GIL (Global Interpreter Lock) — это механизм глобальной блокировки интерпретатора, который был введен для поддержки многопоточных программ в Python. Python не является полностью потокобезопасным, и потоки были добавлены в язык позже. GIL удерживает текущий поток до тех пор, пока он не сможет безопасно получить доступ к объектам Python. Это обеспечивает взаимное исключение, позволяя интерпретатору исполнять код только одного потока в любой момент времени.
Разработчики, работающие с однопоточными программами, обычно не замечают влияния GIL на их работу. Однако при работе с многопоточным кодом и кодом, привязанным к процессору, это может стать проблемой. GIL не позволяет одновременно выполнять более одного потока, несмотря на многопоточную архитектуру и количество ядер в процессоре. Здесь очень хорошо показана визуализация работы потоков в Python:
https://dabeaz.blogspot.com/2010/01/python-gil-visualized.html
С замедлением темпов увеличения скорости работы процессоров производители начали увеличивать количество ядер в них. Однако GIL не позволяет в полной мере использовать это преимущество. Тем не менее, у него есть важная функция — управление памятью интерпретатора и внутренними структурами данных.
На момент создания Python понятия «поток» не существовало, и ситуаций, когда несколько потоков одновременно пытались изменить количество ссылок на объект, не возникало. Позднее, с появлением многопоточных процессоров, на один объект могли ссылаться несколько потоков, что приводило к состоянию «гонки» и было небезопасным для потоков. Одновременное обращение к переменной из разных потоков может привести к непредсказуемым результатам работы программы.
Для объяснения работы GIL рассмотрим PyObject — прародителя всех объектов в Python. PyObject содержит две основные вещи:
- ob_refcnt: количество ссылок на объект.
- ob_type: указатель на тип объекта.
Когда счетчик ссылок на объект становится равным нулю, GIL освобождает память, выделенную под этот объект. Пример вывода количества ссылок на пустой список поможет лучше понять этот процесс:
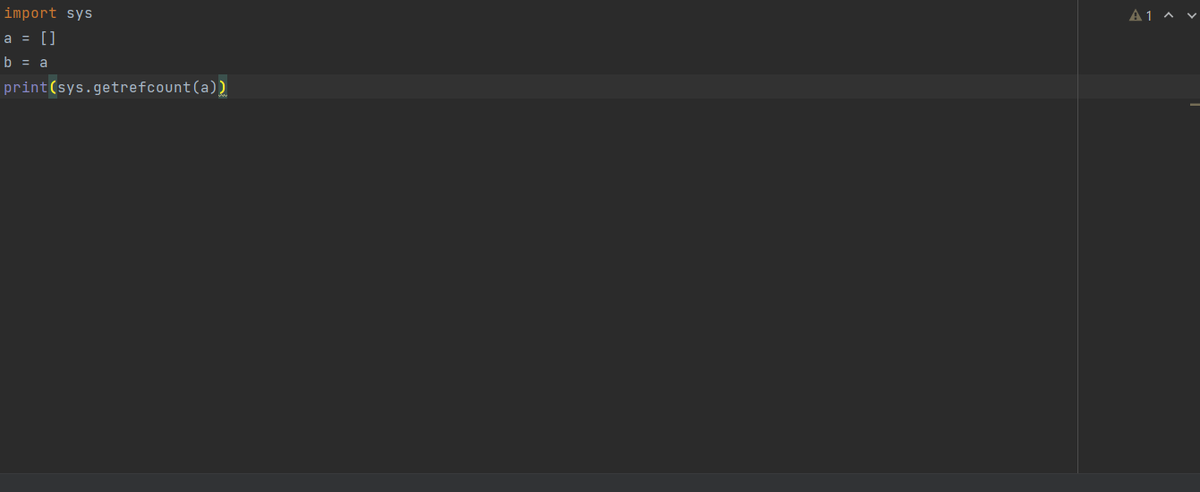
import sys
a = []
b = a
print(sys.getrefcount(a))
Количество ссылок будет равняться 3, на него ссылались a, b и аргумент, переданный в sys.getrefcount(). Попробуйте выполнить этот код в своем терминале, измените его, увеличив количество обращений.
