SQL — это универсальный язык для взаимодействия с базами данных, который должен знать каждый аналитик, разработчик и дата-инженер. На собеседованиях кандидатам часто предлагают решить практические задачи: написать эффективные запросы, оптимизировать их и предложить решение для конкретных бизнес-кейсов. Давай разберём распространённые типы SQL-задач и эффективные подходы к их решению. Предыдущее задание: Требуется вывести имена пассажиров, которые встречаются в базе данных более одного раза (имеют полных тёзок), отсортированные по убыванию частоты встречаемости. Результирующая таблица должна содержать: Для решения задачи используется таблица: SELECT name
FROM Passenger
GROUP BY name
HAVING COUNT(*) > 1
ORDER BY COUNT(*) DESC; Для больших таблиц: SELECT
name,
COUNT(*) AS frequency
FROM
Passenger
GROUP BY
name
HAVING
COUNT(*) > 1
ORDER BY
frequency DESC; SELECT DISTINCT name
FROM (
SELECT
name,
COUNT(*) OVER (PARTITION BY name) AS fr
SQL — это универсальный язык для взаимодействия с базами данных, который должен знать каждый аналитик, разработчик и дата-инженер. На собеседованиях кандидатам часто предлагают решить практические задачи: написать эффективные запросы, оптимизировать их и предложить решение для конкретных бизнес-кейсов. Давай разберём распространённые типы SQL-задач и эффективные подходы к их решению.
Предыдущее задание:

Постановка задачи
Требуется вывести имена пассажиров, которые встречаются в базе данных более одного раза (имеют полных тёзок), отсортированные по убыванию частоты встречаемости. Результирующая таблица должна содержать:
- name — имя пассажира (только для тех, у кого есть тёзки)
- Сортировка по количеству повторений имени (от наиболее распространённых к наименее)
Анализ структуры базы данных
Для решения задачи используется таблица:
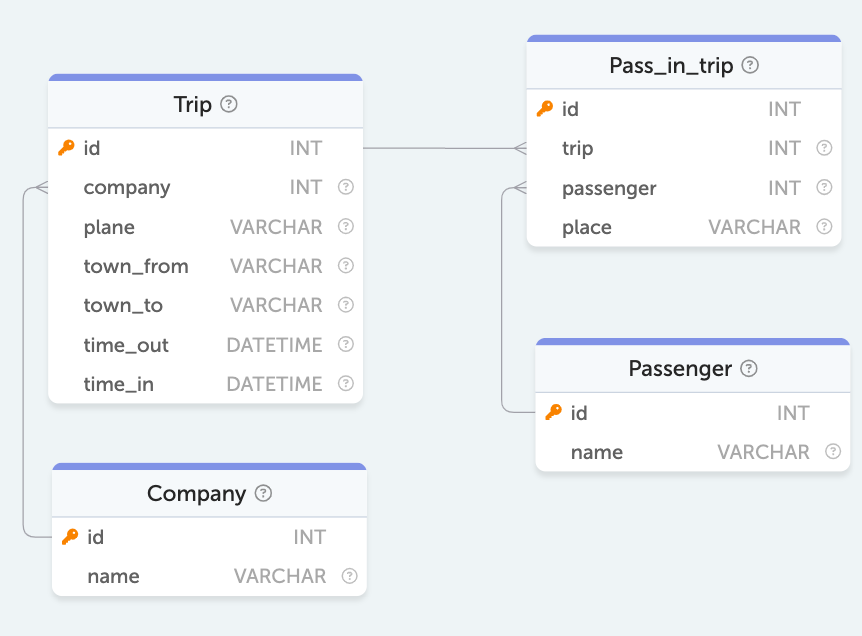
- Passenger — содержит информацию о пассажирах:
name — полное имя пассажира (ключевое поле для анализа)
Другие поля не требуются для решения
Детальный разбор решения
Оптимальное решение для MySQL/PostgreSQL
SELECT name
FROM Passenger
GROUP BY name
HAVING COUNT(*) > 1
ORDER BY COUNT(*) DESC;
Пошаговое объяснение:
- FROM Passenger — выбор данных из таблицы пассажиров
- GROUP BY name — группировка записей по полю name
- HAVING COUNT(*) > 1 — фильтрация групп, оставляя только имена с 2+ повторениями
- ORDER BY COUNT(*) DESC — сортировка результатов по количеству повторений (убывание)
- SELECT name — вывод только поля name (без отображения счётчика)
Ключевые аспекты решения
