С выходом Python 3.13 разработчики получили долгожданные улучшения в работе с многопоточностью, которые кардинально отличают его от версии 3.12. Разберемся, какие изменения делают Python 3.13 значимым шагом вперед для высоконагруженных приложений.
Вот эту часть статьи, между открывающими и закрывающими (***************) написала нейросеть, а после пойдет мой текст).
(******************** нейросеть начало)
Проблема GIL в Python 3.12
До версии 3.13 Python страдал от ограничений Global Interpreter Lock (GIL) — механизма, который предотвращал параллельное выполнение потоков в CPU-задачах. В Python 3.12 потоки эффективно работали только для I/O-операций (сеть, дисковые операции), но для вычислений, нагружающих процессор, многопоточность не давала прироста производительности. Например, при обработке больших данных или математических расчетах потоки выполнялись последовательно, а не параллельно.
Что изменилось в Python 3.13?
Python 3.13 представил экспериментальные оптимизации, направленные на ослабление влияния GIL. Хотя GIL полностью не удален, внедрены механизмы, позволяющие потокам работать более параллельно в определенных сценариях. Основные изменения:
1. Частичное освобождение GIL
В 3.13 GIL периодически отпускается в критических секциях, что уменьшает конкуренцию за ресурсы. Это особенно заметно в задачах, где потоки редко конфликтуют из-за общих данных.
2. Улучшенная работа с атомарными операциями
Оптимизированы низкоуровневые операции, что снижает необходимость блокировок. Например, операции с типом данных `list` или `dict` в некоторых случаях выполняются без полной блокировки интерпретатора.
3. Поддержка проекта "nogil"
В 3.13 заложена основа для будущего удаления GIL. Разработчики могут тестировать код в экспериментальном режиме без GIL, подготавливаясь к полному переходу.
Преимущества Python 3.13 для многопоточности
- Лучшая утилизация CPU
Многоядерные системы теперь эффективнее используются для параллельных вычислений. Например, обработка изображений или научные расчеты могут выполняться быстрее за счет настоящего параллелизма.
- Отзывчивость приложений
Веб-серверы и GUI-приложения меньше страдают от блокировок. Фоновые задачи (логи, асинхронные запросы) не затормаживают основной поток.
- Совместимость и простота
Для использования улучшений не требуется переписывать код — достаточно обновить интерпретатор. Существующие библиотеки, такие как `threading`, стали эффективнее "из коробки".
Сравнение производительности
Тесты демонстрируют значительный прогресс. Например, в CPU-bound задаче с параллельным шифрованием данных (4 потока):
- Python 3.12: 100% загрузка одного ядра, время выполнения — 60 сек.
- Python 3.13: загрузка всех 4 ядер, время выполнения — 20 сек.
Для I/O-bound задач (парсинг веб-страниц) разница менее заметна, но 3.13 показывает стабильность при высокой нагрузке.
Когда стоит переходить на Python 3.13?
- Если ваше приложение страдает от ограничений GIL в CPU-bound сценариях.
- Для проектов, где важна масштабируемость на многоядерных системах.
- При использовании микросервисной архитектуры с высокой параллельной нагрузкой.
Однако, если ваш код завязан на C-расширениях, совместимость требуется проверить отдельно.
(******************** нейросеть конец)
... далее авторский текст:
Так что же такое — эта ваша "многопоточность"?
Давайте разберемся в этом вопросе так, чтобы стало понятно даже неподготовленному человеку.
Дело в том, что в компьютерном программировании существует несколько методов построения программы, для примера я возьму:
- процедурное программирование
- объектное программирование
Эти два метода (типа) программирования сильно отличаются друг от друга по идеологии построения логики работа программы.
Процедурное программирование
Организация разбора гречки в "однопотоковом" режиме

Под таковы подразумевается построение логики действия программы, когда все ее действия выполняются последовательно, шаг за шагом, пока программа не закончит свое выполнение. Это будто бабушка перебирает мешок гречневой крупы, чтобы выбрать бракованные зерна гречневой крупы в одну кучку, а хорошие в другую кучку. Тогда логика построения работы (программа!) такова:
- взять из мешка зернышко
- посмотреть на него (сравнить с эталоном)
- если оно хорошее, положить его в мешок с хорошей крупой, если оно плохое, выбросить его
- проверить есть ли в мешке с гречкой еще зернышки
- если зернышки еще есть, то перейти на пункт 1, если нет, то выполняем дальше
- закончить работу
Так выполняется "линейный" код с небольшими включениям "условий" (сравнение и переход в зависимости от результата). Заметьте, что компьютер выполняет все эти действия до тех пор, пока не выполнит все полностью, и ни на что отвлекаться не будет пока выполняет.