Переменная счетчика ссылок нуждается в защите от условий «гонки», когда одновременно два потока изменяют ее в большую или меньшую сторону. Отсутствие такой зашиты приведет к некорректному освобождению памяти и сбоям в программе.
GIL и есть эта защита переменной счетчика ссылок – это единая блокировка интерпретатора, добавляющая правило, согласно которому выполнение любого байт-кода Python требует блокировки интерпретатора. Фактически любая программа Python, привязанная к процессору, становится однопоточной и дальше мы в этом убедимся на примерах кода.
Рекомендую прочитать статью «Управление памятью в Python», здесь хорошо рассказывается о внутренних механизмах Python:
https://realpython.com/python-memory-management/
Модели параллелизма
Параллелизм — это способность кода выполнять несколько задач одновременно, что значительно увеличивает производительность и скорость отклика. Существует несколько моделей параллелизма: многопоточность, асинхронность и многопроцессорность. Первые две модели обеспечивают параллелизм на одном процессоре, в то время как многопроцессорность позволяет выполнять настоящий параллелизм на нескольких ядрах процессора. Важно понимать разницу между конкурентностью (Concurrency) и параллелизмом (Parallelism).
Конкурентность — это ситуация, когда две или более задачи могут запускаться и завершаться одновременно на одном процессоре и ядре.
Параллелизм — это выполнение нескольких задач или распределенных частей задач независимо и одновременно на нескольких процессорах. На компьютерах с одним процессором и одним ядром настоящий параллелизм невозможен.
Для наглядности представим очередь в столовой:
- Конкурентность: один сотрудник выдает блюдо, затем идет на кассу и рассчитывает покупателя.
- Параллелизм: один сотрудник выдает блюда, а второй одновременно рассчитывает покупателей.
Изучение принципов параллелизма, их преимуществ и недостатков поможет в дальнейшем принимать обоснованные решения по оптимизации программ, особенно тех, которые связаны с вводом-выводом или процессорными операциями.
GIL и многопоточный код
Представь, что GIL — это один микрофон на сцене. Даже если на сцене несколько человек (потоков), говорить в микрофон может только один. Остальные ждут своей очереди.
Многопоточность может быть полезной, если твоя программа много времени тратит на ожидание (например, чтение данных из интернета, запись в файл или ожидание ответа от базы данных). В таких случаях, пока один поток ждет, другой может работать.
Пример:
Ты пишешь программу, которая скачивает несколько файлов из интернета. Пока один поток ждет, когда файл скачается, другой поток может начать скачивать следующий файл. Это ускоряет процесс.
Если твоя программа выполняет тяжелые вычисления (например, математические расчеты или обработку данных), то многопоточность не поможет, потому что GIL не даст потокам работать одновременно. В таких случаях лучше использовать многопроцессорность (запускать несколько процессов вместо потоков).
Пример:
Ты пишешь программу, которая умножает огромные матрицы. Даже если ты создашь несколько потоков, GIL не даст им работать одновременно, и программа не станет быстрее.
В Python есть встроенный модуль threading, который позволяет создавать и управлять многопоточными программами. Этот модуль предоставляет полезные функции для работы с потоками, что делает его удобным инструментом для реализации сложных многопоточных приложений.
Здесь мы сосредоточимся на использовании модуля threading, так как он предоставляет мощные возможности для создания и управления потоками, что особенно важно для разработки серьезных многопоточных программ.
