«Хорошо вам айтишникам, деньги лопатой гребете и ничего не делаете» - стандартный посыл от многих людей других профессий. Так то да, у меня есть детская лопатка для песочницы, каждый месяц ей пользуюсь. Но абсолютно у каждой профессии есть и свои минусы. Вот, например:
Пока нормальные люди радуются майским праздникам, жарят шашлыки и отдыхают на природе, ты сидишь в ночи за ноутбуком и разбираешься с прилегшим продакшеном.
В принципе, нечего ныть, каждый выбрал сам свой путь. Да и погода за окном немного успокаивает, намекая на то, что выбор твой не так уж и плох.
Ладно, хватит лирики.
Пока ночью разгребал последствия одного из инцидентов на проде, заметил на одном из файловых серверов такую картину:
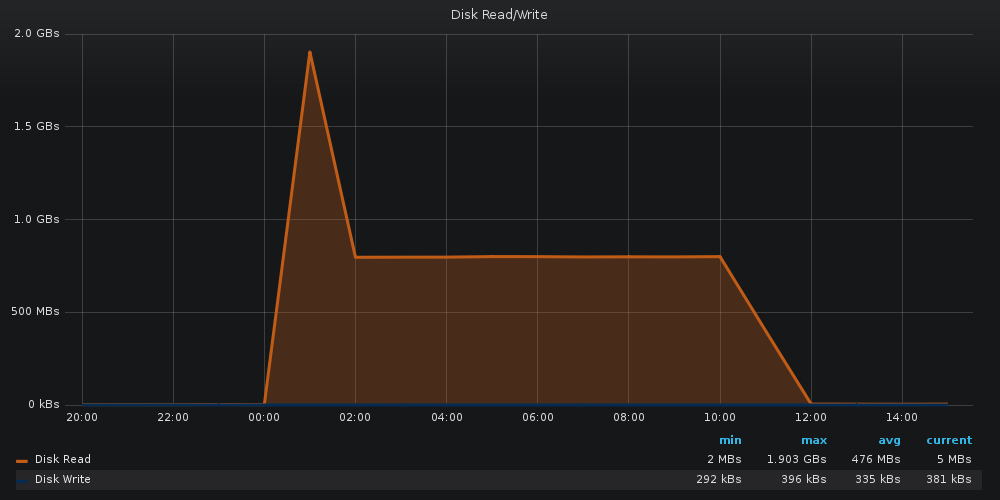
Сразу вспоминается отрывок из фильма "А как это мы скакнули от 100 тысяч к нескольким миллионам?". Как это мы скакнули от 4мб/с до 2гб/с?
Сразу вводные - Сервер на CentOS7, 4 диска в сервере (2 в рейде под систему, 2 в рейде под файлы)
Судорожно листаем логи и смотрим, что же такое произошло в час ночи. В /var/log/messages видим такие строки:
Apr 27 01:00:01 cdn_server kernel: md: data-check of RAID array md127
Apr 27 01:00:07 cdn_server kernel: md: data-check of RAID array md0
Apr 27 01:00:09 cdn_server kernel: md: md0: data-check done.
Apr 27 01:01:07 cdn_server kernel: md: data-check of RAID array md2
Apr 27 01:01:13 cdn_server kernel: md: delaying data-check of md1 until md2 has finished (they share one or more physical units)
Apr 27 01:42:47 cdn_server kernel: md: md2: data-check done.
Apr 27 01:42:47 cdn_server kernel: md: data-check of RAID array md1
Apr 27 01:42:58 cdn_server kernel: md: md1: data-check done.
Очень интересно, а как же у нас что-то запускается, если вызов crontab -l говорит "no crontab for root"?
Быстрое гугление дает понимание: data-check - это вывод утилиты raid-check, которая запускается самой системой, но от имени root.
- Заходим в папку /etc/cron.d/ (поскольку нам нужно проверить системный crontab) и видим в ней файл raid-check. Внутри нас ждет тот самый сюрприз:

# Run system wide raid-check once a week on Sunday at 1am by default
0 1 * * Sun root /usr/sbin/raid-check
Итак, система сама запускает утилиту raid-check каждое воскресенье в час ночи.
- Посмотрим, что внутри, и можно ли как-то настроить эти проверки так, чтобы наша система не была настолько сильно шокирована.
Обычный bash скрипт, который берет свои настройки из /etc/sysconfig/raid-check.
- Смотрим, что мы можем указать ему в качестве настроек:
Ну чтож, давайте по порядку:
ENABLED=yes - указывает на то, что скрипт должен отрабатывать. Если укажем что угодно другое, скрипт raid-check завершится.
CHECK=check - тип запуска (check, или repair)
NICE=low - приоритет работы нашего скрипта. Чем ниже мы его выставим, тем меньше его работа будет сказываться на всей системе. В самом конфигурационном файле указано, что доступные значения - high, normal, low, idle, однако скрипт raid-check никак не проверяет приоритет normal.
Параметр renice изменяет NICE значение у процесса для CPU, а ionice - для диска. Изначально, обычному процессу выдается приоритет 20. Значение NICE изменяет значение приоритета. Здесь мы видим, что при параметре high, NICE будет -5, значит приоритет у процесса станет 25. При параметре idle, NICE=15, приоритет станет 5.
CHECK_DEVS, REPAIR_DEVS, SKIP_DEVS - объединяю это логически в одну секцию. Список рейдов, которые нужно проверять, исправлять, либо пропустить. Указывать нужно конкретные имена (вместо /dev/md0 нужно писать md0).
Если не указано ничего (как в стандартном конфиге), список будет браться из директивы active_list, которая получит список всех активных рейдов в системе.
MAXCONCURRENT - Самое интересное в нашем случае. Количество рейдов, которые будут проверяться одновременно. Если не указать ничего - запустится проверка всех рейдов сразу.
В логе очень заметна строка "md: delaying data-check of md1 until md2 has finished (they share one or more physical units)". Система не может проверять два рейд массива одновременно, если они находятся на одних физических дисках.
В выводе команды cat /proc/mdstat видим, что md0, md1 и md2 рейды находятся на дисках nvme0n1 и nvme1n1, но собраны из разных их разделов.
А вот рейд md127 собран из других, обособленных дисков /dev/sdb и /dev/sda.
Возвращаемся к нашему графику дисковой активности ночью и понимаем всю картину:
- В 1:00 запускается проверка рейдов.
- raid-check для md[0,1,2] стартует параллельно с raid-check для md127.
- Как только проверка системных рейдов завершается, утилизация дисков падает вдвое.
И вот тут наступает время для философии. А плохо ли это?
С одной стороны, параллельно у нас идет проверка только у рейдов md2 и md127. В проверке затронуты абсолютно разные физические диски, конфликтов быть не должно.
Однако, md2 - системный диск, поэтому результаты проверки рейда md127 будут все равно писаться на него. А оно нам не особо то и надо.
Судя по логам, проверка рейдов md0, md1, md2 суммарно занимает около 45 минут, а проверка md127 - почти 12 часов.
Общим и единоличным голосованием было принято решение:
MAXCONCURRENT выставляем в значение 1, чтобы массивы проверялись все по очереди
NICE выставляем в значение idle, так как наш рейд массив не настолько большой, и мы можем позволить себе дать ему целые сутки на проверку (если он не будет лишний раз нагружать нашу систему).
Итоговый конфиг /etc/sysconfig/raid-check