
Зачем нужен Whisper?
Зачастую, копирайтеры, работающие на потоке, хотят оптимизировать свой рабочий процесс, чтобы сэкономить время, которое тратится на написание и публикацию статей. Написать лонгрид своими руками "из мозга" это дело нескольких часов. Написать рерайт - тоже долго, но можно воспользоваться ChatGPT. Но что делать, когда вы нашли видео в Ютубе или ещё где-то, и хотите заимствовать контент, а перепечатывать текст на клавиатуре, да и потом ещё рерайтить, это вообще не вариант? Выход есть! Нейросеть Whisper!
Whisper - это нейросеть, разработанная компанией OpenAI, которая переводит аудио и видео файлы в текст. Исходный код и модели этой нейросети выложены в свободный доступ.
Грубо говоря, вы скачиваете и устанавливаете программу на свой ПК, запускаете, загружаете в неё медиафайл, и через несколько минут у вас готовый распознанный текст, с которым можно работать. Вам остаётся только отредактировать (причесать) этот текст, "руками" или GPT, добавить картинки (скриншоты, фото...), и отправлять готовую статью на публикацию.
В этой статье я расскажу, как установить нейросеть Whisper локально на свой компьютер и перевести, например, Mp3 аудио-дорожку из видео с ютуба в текст.
Важно! для быстрой работы Whisper нужна мощная видеокарта с большим объёмом видеопамяти (VRAM) или хороший многоядерный процессор. Но существуют аналоги, об этом в конце статьи.
Желательно иметь Nvidia RTX с 10 ГБ VRAM и больше.
Как Whisper понимает речь лучше человека
Whisper — это открытая модель искусственного интеллекта от OpenAI, созданная для распознавания и транскрибации речи. Её выпустили в сентябре 2022 года, и с тех пор она заслужила репутацию одного из самых точных инструментов в своей нише.
Ключевые особенности:
- Поддержка 99 языков — от английского и китайского до исландского и суахили.
- Умение работать с шумными аудиодорожками (например, запись с вечеринки или уличного интервью).
- Распознавание специфических терминов, имён и редких слов.
- Возможность не только переводить речь в текст, но и определять язык автоматически.
Пример: Загрузите аудио на хорватском с фоновым шумом моря — Whisper расшифрует его, даже если вы не знаете, на каком языке говорил спикер.
Как Whisper училась понимать речь?
Секрет модели — в её обучении. OpenAI использовала 680 000 часов размеченных аудиоданных с YouTube, подкастов, телефонных разговоров и даже радиопередач. Это в 100 раз больше, чем датасеты для предыдущих моделей!
Что это даёт?
- Модель знает акценты: от техасского английского до индийского варианта хинди.
- Понимает контекст: отличает «там» от «том» даже в неразборчивой речи.
- Распознаёт паузы, смех, кашель и другие невербальные звуки.
Интересно: Whisper умеет «думать» на нескольких языках одновременно. Например, если в аудио есть фразы на французском и немецком, она корректно переключится между ними.
Архитектура: Почему Whisper точнее конкурентов?
В основе модели — трансформерная архитектура, похожая на ту, что используется в ChatGPT. Но есть нюансы:
- Кодировщик (Encoder)
Преобразует аудиосигнал в «векторы» — математические представления звука.
Анализирует спектрограммы, чтобы выделить речь из шума. - Декодировщик (Decoder)
Превращает векторы в текст.
Использует контекстные подсказки: если в предложении звучит «яблоко», следующее слово, скорее всего, «съел», а не «космос».
Главное отличие от Google Speech-to-Text или Amazon Transcribe:
- Whisper — универсальная модель. Её не нужно дообучать под конкретный акцент или микрофон.
- Она работает оффлайн (если скачать веса модели), что важно для конфиденциальности.
Где Whisper применяется?
- Субтитры для видео
Сервисы вроде Descript и Otter.ai используют Whisper для автоматической расшифровки интервью и лекций. Точность достигает 95% даже без постобработки. - Голосовые помощники
Разработчики встраивают Whisper в приложения для управления умным домом или записи медицинских диагнозов. - Лингвистика и образование
Учителя анализируют произношение студентов, а антропологи расшифровывают записи на исчезающих языках. - Подкастинг
Например, подкаст Lex Fridman использует Whisper для генерации транскриптов 4-часовых эпизодов.