Чтобы оценить преимущества многопоточного программирования, приведу простой пример со списком целых чисел (numbers = [2, 3, 5, 8]), вычислим куб и квадрат каждого из этих чисел. Чтобы наглядно увидеть время работы программы импортируем модуль time.
import time
Оператор time.sleep(0.1) в теле функций приостанавливает выполнение кода на 0,1 секунды в конце каждой итерации. Мы добавили этот оператор, чтобы на мгновение приостановить работу процессора и имитировать задачу, связанную с вводом-выводом. В реальных сценариях такие задачи могут включать ожидание ответа от периферийного устройства или веб-сервиса. Дальше создадим две отдельные функции:
Первая будет возводить числа в квадрат:
def calc_square(numbers):
for n in numbers:
print(f'\n{n} ^ 2 = {n*n}')
time.sleep(0.1)
Вторая вычислять из них куб:
def calc_cube(numbers):
for n in numbers:
print(f'\n{n} ^ 3 = {n*n*n}')
time.sleep(0.1)
Вот так будет выглядеть последовательное выполнение программы:
import time
def calc_square(numbers):
for n in numbers:
print(f'\n{n} ^ 2 = {n*n}')
time.sleep(0.1)
def calc_cube(numbers):
for n in numbers:
print(f'\n{n} ^ 3 = {n*n*n}')
time.sleep(0.1)
numbers = [2, 3, 5, 8]
start = time.time()
calc_square(numbers)
calc_cube(numbers)
end = time.time()
print('Execution Time: {}'.format(end-start))
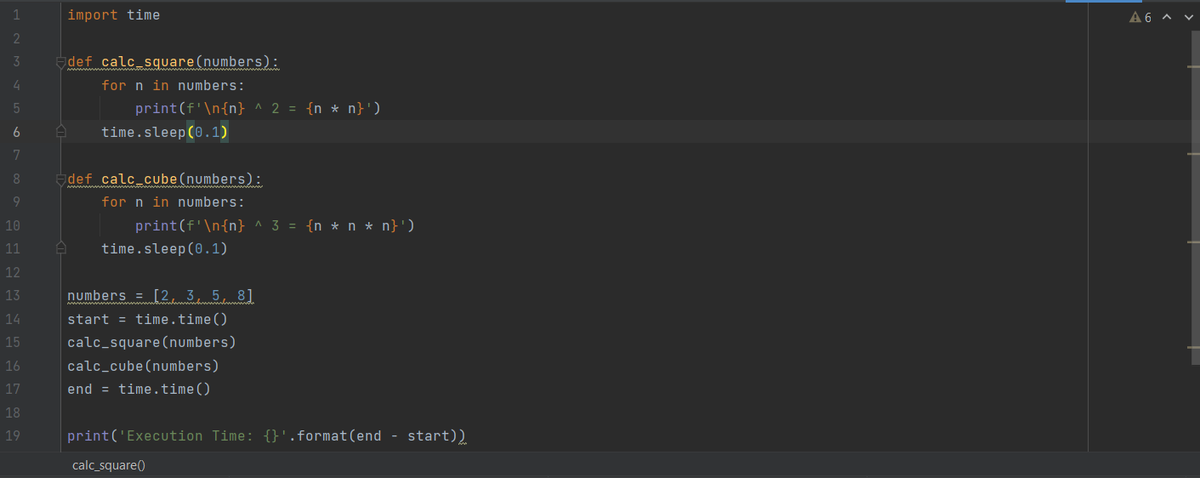
Выполнение данной программы у меня заняло почти одну секунду (0.884199857711792).