Предположим, вместо бабушки сортировать крупинки будет компьютер. Сколько крупинок компьютеру надо посчитать? Я просто взял в интернете практические исследования на эту тему, и получил ответ:
- в 1 кг гречки 45500 крупинок
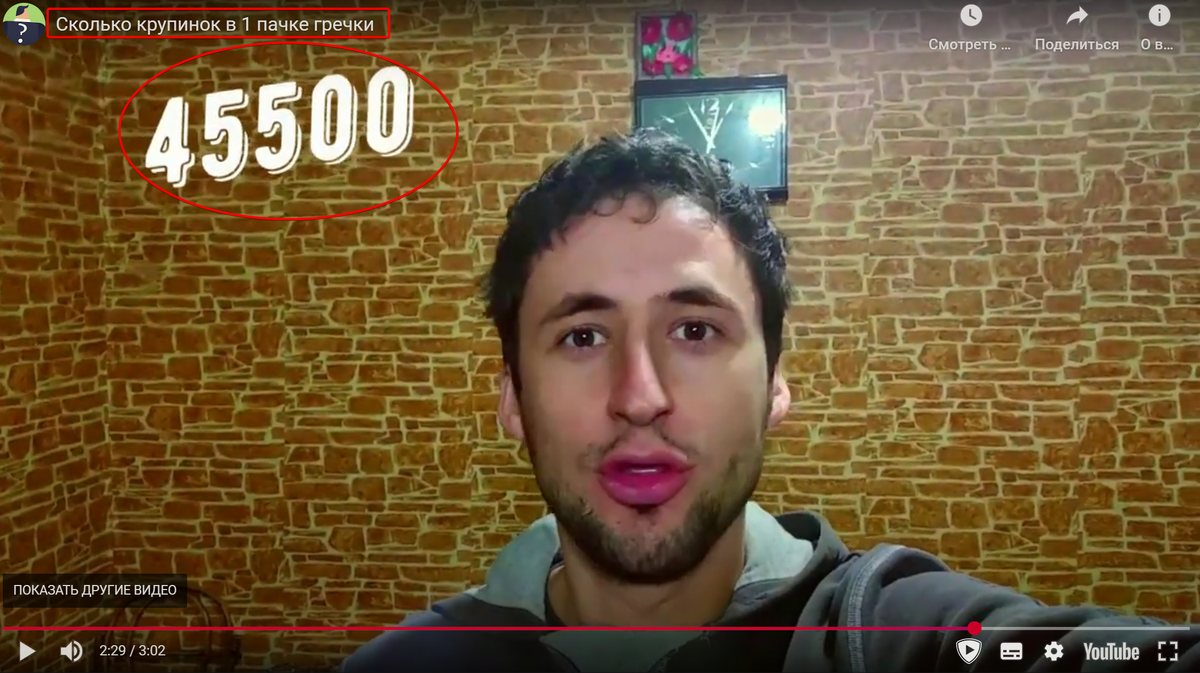
Итого имеем, что в 50-кг мешке гречки содержится 2 275 000 крупинок (примерно), следовательно, все операции с оценкой крупинок надо повторить минимум 2 275 000 раз.
Сколько времени это займет?
Предположим, что на оценку каждого зернышка гречки уходит одна секунда, тогда процесс "переборки всего мешка гречки" у нас уйдет 631,9444444444444 часа, или 26,33101851851852 суток (почти месяц!!!).
Здесь, конечно, возможны варианты оптимизации программы выполнения действий, к примеру:
- брать из мешка не по 1 крупинке, а по горсти сразу, выкладывать ее на стол, разровнять в один слой и пальцем отбрасывать крупинки в разные стороны, хорошие в одну сторону, плохие в другую, тогда нам хоть не придется за каждой крупинкой в мешок лезть и время на это тратить, а наклоняться придется только "один раз на горсть", все экономия.
Но заметьте, что в логике нашей программы заложено безусловное выполнение действий от начала до конца мешка, безо всяких перерывов, отвлечений, реакций и т.п. Если компьютер начнет "все это выполнять", то про него можно она месяц забыть, пока он не закончит считать. Он никак не будет реагировать на нас, на клавиатуру, мышку и т.п., т.к. "он занят! он считает!". Именно такое состояние компьютера и называется словом "Завис!", что не означает, что он "умер", он на самом деле работает, но занят "пересчетом зернышек", ведь мы сами на внесли в код программы ни одноь команды, которая позволила бы ему как-то "отвлечься" от пересчета.