Сравнение с аналогами
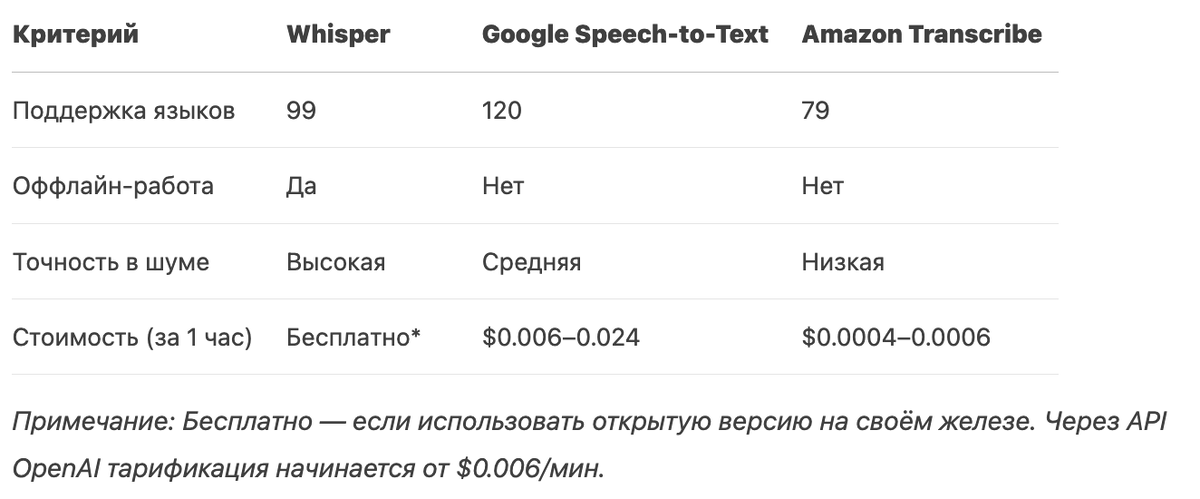
Как Whisper справляется с сложными задачами?
- Перекрывающаяся речь. Если два человека говорят одновременно, модель выделяет реплики по голосам (но пока не идеально).
- Музыка и звуки. Отфильтровывает фоновые треки, фокусируясь на словах.
- Сленг и диалекты. Распознаёт выражения вроде «чилить» или «краш» благодаря обучению на современных данных.
Пример запроса:
«Расшифруй аудио, где мужчина с шотландским акцентом рассказывает о квантовой физике под звуки дождя».
Ограничения модели
- Задержка. Обработка часовой записи может занять 2–3 минуты даже на мощном GPU.
- Пунктуация. Модель иногда ставит запятые или точки в странных местах.
- Специфические термины. Медицинские или технические названия требуют пост-редактуры.
- Реальное время. Для live-трансляции (например, Zoom-конференции) Whisper пока не идеальна.
Перейдём к установке Whisper на компьютер.
Необходимый SOFT для работы Whisper
Для работы нейросети (исходного кода) нужны некоторые библиотеки и среды разработки.
Python
Сначала нужно установить Python 3.11.4 или 3.10.11.
Ссылка на страницу скачивания https://www.python.org/downloads/release/python-3114/
Не забудьте поставить галочку здесь:
После установки "Питона", проверьте, версию через CMD, чтобы убедиться, что всё прошло успешно.
Запустите консоль сочетанием Win+R (Выполнить) или в поиске "CMD".
Пропишите команду "Python -- version" и нажмите Enter.
Всё, консоль отобразила версию Python, продолжаем.
PyTorch
Далее необходимо установить PyTorch https://pytorch.org/
Введите в консоль: "pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118"
Либо выберите CUDA 12.1, если у вас современная видеокарта и свежий драйвер и команда поменяется на: "pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121"
Если у вас видеокарта от AMD Radeon, то возможно, вам нужно будет выбрат CPU, то я не проверял... так что сами там...
"pip3 install torch torchvision torchaudio"
Если установка не запустилась, поменяйте "pip3" на "python -m pip"
FFmpeg
Теперь вам нужны автоматические сборки FFmpeg для того, чтобы ПО понимало разные форматы аудио и видео. Ссылка на GitHUB https://github.com/BtbN/FFmpeg-Builds/releases
Качаем архив
Разархивируйте файлы и перейдите в Дополнительные параметры системы (Свойства компьютера).
Нажимаем на кнопку Переменные среды.
Теперь нужно выбрать Путь до файлов Питона, кликаем на "Path", на кнопку Создать в появившемся окне и добавляем адрес папки, где лежат файлы FFmpeg.
Но можно сразу закинуть эти файлы в нужную папку с Питоном и не нервничать.
Для этого перейдите в Домашнюю папку (папка пользователя), там включите отображение скрытых файлов и папок. Должна появиться папка AppData.
Теперь идём до папки Scripts, у меня она находится по этому адресу:
C:\Users\Slava\AppData\Local\Programs\Python\Python310\Scripts
Туда закидываем все три файла FFmpeg.
Проверьте через CMD, введите "FFmpeg".
Если выдало такое, то всё хорошо.
Git
Теперь нужно установить Git. Переходим на официальный сайт и скачиваем.
После установки пропишите в Переменных средах пути Питона для папок bin и cmd Гита =)
В этом ничего сложного, на самом деле, нет.
Вот тут, если что, лежат эти папки.
Из свойств папки копируем путь и вставляем в Переменные среды, ну на скриншоте выше показал.