Теперь давайте используем возможности многопоточности для более эффективного использования времени процессора и сократим общее время выполнения задач. Многопоточность позволяет распределять процессорное время между различными задачами, что особенно полезно, когда некоторые из них блокируются в ожидании ответа от устройств ввода-вывода. Это обеспечивает более плавную и быструю работу системы. Давайте разберём, как это работает:
import threading
import time
def calc_square(numbers):
for n in numbers:
print(f'\n{n} ^ 2 = {n*n}')
time.sleep(0.1)
def calc_cube(numbers):
for n in numbers:
print(f'\n{n} ^ 3 = {n*n*n}')
time.sleep(0.1)
numbers = [2, 3, 5, 8]
start = time.time()
square_thread = threading.Thread(target=calc_square, args=(numbers,))
cube_thread = threading.Thread(target=calc_cube, args=(numbers,))
square_thread.start()
cube_thread.start()
square_thread.join()
cube_thread.join()
end = time.time()
Время выполнения программы - 0.42953968048095703, результат значительно улучшился. Детально разберем код.
Для начала нам необходимо импортировать модуль threading — высокоуровневый инструмент для многопоточного программирования.
Мы используем класс thread для создания экземпляров потоков. В нашем примере этот класс принимает два параметра: имя функции, которая будет выполняться в новом потоке (target), и аргументы для этой функции, передаваемые в виде кортежа (args). Когда мы создаём экземпляр класса thread, он автоматически запускает процесс создания нового потока, но этот поток не начинает выполнение немедленно — это важная особенность синхронизации, которая позволяет отложить запуск потоков.
Чтобы запустить поток и начать выполнение задачи, необходимо отдельно вызвать метод start для каждого созданного экземпляра потока. Таким образом, эти две строки кода запускают процессы вычисления площади и объёма параллельно:
square_thread.start()
cube_thread.start()
Последнее, что нам нужно сделать, — это вызвать метод join, который сообщает одному потоку, что нужно подождать, пока другой поток завершит выполнение:
square_thread.join()
cube_thread.join()
Пока функция calc_square() приостанавливается на 0,1 секунды благодаря методу sleep, функция calc_cube() продолжает выполняться, выводя куб каждого значения из списка, после чего также переходит в режим ожидания. Затем управление передаётся функции calc_square(), и процесс повторяется.
Таким образом, операционная система эффективно распределяет ресурсы процессора, переключаясь между задачами и выполняя их по очереди, что в конечном итоге способствует сокращению общего времени выполнения программы.
Модуль threading в Python предлагает множество удобных функций, которые помогут вам легко управлять многопоточными программами. С его помощью вы можете создавать потоки, контролировать их выполнение и синхронизировать их работу. Давайте разберем некоторые возможности:
Многопоточность представляет собой фундаментальную концепцию в области продвинутого программирования, направленную на создание высокопроизводительных приложений. В этом разделе мы ознакомились с основами многопоточности в Python. Мы рассмотрели базовую терминологию параллельных вычислений и реализовали простое многопоточное приложение для вычисления квадратов и кубов чисел из списка. В дальнейшем мы планируем обсудить более сложные и продвинутые техники многопоточного программирования.
GIL и асинхронный код
Asyncio предоставляет мощный цикл обработки событий, который является основой для эффективного управления асинхронными задачами. Этот цикл отслеживает различные события ввода-вывода и автоматически переключается между готовыми задачами, приостанавливая выполнение тех, которые ожидают завершения ввода-вывода. Такой подход позволяет рационально использовать ресурсы процессора и не тратить время на задачи, которые в данный момент не могут быть выполнены.
Как это работает:
- Цикл обработки событий: основной элемент, который координирует выполнение асинхронных задач.
- Функции асинхронных операций: мы передаем циклу обработки событий функции, которые выполняют асинхронные операции, такие как сетевые запросы или работа с файлами.
- Future объекты: взамен переданных функций цикл обработки событий возвращает Future объект, который служит обещанием, что результат будет доступен в будущем. Мы можем “удерживать” это обещание и проверять его на готовность, когда это необходимо.
- Генераторы и сопрограммы: asyncio использует генераторы и сопрограммы для управления приостановкой и возобновлением задач. Это позволяет коду выполняться асинхронно, не блокируя основной поток.
