Задача на данный момент - самая свежая в списке сайта К.Ю. Полякова в генераторе 24-х задач. Вообще, эти задачи решаются либо вложенным циклом с минимальной оптимизацией, либо с помощью регулярных выражений. Вот с помощью регулярок мы и решим этот маленький шедевр.

Итак, формулировка задачи.
(№ 8115) (К. Багдасарян) Текстовый файл состоит не более чем из 106 символов и содержит только десятичные цифры и заглавные буквы латинского алфавита. Определите максимальное количество символов в непрерывной последовательности, которые могут представлять запись натурального числа в четырнадцатеричной системе счисления, которое начинается с 1 и кратно 7. Цифры, числовое значение которых превышает 9, обозначены латинскими буквами, начиная с буквы А. Гарантируется наличие такой последовательности.
Решение привожу популярно, построчно
from re import *
👆Подключаем модуль re (regular expressions) для работы с функциями. Нам нужна функция finditer и ее метод .group, но импортируем все функции (пишем *)
s = open('24-337.txt').readline()
👆Открываем файл, скачанный с сайта Полякова в ту же директорию, где находится исполняемый файл нашей программы (1.py, например), ну или прописываем полный путь к файлу. Методом readline() читаем длинную строку в миллион символов и записываем ее в переменную s. Можно еще дописать в конце .strip(), чтобы убрать лишний пробел
reg = r'[1][0-D]*[07]'
👆Создаем переменную reg, в которую записываем паттерн - регулярное выражение. Известно, что число начинается с единицы - пишем после обязательного 'r (подключение "сырой строки" - raw string, то есть строки, в которых символы обрабатываются не как спецсимволы, а обычные) в квадратных скобках символы 14-го числа.
Начинаем число с единицы, то есть пишем [1], затем сразу же [0-D] - перебираем любые варианты из этого набора, они будут подставляться в шаблон. Так писать мы можем, так как коды символов идут от меньшего к большему, по порядку. Далее - символ "*" (хотя пройдет и "+"), что означает любое количество повторений, в том числе и нулевое.
Известно, что число должно быть кратно 7. Можно не переводить его в 10-ную систему счисления, а просто написать концовку числа - символы из набора [07]
m = [x.group() for x in finditer(reg, s)]
👆Основная часть программы. Генератором создаем список, содержащий группы цепочек символов, подходящих под условие нашего регулярного выражения, записанного в переменной reg, найденного в строке s
b = []
👆Создадим пустой список b - в него будем складывать длины цепочек, подходящих под условие). Можно было обойтись и без него, но так симпатичнее.
for i in range(len(m)):
👆Организуем цикл for, перебирающий все элементы списка m по индексу
....b.append(len(str(m[i])))
👆И добавляем в него методом .append длины всех элементов списка m. предварительно преобразуем тип элемента с числового в строковый, чтобы корректно измерить длину
print(max(b))
👆Ну и после цикла выводит на экран максимальный элемент списка, то есть самую большую длину числа в 14-чной СС
Вот вся программа (кому было тяжело читать построчно)
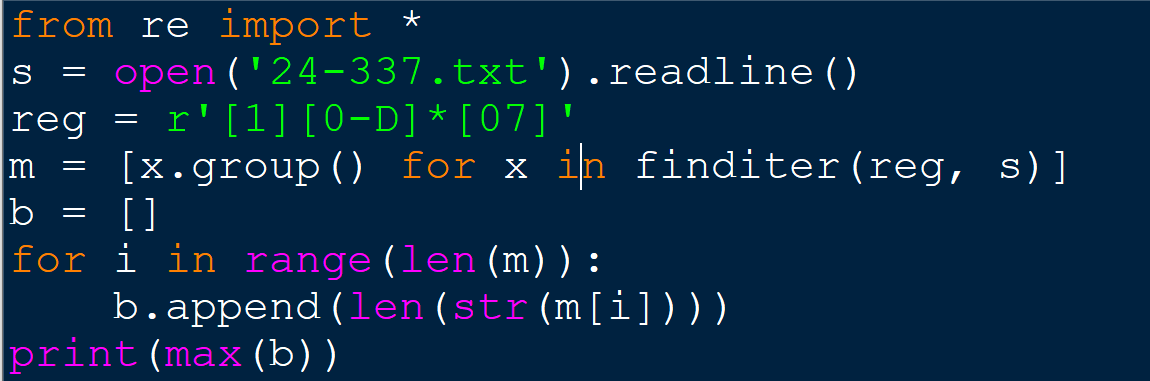
Ну или, если хотите, решение вовсе без списка, всего в 4 строчки - сразу выводим максимальную длину цепочки символов, подходящей под условие регулярки.
Ответ тоже приведу, ну и светлый стиль кода тоже. У многих, кто пытается делить на 7 и проверять остаток, ответ не сходится - разница в единицу получается.
Ниже привожу тоже интересное (но более сложное, наверное) решение с помощью вложенного цикла и небольшой оптимизации.
Способ через двойной цикл
Сразу покажу код, а затем объясню построчно, но уже не так подробно
s = open('24-337.txt').readline().strip()
👆Считываем строку из подключенного файла, на этот раз почистим лишние пробелы
for c in 'QWERTYUIOPSFGHJKLZXVNM': s = s.replace(c, '*')
👆заменяем все символы, которых не может быть в 14-чном числе, на звездочку (можно взять и другой)
##print(s[:400])
👆Советую выводить хотя бы часть строки, чтобы визуально посмотреть, все ли ОК
m = 0
👆в переменной m будем хранить максимум (максимальная длина удовлетворяющей условию цепочки). Обнулим переменную
for l in range(len(s)):
👆Организуем внешний цикл с параметром для перебора начальной границы цепочки символов (переменная l - от англ.left)
....for r in range(l + m, len(s)):
👆Еще один цикл, вложенный связан с правой границей просматриваемой цепочки. Оптимизация заключается в том, что мы прибавляем к левой границе m, чтобы пропускать "отрезки" символов, которые заведомо меньше текущего m
........c = s[l:r+1]
👆Формируем цепочку символов для просмотра от l до r включительно
........if c[0] == '1' and '*' not in c:
👆Тут проверяем, что в цепочке первый символ единица (кавычки обязательны) и в текущей цепочке нет звездочки, то есть неуместного символа
............if c[-1] in '07':
👆ну и проверяем, что последний символ 0 или 7 (кратность семи)
................m = max(m, len(c))
👆Только в этом случае обновляем максимум, выбирая его из текущего m и измеренной длины подходящей цепочки c)
........else: break
👆иначе прекращаем смотреть эту цепочку - она точно нам не подходит
print(m)
Выводим посчитанный максимум на экран и радуемся жизни
надеюсь, статья была полезна. Ставьте 👍, если была польза!
больше задач в статье ниже👇