и получать тысячи сообщений в секунду без ручной настройки кластера. На практике SQS (Standard) может обрабатывать сотни миллионов запросов в день. FIFO-очереди более ограничены (по умолчанию 300 op/s, с возможностью расширения до ~3000 op/s или даже десятков тысяч с новым режимом High Throughput FIFO). Задержка у SQS немного выше, так как идет через интернет и распределенную систему (сотни миллисекунд для доставки не редкость). Но для облачных сценариев, где сверхнизкая latency не критична, SQS предоставляет достаточный throughput и авто-масштабирование: вам не придется думать, выдержит ли брокер нагрузку – AWS под капотом сам масштабирует ресурсы.
Надёжность и гарантии доставки
- Apache Kafka: изначально спроектирована как устойчивое хранилище событий. При правильной настройке Kafka обеспечивает как минимум один раз доставку (at-least-once): сообщение записывается на диск и реплицируется на несколько узлов. Даже если один узел упадет, копия сообщения есть на других. Потребители сами хранят смещение, поэтому могут заново прочитать с последнего подтвержденного места после сбоя. Kafka может добиваться и ровно один раз (exactly-once) обработки в сочетании с транзакциями и idempotent-продюсерами, хотя это сложнее. В общем, Kafka очень надежна в плане не потерять данные: она скорее повторит сообщение или задержит, чем отбросит. Также благодаря хранению в журнале, даже если потребитель был долго офлайн, он сможет получить все накопленные сообщения.
- RabbitMQ: ориентирован на надежную доставку при условии использования подтверждений и устойчивых настроек. Если включены persistent сообщения и durable очереди, RabbitMQ записывает их на диск – это позволяет восстановиться после перезапуска сервера без потери сообщений. Также можно настроить кластеры с зеркальными очередями (mirrored queues), чтобы копии сообщений хранились на резервных узлах – при падении одного узла очередь не пропадет. По умолчанию RabbitMQ обеспечивает at-least-once доставку (с подтверждениями и возможным дублированием при повторной попытке). At-most-once (без подтверждений, может потеряться) тоже возможна, если хотите быстрее но рискованнее. Exactly-once сложно достичь (нужны дополнительные механизмы на уровне приложения). В целом, RabbitMQ в боевых настройках очень надежен: если потребитель не подтвердил получение, сообщение вернется в очередь; можно настроить Dead Letter Queue для неудачных сообщений. Он гарантирует порядок в пределах одной очереди (если один получатель) и старается не терять данные, но разработчик должен правильно конфигурировать надежность (иначе by default сообщения в памяти могут пропасть при сбое).
- Redis Streams: надежность здесь настраиваема. В чистом виде Redis хранит данные в оперативной памяти, что означает риск потери при аварии. Однако Redis поддерживает периодические снапшоты на диск и журнал Append Only File (AOF), который записывает каждую операцию на диск. Если AOF включен и настроен на флаш каждую секунду или всегда, то потеря данных минимальна (от нуля до нескольких секунд данных может потеряться при аварии). Также Redis можно реплицировать на слейвы для отказоустойчивости. Таким образом, Redis Streams может быть достаточно надежным (многие используют Redis годами без потерь), но важно понимать: он не был создан в первую очередь как хранилище надежности, а скорее как ускоритель. По умолчанию (без AOF) при падении сервера последние непросохраненные сообщения потеряются. С AOF – риск мал, но производительность чуть снижается. Гарантии доставки в Redis Streams обеспечиваются механизмом Pending Entries List в группах потребителей: если один потребитель взял сообщение и не подтвердил (XACK), его можно через некоторое время выдать другому (как requeue). Это аналог ack в RabbitMQ. Однако, если вообще все потребители получили и мы удалили запись, а они упали, то сообщения не вернуть – история потеряна после удаления или trimming. В общем, Redis Streams можно сделать достаточно надежным для многих случаев, но Kafka и RabbitMQ все же более ориентированы на гарантированную сохранность. Redis хорош, когда 99.9% случаев важнее, чем 0.1% потерь в угоду скорости, либо когда поверх него строят логику повторной попытки.