Для примера перепишем нашу программу вычисления кубов и квадратов чисел из списка:
import asyncio
import time
async def calc_square(numbers):
for n in numbers:
print(f'\n{n} ^ 2 = {n * n}')
await asyncio.sleep(0.1) # Имитация асинхронного ожидания
async def calc_cube(numbers):
for n in numbers:
print(f'\n{n} ^ 3 = {n * n * n}')
await asyncio.sleep(0.1) # Имитация асинхронного ожидания
async def main():
numbers = [2, 3, 5, 8]
start = time.time()
# Запуск асинхронных задач
square_task = asyncio.create_task(calc_square(numbers))
cube_task = asyncio.create_task(calc_cube(numbers))
# Ожидание завершения обеих задач
await square_task
await cube_task
end = time.time()
print(f'Execution Time: {end - start}')
# Запуск асинхронной программы
if __name__ == "__main__":
asyncio.run(main())
Продолжительность работы программы 0.42873263359069824 - результат практически такой же, как и у программы с многопоточным кодом. Это еще раз подчеркивает важность понимания различных моделей параллелизма при принятии решений по оптимизации кода.
Разберем код подробнее, импорт модулей:
asyncio: основной модуль для работы с асинхронными операциями.
time: модуль для работы с временем, используется для измерения времени выполнения программы.
Определение асинхронных функций:
async def calc_square(numbers):
for n in numbers:
print(f'\n{n} ^ 2 = {n * n}')
await asyncio.sleep(0.1) # Имитация асинхронного ожидания
async def calc_cube(numbers):
for n in numbers:
print(f'\n{n} ^ 3 = {n * n * n}')
await asyncio.sleep(0.1) # Имитация асинхронного ожидания
calc_square и calc_cube — это асинхронные функции, которые вычисляют квадраты и кубы чисел из списка numbers.
Внутри каждой функции используется цикл for для перебора чисел.
Оператор await asyncio.sleep(0.1) используется для имитации длительной операции (например, сетевого запроса или работы с базой данных), чтобы показать, как асинхронный код может выполнять другие задачи во время ожидания.
Определение главной функции:
async def main():
numbers = [2, 3, 5, 8]
start = time.time()
# Запуск асинхронных задач
square_task = asyncio.create_task(calc_square(numbers))
cube_task = asyncio.create_task(calc_cube(numbers))
# Ожидание завершения обеих задач
await square_task
await cube_task
end = time.time()
print(f'Execution Time: {end - start}')
main — это главная асинхронная функция, которая координирует выполнение всех задач.
start = time.time() — начало отсчета времени выполнения программы.
square_task и cube_task — это асинхронные задачи, которые запускают функции calc_square и calc_cube соответственно.
Оператор await square_task и await cube_task используется для ожидания завершения обеих задач перед завершением программы.
end = time.time() — конец отсчета времени выполнения программы.
print(f'Execution Time: {end - start}') — вывод времени, затраченного на выполнение программы.
Запуск асинхронной программы:
if __name__ == "__main__":
asyncio.run(main())
Условие if __name__ == "__main__": проверяет, запускается ли файл напрямую или импортируется как модуль.
asyncio.run(main()) запускает асинхронную функцию main().
Некоторые функции модуля asyncio:
asyncio.gather(*aws, loop=None, return_exceptions=False)
Позволяет выполнять несколько асинхронных задач параллельно и ожидать их завершения. Возвращает результаты выполнения всех задач или исключения, если таковые имеются. Пример:
results = await asyncio.gather(square_task, cube_task)
asyncio.wait(aws, loop=None, timeout=None, return_when='ALL_COMPLETED')
Используется для ожидания завершения нескольких задач одновременно. Возвращает результаты или исключения по завершении задач. Пример:
done, pending = await asyncio.wait([task1, task2])
asyncio.shield(aw, loop=None)
Защищает задачу от отмены. Позволяет обеспечить выполнение критически важной операции, несмотря на попытки её остановить. Пример:
critical_task = asyncio.shield(some_task)
Асинхронные функции позволяют выполнять длительные операции без блокировки основного потока, что улучшает производительность и отзывчивость программы. В данном примере функции calc_square и calc_cube выполняются параллельно благодаря использованию асинхронных задач и цикла обработки событий, предоставляемого asyncio.