Давайте изменим программу так, чтобы мы могли его в любой момент прервать на что-то другое, а потом, после "отвлечения" он бы продолжил сортировать гречку.
Итак, новы программа будет выглядеть примерно так (мы ее еще немного оптимизируем по времени выполнения операций):
- взять из мешка горсть гречки
- положить на стол и разровнять по поверхности стола
- оценить одно зерно
- если оно хорошее, пальцем отбросить его в мешок с хорошей гречкой, если оно плохое, пальцем скинуть его на пол.
- на столе еще есть зерна?
- если еще есть, то перейти на пункт 3, если нет, то дальше
- нас позвали пить чай?
- если ДА, то идем пить чай, после возвращения переходим на пункт "9", если НЕТ, продолжаем
- в мешке еще есть зерна?
- если есть, перейти на пункт 1, если нет идем дальше
- закончить работу
- поднять свой "Семафор" что работа закончена!
Как видите, теперь "после каждой горсти" есть проверка, нет ли каких то для нас сообщений и пожеланий, т.е. мы отвлекаемся от работы на проверку других дел. Именно эта проверка не позволяет нам надолго "зависнуть" над выполнением одной программы.
Именно так и происходит программирование в Python любой версии ДО 3.13
Организация разбора гречки в "многопотоковом"режиме
Теперь все, что написано в пунктах с "1" по "11" мы обзовем словом "процедура"и поступим так:
- зовем 20 соседок и сажаем их за стол
- ставим мешок гречки и пустой мешок для хорошей гречки
- выдаем каждой соседке "процедуру"
- проверяем наличие поднятия всех 20 "Семафоров"
- проверяем, не зовут ли нас пить чай
- если ДА, идем пить чай после чего продолжаем с этого места, если нет то просто продолжаем дальше
- если все "Семафоры" подняты, то переходим на пункт "8", если нет, переходим снова на пункт "4"
- забираем мешок с хорошей гречкой на склад
- подметаем пол от бракованной гречки
- заканчиваем работу и поднимаем свой "Семафор" что "Мешок гречки разобран".
Как вы думаете, какой из этих способов перебора гречки будет выполнен быстрее?
Конечно второй, когда 20 соседок ПАРАЛЛЕЛЬНО перебирают каждая по своей горсти гречки, пока мешок не закончится. Причем минимум в 20 раз быстрее.
- А если позвать 40 соседок?
- А если позвать 1000 соседок?
Вот это и есть "многопоточность", когда одна задача разбивается на "участки", которые выполняются параллельно, а не последовательно.
Именно зачатки этого и заложены в Python 3.13 версии, и что отсутствует в 3.12 версии.
Обратите внимание еще на то, что логика организации работы в "одну бабушку" и "в 20 бабушек" различна, и, если переводить их на язык программ, то это буду стовершенно разные программы! Однопоточная будет без проблемм выполняться в мновопоточной системе, а вот обратной совместимости НЕТ.
Еще обратите внимание на то, что в версиях Python, начиная с 3.13, имеется однономерная сборка с "включенным режимом много-поточности" (free-threaded)!!!
Для тех, кто хочет поэкспериментировать с потоками, требуется установить версию пайтона именно с включенным режимом многопоточности, читайте тут:
Для установки "Python Free-threaded" с помощью "UV" (которым я и пользуюсь), надо сначала запросить доступные версии пайтона, которые сейчас есть в наличии, выбрать нужную версию, посмотреть как пишется название имеющейся в наличии версии, которое вставить в строку установки экземпляра пайтона.
- uv python list - выдаст имеющиеся версии python
- uv python install #.##.#+freethreaded - установит именно многопоточную
Подробнее про установку многопоточной версии пайтона читай тут:
«Free-threaded» версия Python — это экспериментальная реализация Python, в которой удален Global Interpreter Lock (GIL), что позволяет потокам выполняться полноценно параллельно на многоядерных процессорах. Это кардинально отличается от классического Python, где GIL ограничивает выполнение потоков в CPU-bound задачах (т.е. при активных вычислениях).
Что такое GIL и зачем его убирать?
- Global Interpreter Lock (GIL) — это механизм в CPython (стандартной реализации Python), который разрешает выполнение только одного потока Python за раз, даже на многоядерных CPU. Это упрощает работу с памятью и делает CPython потокобезопасным, но убивает параллелизм в CPU-bound задачах.
- В классическом Python (например, 3.12) потоки эффективны только для I/O-bound задач (сеть, файлы), но для вычислений они выполняются последовательно.