- Amazon SQS: очень надежен, так как AWS берет ответственность за сохранность сообщений. Сообщения SQS хранятся распределенно на нескольких серверах AWS; потерять их практически невозможно (если только сам AWS глобально не выйдет из строя, что крайне маловероятно). Каждое сообщение имеет идентификатор, и SQS гарантирует, что оно будет либо доставлено, либо останется в очереди до истечения таймаута. При получении сообщения потребитель должен либо удалить его после обработки, либо не удалять, тогда по истечении visibility timeout сообщение снова станет видимым для других потребителей. Это дает семантику at-least-once: если подтверждение (delete) не произошло, сообщение рано или поздно вновь будет выдано. Дубликаты в Standard очереди возможны, но потеря – практически нет. FIFO очередь избегает дублирования (exactly-once delivery без повторов), сохраняя при этом гарантированную доставку. AWS также предлагает DLQ (dead-letter queues) для сообщений, которые многократно не были успешно обработаны – они не теряются, а уходят в специальную очередь для разбирательств. В целом, SQS – одно из самых надежных решений, потому что построено на инфраструктуре AWS с множеством резервирований.
Простота настройки и поддержки
- Apache Kafka: самая мощная, но и самая сложная в эксплуатации система из перечисленных. Развернуть Kafka-кластер – задача нетривиальная: требуется настроить несколько брокеров, координацию (ранее с помощью Zookeeper, в новых версиях Kafka собственный механизм KRaft), продумать разделы, replication factor, мониторинг. Администрирование Kafka требует опыта: нужно следить за здоровьем кластера, балансировать разделы по узлам, управлять ростом хранилища (чтобы не заполнилось дисковое пространство), обновлять версию без даунтайма и т.д. Проще говоря, Kafka обычно требует выделенной команды или как минимум толкового DevOps-инженера для сопровождения, особенно в продакшене с высокими нагрузками. Альтернативой являются облачные управляемые Kafka (Confluent Cloud, AWS MSK, etc.), где часть забот снимается. Но если говорить про собственное развертывание – это непросто. Также разработчику, чтобы эффективно использовать Kafka, нужно разбираться в концепциях топиков, партиций, смещений, групп потребителей – это чуть более высокий порог входа, чем у очереди RabbitMQ. Взамен Kafka дает огромные возможности, но в мелких проектах её сложность может быть избыточной.
- RabbitMQ: относительно простой в установке и использовании. Запустить одиночный RabbitMQ сервер легко – доступны готовые образы Docker, пакеты, минимальная конфигурация по умолчанию работает. Настроить кластер RabbitMQ тоже проще, чем Kafka: достаточно соединить несколько узлов, настроить политика зеркалирования очередей, если нужно. RabbitMQ имеет удобную панель управления через веб-интерфейс, где можно смотреть очереди, сообщения, потребителей, что упрощает поддержку. Требования к ресурсам у RabbitMQ умеренные, и администрирование сводится к мониторингу очередей (чтобы не распухали бесконечно), диска (если много сообщений, чтобы хватало места) и иногда рестартам узлов для обновления. В целом, поддерживать RabbitMQ проще, чем Kafka: меньше компонентов, более зрелая простая модель. Разработчикам тоже несложно начать – концепции очередей, обменников и привязок интуитивно понятны после пары примеров. Документация и комьюнити хорошие. Поэтому для команд без большого опыта распределенных систем RabbitMQ – удобный выбор: поднял и используешь, особых сюрпризов нет.
- Redis Streams: очень просты в начале, если уже знакомы с Redis. Фактически, никакого отдельного сервиса "Streams" нет – это тот же Redis. Поэтому установка сведется к разворачиванию Redis-сервера (что легко, опять же Docker, пакет, или использование существующего). Администрирование Redis тоже отлажено: он достаточно неприхотлив, хотя важно следить за памятью (Redis находится в RAM, если сообщений становится больше, чем память, либо нужно увеличивать память, либо настраивать сброс старых записей). Streams добавляет команд в Redis, но в остальном управление похоже на другие типы – можно наблюдать длину стрима, потребителей,Pending-list через команды. Сложность может возникнуть, если потоков много и требуется горизонтальное масштабирование – Redis-кластер сложнее настроить, чем RabbitMQ кластер, а гарантий порядка при шардинге потоков нет. Также, если очень высокий объем данных, придется тонко настраивать политику обрезки (XTRIM) и persistence, чтобы не перегрузить сервер. Но в малых и средних сценариях поддержка Redis Streams мало чем отличается от поддержки просто Redis: делайте бэкапы (AOF), мониторьте производительность и всё. Разработчикам Streams понятны, особенно тем, кто использовал Redis Pub/Sub или Kafka: концепции похожи (сообщения с ID, группы, подтверждения). Библиотеки для работы есть, но не такие многочисленные, как для RabbitMQ (однако обернуть Redis команду в код несложно). В общем, по простоте старта Redis Streams, наверное, лидер – запускаете Redis и пользуетесь, но будьте готовы самим реализовывать некоторые моменты (например, нет встроенной панели для просмотра потоков; придется писать скрипт или пользоваться командной строкой Redis).