GIL и многопроцессорный код
Из-за GIL многопоточное выполнение в Python не может эффективно использовать несколько ядер процессора для задач, связанных с интенсивными вычислениями. Однако, многопроцессорный подход позволяет обойти это ограничение, так как каждый процесс имеет свою собственную копию интерпретатора Python и, следовательно, свой собственный GIL.
Модуль multiprocessing в Python позволяет создавать и управлять процессами, которые выполняются параллельно и не ограничены GIL. Каждый процесс может использовать свои ядра процессора для выполнения задач, что значительно увеличивает производительность для вычислительно интенсивных задач.
Процессы в Python используют механизмы сериализации для обмена данными, так как каждый процесс имеет свою собственную память. Это может немного усложнить совместное использование объектов между процессами, но позволяет эффективно распределять вычислительные задачи.
Мы можем сделать многопроцессорную версию более эффективной, используя multiprocessing.Pool(p). Этот вспомогательный модуль Python создаёт пул процессов размером p. Если значение p не указано, по умолчанию будет использоваться количество ядер процессора в вашей системе, что в большинстве случаев является оптимальным выбором.
Использование Pool упрощает управление процессами и позволяет автоматически распределять задачи между ними. Это особенно полезно для параллельной обработки данных или выполнения CPU-bound задач, где важно задействовать все доступные ресурсы процессора.
Еще раз изменим нашу программу:
import multiprocessing
import time
# Функция для выполнения всех вычислений
def calc_all(n):
square = n * n
cube = n * n * n
print(f'\n{n}^ 2 = {square}, {n} ^ 3 = {cube}')
time.sleep(0.1) # Имитация задержки
return square, cube
if __name__ == "__main__":
numbers = [2, 3, 5, 8] # Уменьшил диапазон для наглядности
start = time.time()
# Создаем пул процессов
with multiprocessing.Pool() as pool:
# Применяем функцию calc_all к каждому элементу списка numbers
pool.map(calc_all, numbers)
end = time.time()
print(f'Execution Time: {end - start}')
Многопроцессорный код оказался наиболее эффективным в вычислениях и время работы программы составило - 0.3527061939239502.
Разберем код подробнее, импорт модулей:
import multiprocessing
import time
multiprocessing: модуль, который позволяет создавать и управлять процессами для выполнения параллельных задач.
time: модуль для работы с временем, используется для измерения времени выполнения программы.
Функция для вычислений:
def calc_all(n):
square = n * n
cube = n * n * n
print(f'\n{n}^ 2 = {square}, {n} ^ 3 = {cube}')
time.sleep(0.1) # Имитация задержки
return square, cube
calc_all — это функция, которая выполняет вычисления квадрата и куба числа.
Она принимает один аргумент n и вычисляет его квадрат и куб.
Оператор print выводит результаты с новой строки для каждого числа.
time.sleep(0.1) используется для имитации длительной операции, чтобы показать, как процессы могут выполняться параллельно.
Функция возвращает результаты вычислений.
Основная программа:
if __name__ == "__main__":
numbers = [2, 3, 5, 8] # Уменьшил диапазон для наглядности
start = time.time()
# Создаем пул процессов
with multiprocessing.Pool() as pool:
# Применяем функцию calc_all к каждому элементу списка numbers
pool.map(calc_all, numbers)
end = time.time()
print(f'Execution Time: {end - start}')
Условие if __name__ == "__main__": проверяет, запускается ли файл напрямую или импортируется как модуль. Это необходимо для корректного создания пула процессов.
start = time.time() — начало отсчета времени выполнения программы.