Проверяем через Командную строку:
Установка нейросети Whisper
Переходим к самому главному, загрузим исходники нейросети Whisper, чтобы начать с ней работать.
Вот ссылка на GitHub: https://github.com/openai/whisper
Но не качайте с него.
Загрузку выполним через консоль, чтобы все файлы сразу поместились куда нужно!
Даже на странице ГитХаба разрабы пришут, как правильно установить.
Введите в CMD эту команду: "pip install -U openai-whisper"
или "python -m install -U openai-whisper"
После процесса скачивания и установки проверьте, работает ли Whisper.
В CMD введите "Whisper -h" чтобы вызвать помощь по программе.
Как транскрибировать видео или аудио в Whisper
Для того чтобы распознать текст из медиа, нужно это медиа, прежде всего, скачать на комп.
Для примера возьмём любое короткое видео из YouTube.
Я нашёл видеоролик о настройке гитары. Его нужно скачать любыми способами на жёсткий диск. Я пользуюсь программой Freemake Video Downloader или онлайн сервисами типо ssyoutube.one
Но можете в Гугле поискать
Копируем ссылку на видео
Скачиваем видео или MP3
Если на каком-то сервисе есть возможность скачать аудиодорожку из видео, то это лучший вариант, который ускоряет работу.
Создайте папку, где вам удобно, перенесите в неё этот файл.
Переходим в эту папку и выделяем адрес в адресной строке.
Вводим "CMD" и нажимаем Enter.
Откроется командная строка (консоль) уже с адресом этой папки.
Теперь нам нужно запустить нейросеть Whisper, выбрать модель, которая нам будет транскрибировать текст из видоса, и дождаться окончания процесса.
Но перед этим давайте переименуем файл, чтобы с ним было удобно работать.
Пишем команду: "Whisper video1.mp4" и начнётся транскрибация.
Нейросеть натренерована и скомпонована в несколько моделей.
Если вы не указываете ничего то запускается модель Large (но это неточно), она же самая "умная" и хорошо транскрибирует, проставляет знаки препинания, и даже умеет определять спикеров.
Так что лучше пропишите: "whisper video1.mp4 --model large"
Чтобы нейросеть точно поняла, какую модель вы хотите задействовать!
Ух, моя видеокарта RTX 3080 загудела вентиляторами))
Автоматически распознаёт языки, с русским работает очень хорошо.
Если вы пропишите "Whisper video1.mp4 --model medium" то процесс транскрибации запустится на модели Медиум, которая работает быстрее, но текст распознаёт хужё.
Дождитесь завершения процесса, и вы сможете обнаружить в папке несколько текстовых файлов, с которыми можно будет дальше работать.
Whisper WebUI
Многим не по душе работать с командной строкой, и на этот случай есть сборка нейросети Whisper с Web-интерфейсом.
Скачать можно тут: https://github.com/jhj0517/Whisper-WebUI
Просто запустите файл установки и скрипт установит весь нужный софт и библиотеки за вас. Иными словами, вам не придётся проделывать тот сложный путь, о котором я писал ранее в статье.
Для запуска нейросети и интерфейса кликните дважды на файл start-webui
Откроется консоль, запустится локальный сервер для Web-интерфейса.
Перетащите аудио или видео в специальное поле сверху, или выберите через проводник.
Далее нужно указать модель large v2, которая работает лучше всех, и TXT файл для вывода.
Если у вас проблемы с транскрибацией на видеокартах AMD или вы хотите задействовать только процессор, то выбирайте CPU в графе Devices.
Нажимаем на Generate subtitle file. И нейросеть начнёт транскрибировать текст из видео.
Файл будет лежать в папке со сборкой под названием "outputs"
Установка Whisper через Pinokio
Есть отличный сервис, вернее некий софт, который сделан как журнал или браузер, где вы можете выбрать из списка любую нейросеть и в один клик установить себе на компьютер.
Главная страница https://pinokio.computer/
В интерфейсе приложения нажимаете на Visit Discover Page
И можете выбирать из списка то, что вам нужно.
Нас же интересует Whisper.
Автоматически загрузится весь необходимый софт и сборка нейросети с Web-интерфейсом, о котором я рассказывал ранее в статье.
Вам остаётся лишь нажать на кнопку и дождаться завершения.
Заключение.
Whisper - это очень полезный инструмент для копирайтеров, рерайтеров и контентмейкеров. Конечно, одно дело "вынуть" текст из видео, другое - это правильно его обработать, отредактировать и причесать.
А, я же обещал аналог Whisper скинуть, совсем забыл. Вот сервис: https://www.you-tldr.com/
Ещё можно установить Whisper в Google Colaboratory и использовать нейросеть в облаке, если у вас слабый комп, но об этом потом...
Если вы ещё не пробовали Whisper — самое время. Возможно, она избавит вас от часов рутинной работы, освободив время для творчества. Ведь будущее уже наступило — оно просто пока неравномерно распределено.
Подпишись, поставь лайк и поделись с друзьями!
Жмякни на колокольчик