- Amazon SQS: здесь практически вся сложность администрирования снята с ваших плеч. Вы вообще не запускаете сервера – просто создаете очередь через веб-консоль AWS или CLI. AWS сам масштабирует инфраструктуру, применяет патчи, следит за надежностью. Ваша задача – контролировать разве что настройки: какие тайм-ауты, размер сообщений, включить ли длинный опрос (Long Polling) для уменьшения холостых запросов, установить ли Dead Letter очередь. То есть работа с SQS – это больше конфигурирование через понятный интерфейс, чем администрирование. Конечно, нужно учитывать затраты (SQS платен померно использованию), следить, чтобы не росла бесконтрольно очередь (потому что за хранение тоже платите). Но в плане поддержки – она минимальна: AWS делает всю грязную работу. Разработчикам SQS тоже прост: интеграция идет через AWS SDK (или даже просто HTTP запросы REST API). Не надо задумываться о деталях протокола – отправил JSON и получил JSON. Единственное, надо управлять получением сообщений: SQS не "пушит" сам по себе, нужно либо периодически опрашивать, либо подключить Lambda/подписку. Но шаблоны использования хорошо документированы. В итоге, SQS – самый беспроблемный в эксплуатации, но замыкает вас на экосистему AWS и имеет ограничения типичного облачного сервиса.
Возможности анализа данных (BI и ретроспективный анализ)
В современных системах ценность представляют не только сами сообщения, но и информация из них – возможность проанализировать накопленные события, построить отчеты, подключить инструменты бизнес-аналитики (BI). Брокеры различаются по тому, насколько легко интегрировать их с аналитическими контурами и как они сохраняют историю событий.
- Apache Kafka: здесь Kafka практически создана для анализа событий. За счет того, что сообщения хранятся длительно в топиках, Kafka может выступать как источник исторических данных. Существует экосистема Kafka Connect – готовые коннекторы, позволяющие выгружать данные из Kafka в хранилища (базы данных, Hadoop, Elasticsearch, облачные озера данных) или наоборот, загружать из внешних систем в топики. Это облегчает интеграцию с BI: например, можно настроить коннектор, который все сообщения из топика «Покупки» будет складывать в Data Warehouse раз в реальном времени, и аналитики уже работают с базой. Кроме того, на Kafka базируются стриминговые аналитические системы: ksqlDB (SQL-подобный анализ потоков прямо в Kafka), Apache Spark Streaming, Flink, Storm – они могут потреблять данные из Kafka и вычислять метрики онлайн (например, подсчитывать продажи за час, искать аномалии). Для ретроспективного анализа Kafka хороша тем, что можно перечитать топик с начала в любое время: если вы внедрили новый аналитический сервис, ему не нужны данные "сейчас и вперед", он может запросить у Kafka и всю историю за последний год (если хранили). Это похоже на прослушивание плейлиста с начала – все события проиграются. Благодаря этому, компании часто используют Kafka как центральное хранилище событий (Event Store), на основе которого строятся и онлайн-сервисы, и офлайн-аналитика. Интеграция с BI может быть реализована через связку Kafka + базы/аналитические платформы: например, Kafka -> Spark -> BI-дашборды, или Kafka -> коннектор -> PostgreSQL, откуда уже отчеты. Таким образом, Kafka наиболее богата возможностями для анализа: хранит историю, имеет средства интеграции, и сама по себе является источником истинны для событий.