Создание пула процессов с помощью multiprocessing.Pool(). Пул процессов позволяет эффективно распределять задачи между доступными ядрами процессора.
pool.map(calc_all, numbers) применяет функцию calc_all к каждому элементу списка numbers параллельно.
После завершения всех задач пул закрывается автоматически благодаря использованию конструкции with, что гарантирует корректное освобождение ресурсов.
end = time.time() — конец отсчета времени выполнения программы.
print(f'Execution Time: {end - start}') — вывод времени, затраченного на выполнение программы.
Благодаря созданию пула процессов и применению функции calc_all к каждому числу из списка, программа эффективно распределяет задачи между ядрами процессора, что позволяет значительно сократить время выполнения по сравнению с другими моделями параллелизма.
Некоторые функции модуля multiprocessing:
multiprocessing.Process(target, args, kwargs)
Используется для создания нового процесса. target — функция, которую нужно выполнить в новом процессе. args и kwargs — аргументы, передаваемые в целевую функцию. Пример:
square_process = multiprocessing.Process(target=calc_square, args=(numbers,))
cube_process = multiprocessing.Process(target=calc_cube, args=(numbers,))
multiprocessing.Pool(processes=None, initializer=None, initargs=())
Позволяет создавать пул процессов для выполнения параллельных задач. processes — количество процессов в пуле (по умолчанию используется количество доступных ядер процессора). initializer и initargs — функции и аргументы, которые будут вызваны при запуске каждого процесса в пуле. Пример:
with multiprocessing.Pool(4) as pool:
results = pool.map(calc_all, numbers)
multiprocessing.map(func, iterable, chunksize=None)
Применяет функцию func к каждому элементу итерируемого объекта iterable. Выполняет задачи параллельно в пуле процессов. chunksize — размер чанков, на которые разбивается iterable для обработки (по умолчанию используется размер, равный количеству процессов в пуле). Пример:
with multiprocessing.Pool() as pool:
results = pool.map(calc_all, numbers)
multiprocessing.current_process()
Возвращает объект Process, соответствующий текущему процессу. Аналог threading.current_thread(). Пример:
current_process = multiprocessing.current_process()
multiprocessing.active_children()
Возвращает список всех живых потомков текущего процесса. Вызов функции имеет побочный эффект присоединения к уже завершенным процессам. Пример:
children = multiprocessing.active_children()
multiprocessing.cpu_count()
Возвращает количество процессоров в системе. Это число может не соответствовать количеству процессоров, которые могут использоваться текущим процессом. Пример:
cpu_count = multiprocessing.cpu_count()
Заключение
Многопоточность:
Идеально подходит для быстрого ввода-вывода и задач с ограниченным числом соединений. Многопоточность хорошо подходит для операций, требующих интенсивного взаимодействия с вводом-выводом, при этом использование процессора минимально.
К недостаткам можно отнести то, что GIL ограничивает производительность для CPU-bound задач. Потоки используют общую память, что может привести к состоянию гонки (race conditions).
Asyncio:
Идеально подходит для медленного ввода-вывода и большого числа соединений. Asyncio с неблокирующим подходом ускоряет обработку медленных операций ввода-вывода и большого количества соединений, таких как долгие опросы или веб-сокеты.
Ограничения, не подходит для CPU-bound задач, требует переписывания кода с использованием async/await.
Многопроцессорность:
Идеально подходит для вычислительно сложных задач. Многопроцессорность распределяет вычислительную нагрузку между ядрами процессора, ускоряя выполнение задач, требующих интенсивных вычислений.
Высокие накладные расходы на создание процессов и сложность синхронизации и обмена данными между процессами следует отнести к недостаткам
Ваши лайки и подписки мотивируют меня работать еще усерднее и радовать вас новым контентом. Вместе мы сможем сделать этот канал настоящим источником полезной информации!
Спасибо за вашу поддержку! 😊