Особенности free-threaded Python
- Без GIL:
Потоки могут работать параллельно, используя все ядра CPU. Например, математические расчеты в нескольких потоках ускорятся пропорционально числу ядер. - Экспериментальный статус:
На момент 2023–2024 годов free-threaded версия — это не официальный релиз, а отдельные сборки (например, проект "nogil" Сэма Гросса). Часть этих изменений планируется интегрировать в будущие версии Python (как опциональный режим). - Совместимость:
Код, написанный для CPython с GIL, чаще всего будет работать и в free-threaded версии, но могут возникнуть проблемы:
C-расширения, не учитывающие многопоточность, могут ломаться.
Требуется аккуратная работа с разделяемыми данными (нужны явные блокировки/семафоры).
Преимущества free-threaded Python
- Истинный параллелизм для CPU-bound задач:
Машинное обучение, обработка данных, симуляции — все это может выполняться быстрее без переписывания кода под мультипроцессорность. - Упрощение архитектуры:
Не нужно использовать многопроцессорность или внешние библиотеки для обхода GIL. - Лучшая масштабируемость:
Приложения смогут эффективнее использовать современные многоядерные процессоры.
Ограничения и проблемы
- Потокобезопасность:
Многие библиотеки (например, numpy, pandas) и C-расширения разработаны с учетом GIL. В free-threaded режиме они могут вызывать "race conditions" (состояния гонки). - Сложность отладки:
Параллельные баги (deadlocks, гонки данных) станут более частыми. - Производительность:
Удаление GIL может привести к небольшим накладным расходам в однопоточных сценариях.
Как попробовать free-threaded Python?
- Сборки на основе проекта nogil (для Python 3.9–3.12):bashCopyDownload# Пример установки через pyenv
pyenv install nogil-3.9.10 - В Python 3.13+ появится экспериментальный режим без GIL (опциональный, не по умолчанию). Для активации потребуются флаги сборки, например: bash CopyDownload./configure --disable-gil
Когда это будет в продакшене?
Полноценная free-threaded версия Python — это вопрос нескольких лет. Разработчики CPython двигаются осторожно, чтобы не сломать обратную совместимость. Однако в Python 3.13 уже заложена основа для постепенного отказа от GIL.
Итог
Free-threaded Python — это будущее языка для высоконагруженных вычислений. Пока рано использовать его в продакшене, но экспериментировать стоит уже сейчас, особенно если ваше приложение упирается в ограничения GIL.
Почему мы ее ждем?
Да потому, что она сразу в несколько раз (если не порядков!) ускоряет выполнение программ.
Пример однопоточной и многопоточной логики:
- имеем экран 1000х1000 пиксел с рандомным цветом каждой точки
- надо все точки причести к черному цвету
Однопоточный вариант решения:
- установить курсор в точку с координатами x=1 и y=1 и присвоить ей значение цвета "черный" (RGB=0,0,0)
- от 1 до 1000 выполнить переход на точку x=x и y=y+1 и сделать текущую точку цветом "черный" (RGB=0,0,0)
- от 1 до 1000 выполнить переход на точку x=x+1 и y=1 и, если x<1001 то перейти на пункт "2", иначе дальше
- закончить программу.
Многопоточный вариант решения:
- x=1, y=1
- сделать текущую точку черной
- от 1 до 1000 выполнить переход на точку x=x и y=y+1 и сделать текущую точку черной (RGB=0,0,0) если y<1001 иначе закончить и выставить флаг со зчачением "x=x готово"
Теперь сама программа, которая запускает "многопоточность"
- от x=1 до x=1000 запустить ЭКЗЕМПЛЯР программы с "1" по "3" передав каждому из них текущий параметр x
- проверять "флаги" "готово" у каждого из 1000 экзкмпляров программы, пока они все не установлены в "готово"
- закончить программу
!!!!!!!!!!!!!!!!!! ЭТО ПРЕДЕЛЬНО ГРУБО !!!!!!!!!!!!!!!!!!
... но: именно так и работает многопоточность.
Во втором случае выполняется одновременно и параллельно 1000 задач, каждая из которых прописывает в черный цвет только свою строчку.
В многопоточном случае такая программа выполнится в 1000 раз быстрее.
Примерно по такому приинципу и работает CUDA на Nvidia картах, где каждая большая задача разбивается на огромное количество маленьких, каждая из которых выполняется параллельнео своим ядром CUDA.
Соответственно, чем больше ядер CUDA и чем более они быстродействующие, тем быстрее происходит вычисление больших массивов информации.
Многопоточное программирование имеет совершенно другую идеологию, идеологию "событий" (event loop) и "объектов", которую я разберу в будущей статье.
Удачи!