- RabbitMQ: в случае RabbitMQ основной акцент – операционная доставка, а не хранение. Сообщения там обычно не живут долго: прочитал – удалил. Поэтому напрямую RabbitMQ не предоставляет возможностей для ретроспективного анализа данных – к тому моменту, когда вы захотите построить отчет, сообщений в очередях, скорее всего, уже нет. Чтобы анализировать данные, проходившие через RabbitMQ, нужно на этапе получения сообщений сохранять их в отдельное хранилище (лог, базу данных). Например, можно сделать скрытого «подписчика» на ту же очередь, который будет складывать все копии сообщений в архив. Или отправитель может дублировать сообщение в RabbitMQ и в аналитическую систему параллельно. RabbitMQ сам по себе не имеет встроенных коннекторов к BI. Однако, он интегрируется с внешними инструментами через плагины (например, плагин Firehose может слать все сообщения в сторонний лог). Тем не менее, это дополнительные усилия. Интеграция с BI обычно достигается через создание хранилища событий вне RabbitMQ. Сам Rabbit предоставляет метрики (сколько сообщений, размеры очередей) для мониторинга, но не хранит содержимое. Ретроспективный анализ событий из RabbitMQ возможен только если вы где-то сохраняли те события. Поэтому, если вашей цели — анализировать поток событий спустя время, RabbitMQ требует построения дополнительного слоя (например, писать все сообщения из RabbitMQ в Hadoop). В итоге, RabbitMQ менее удобен для анализа, но отлично справляется с задачей “доставить и забыть”.
- Redis Streams: как и RabbitMQ, Redis Streams не предназначен для долговременного хранения больших объемов. Хотя, в отличие от классических очередей, Streams может сохранять историю сообщений (до тех пор, пока не превысите лимиты и не обрежете). Теоретически, можно хранить очень длинный поток в Redis и читать его даже после потребления. Но на практике ограничивающий фактор – память. Держать миллион сообщений в Redis (особенно если они крупные) – дорого по памяти. Чаще Streams настроены на хранение только последних сообщений или тех, что еще не обработаны. Для анализа данных опять же придется либо выгружать сообщения из Streams куда-то (Redis не имеет готовых коннекторов для этого, нужно написать код, выбирающий данные и записывающий в файл/БД), либо использовать сам Redis как источник (например, скриптом прочитать весь диапазон ID в Streams и сделать агрегаты – но это вручную). В реальности Redis Streams применяют для онлайн обработки – когда интересны события «здесь и сейчас». Если нужен BI отчет за месяц – скорее всего, данные из Streams уже потерты или ушли. Однако, Redis могут использовать в аналитических пайплайнах как буфер: например, быстрый сбор событий в Streams, а затем периодическая выгрузка в постояное хранилище. В целом, аналитические возможности у Redis Streams ограничены, интеграция с BI – только кастомными средствами. Зато Streams можно применять для реал-тайм дашбордов, когда вы в приложении подписаны на поток и видите обновления (но это больше про оперативный мониторинг, чем про BI).
- Amazon SQS: как и RabbitMQ, SQS – очередь доставки, не хранилище событий. Сообщение после получения обычно удаляется. Amazon SQS не дает возможности запросить «а покажи-ка все сообщения за последний день» – таких функций нет, да и хранение ограничено 14 днями максимум. Поэтому для BI нужно перехватывать сообщения: AWS предлагает для этого интеграции с другими сервисами. Например, можно подписать AWS Lambda на очередь, и внутри Lambda уже отправлять данные в Amazon S3 или Redshift (хранилище данных) для аналитики. Либо использовать Amazon Kinesis Firehose, если нужен поток в аналитическую систему – хотя SQS и Kinesis не напрямую интегрированы, скорее Kinesis заменяет SQS в задачах потоковой аналитики. SQS предоставляет разве что CloudWatch Metrics по количеству сообщений, задержке – это для мониторинга, но не содержимое. Для ретроспективного анализа бизнеса SQS сам по себе данных не сохранит – нужно дополнительно логировать. То есть архитектура будет: SQS для коммуникации + параллельно сохранять нужные данные в базу. Альтернативно, можно использовать Amazon SNS (служба уведомлений) совместно с SQS: SNS будет рассылать копии сообщений в несколько мест, одна из которых – SQS для обработки, другая – например, Lambda, которая сохранит в БД. Таким образом, возможности BI через SQS требуют дополнительной обвязки. Если ваша цель – именно анализировать поток событий, возможно, стоит сразу смотреть на специальные решения (Kafka, Kinesis). Но если SQS нужен чисто как клей между сервисами, то для анализа вы будете работать с другими инструментами AWS.
Подводя итог сравнения: Kafka лидирует в сценариях, где нужны масштаб и анализ данных, RabbitMQ – сбалансированный выбор для надежной интеграции микросервисов с гибкими маршрутам и простотой, Redis Streams – для ультра-быстрого обмена на малом участке и простоты внедрения, Amazon SQS – для минимальных забот о брокере и интеграции в облаке, но с ограниченной прямой аналитикой.
Частые вопросы на собеседовании о брокерах сообщений
Ниже приведены распространенные вопросы, которые могут прозвучать на интервью, связанные с брокерами сообщений, и краткие ответы на них:
- Что такое брокер сообщений и зачем он нужен?