1. Группировка и фильтрация
- GROUP BY name создаёт группы одинаковых имён
- HAVING COUNT(*) > 1 эквивалентно HAVING COUNT(*) >= 2 — отбирает только имена с тёзками
- Важно использовать HAVING, а не WHERE, так как фильтрация выполняется после агрегации
2. Сортировка по частоте
- ORDER BY COUNT(*) DESC сортирует по количеству вхождений:
Самые популярные имена в начале списка
DESC обеспечивает убывающий порядок - Можно добавить вторичную сортировку по имени: ORDER BY COUNT(*) DESC, name ASC
3. Оптимизация производительности
Для больших таблиц:
- Индекс на поле name значительно ускорит группировку
- В PostgreSQL можно использовать HASH агрегацию: SET enable_hashagg = on
Альтернативные варианты решения
1. С явным выводом количества повторений
SELECT
name,
COUNT(*) AS frequency
FROM
Passenger
GROUP BY
name
HAVING
COUNT(*) > 1
ORDER BY
frequency DESC;
2. С использованием оконных функций (PostgreSQL)
SELECT DISTINCT name
FROM (
SELECT
name,
COUNT(*) OVER (PARTITION BY name) AS freq
FROM
Passenger
) t
WHERE freq > 1
ORDER BY freq DESC;
3. С подзапросом (менее эффективно)
SELECT
p1.name
FROM
Passenger p1
WHERE
(SELECT COUNT(*) FROM Passenger p2 WHERE p2.name = p1.name) > 1
GROUP BY
p1.name
ORDER BY
(SELECT COUNT(*) FROM Passenger p3 WHERE p3.name = p1.name) DESC;
Частые ошибки и рекомендации
Ошибки:
- Использование WHERE COUNT(*) > 1 вместо HAVING
- Забыть GROUP BY при использовании агрегатных функций
- Включение неагрегированных столбцов в SELECT без группировки
Рекомендации:
- Для анализа можно добавить COUNT(*) в SELECT
- Учитывать регистр: GROUP BY LOWER(name) при необходимости
- Для очень больших таблиц использовать LIMIT для первых N результатов
Дополнительные возможности
Поиск самых популярных имён (топ-10)
SELECT
name,
COUNT(*) AS frequency
FROM
Passenger
GROUP BY
name
HAVING
COUNT(*) > 1
ORDER BY
frequency DESC
LIMIT 10;
Поиск тёзок с дополнительной информацией
SELECT
p.name,
COUNT(*) OVER (PARTITION BY p.name) AS frequency,
p.id
FROM
Passenger p
WHERE
p.name IN (
SELECT name
FROM Passenger
GROUP BY name
HAVING COUNT(*) > 1
)
ORDER BY
frequency DESC,
p.name;
Заключение
Данная задача демонстрирует:
- Эффективное использование GROUP BY и HAVING
- Сортировку по результатам агрегатных функций
- Лучшие практики поиска дубликатов в SQL
🔑 Итоговое решение:
SELECT name
FROM Passenger
GROUP BY name
HAVING COUNT(*) > 1
ORDER BY COUNT(*) DESC;
Расширенное решение с частотой:
SELECT
name,
COUNT(*) AS frequency
FROM
Passenger
GROUP BY
name
HAVING
COUNT(*) > 1
ORDER BY
frequency DESC;