Ответ: Брокер сообщений – это система-посредник для обмена данными между приложениями. Он принимает сообщения от отправителей и доставляет получателям, обеспечивая асинхронность, надежность и гибкость коммуникации. Благодаря брокеру отправитель и получатель могут не зависеть друг от друга во времени и реализации – это упрощает архитектуру и повышает устойчивость системы. - В чем разница между очередью сообщений и брокером сообщений?
Ответ: Очередь сообщений – это про структуру хранения, где сообщения хранятся до обработки (обычно в порядке FIFO). Брокер сообщений – более широкое понятие: это целое программное решение, которое может содержать множество очередей и дополнительно управляет маршрутизацией, доставкой, подтверждениями. Простыми словами, очередь – компонент для хранения сообщений, а брокер – «почтальон», который использует очереди и другие механизмы, чтобы организовать обмен сообщениями между множеством участников. - Какие существуют гарантии доставки сообщений?
Ответ: Основные три типа – at most once (не более одного раза: сообщение либо доставится, либо может потеряться, дубликатов не бывает), at least once (как минимум один раз: сообщение точно не потеряется, но может прийти дубликат при повторной доставке) и exactly once (ровно один раз: ни потери, ни дубликатов, достижимо комбинацией механизмов). Большинство брокеров по умолчанию обеспечивают at-least-once (с подтверждениями и возможным дублированием). Exactly-once – самая сложная гарантия, достигается дополнительной логикой (например, в Kafka через транзакции, в распределенных системах – идемпотентностью обработки). - Когда лучше использовать Kafka, а когда RabbitMQ?
Ответ: Kafka стоит выбирать, когда нужно работать с очень большим потоком данных, когда важна скорость на больших объемах и сохранение истории событий для последующего анализа. Это хорошее решение для логирования, аналитики, событий, которые читают многие потребители. RabbitMQ лучше подходит для классических задач интеграции между сервисами, фоновых задач, когда требуется сложная маршрутизация или протоколы (AMQP, MQTT), и объем сообщений не в масштабе «биг-дата». RabbitMQ проще внедрить для небольших и средних проектов, Kafka имеет смысл для крупных систем, потоковых данных, где ценен журнал событий. В банковских транзакциях, например, часто берут RabbitMQ (гарантированная доставка, маршрутизация), а для сбора кликов на сайте – Kafka (большой поток, аналитика). - Как реализовать повторное воспроизведение событий (ретроспективный анализ) с помощью брокера?
Ответ: Для ретроспективного анализа нужен брокер, который хранит историю сообщений. Например, в Kafka можно просто не удалять сообщения после чтения – потребители отслеживают смещение. Новый потребитель может подписаться на тему и запросить данные с начального смещения, фактически «проиграть» заново все события. Это удобно для аудита или перезапуска упавшего компонента. В RabbitMQ и SQS сообщения исчезают после получения, поэтому чтобы воспроизвести события, их нужно отдельно логировать (например, писать в базу при получении). Некоторые брокеры, как Redis Streams, позволяют сохранять некоторое прошлое, но чаще всего Kafka используется для таких целей, как своего рода "магнитофон", который можно перемотать назад. - Что такое модель «публикация-подписка» и чем она отличается от модели «точка-точка»?
Ответ: «Публикация-подписка» (pub/sub) – паттерн, где отправитель (издатель) публикует сообщение в некий канал/тему, а несколько подписчиков получают каждое такое сообщение. Это как радио: диктор говорит – все настроившиеся услышат. «Точка-точка» (point-to-point) – паттерн очереди, где у сообщения только один получатель. Отправитель кладет сообщение в очередь, и один из потребителей его забирает (другие уже не получат именно это сообщение). То есть pub/sub – для рассылки одному-ко-многим, точка-точка – для доставки одному из получателей. Брокеры часто поддерживают оба режима, в зависимости от настройки (например, в RabbitMQ через разные типы exchange, в Kafka через разные группы потребителей).
Надеемся, этот обзор помог разобраться с брокерами сообщений. Помните, что выбор конкретного решения зависит от задач: где-то критична скорость и анализ (Kafka), где-то простота и маршрутизация (RabbitMQ), или вовсе отсутствие администрирования (SQS). Но в основе всех них лежит один принцип – надежно доставить сообщение из пункта А в пункт Б, освобождая нас от лишних хлопот и делая системы более гибкими и устойчивыми.