Линейная регрессия имеет свой собственный набор допущений. Например, после моделирования, выходные данные могут быть отрицательными для некоторых входных величин. Порой такие результаты могут не иметь никакого смысла, например, в случаях предсказания количества забитых мячей в ворота противника или количества полученных входящих звонков и т. д.
Это связано с тем, что линейная регрессия не может моделировать количественные (или дискретные) данные, кроме того, для линейной регрессии определено, как постулат следующее:
- Ошибки распределяются равномерно вокруг среднего значения - по нормальному закону распределения.
- Следовательно, результаты по обе стороны от среднего значения (m-x, m+x) одинаково вероятны.
Например:
Если ожидаемое количество (среднее) полученных звонков равно 1, тогда, согласно правилу линейной регрессии, получение 3 звонков (1+2) имеет такую же вероятность, как и получение -1 звонка (1-2), что в данном случае противоречит здравому смыслу / см. рисунок ниже.
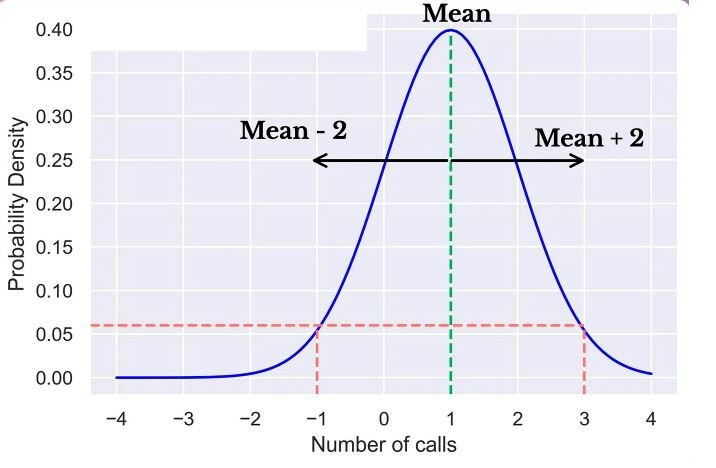
Поэтому, если приведенные выше постулаты не имеют смысла для вашей задачи, то линейная регрессия – это точно не ваш выбор.
Вместо линейной регрессии, в данном конкретном случае, прекрасно работает регрессия Пуассона:
- Подходит, если результат представляет собой счетные данные
- В основе модели лежит предположение о Пуассоновском распределении данных
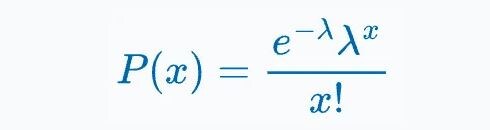
В отличие от линейной регрессии, регрессия Пуассона используется для моделирования данных, которые представляют собой счетные величины (например, количество звонков, число покупок, количество аварий и т.д.) и основаны на распределении Пуассона, которое имеет следующие свойства:
- Значения могут быть только неотрицательными целыми числами (0,1,2,…)
- Ошибки могут иметь асимметричное распределение вокруг среднего значения (λ)
- Следовательно, результаты по обе стороны от среднего значения (λ-x, λ+x) НЕ одинаково вероятны
Например:
Если ожидаемое количество (среднее) полученных звонков равно 1, тогда, согласно регрессии Пуассона, возможно получить 3 (1+2) звонка, но невозможно получить -1 (1-2) звонка / см. рисунок ниже.
Сделаем расчет вероятности наступления события:
- Среднее количество входящих звонков за один час равно 1.
- Какова вероятность того, что за один час будет получено ровно 3 входящих звонка?
Где:
- λ=1 (среднее число событий)
- x=3 (интересующее нас количество)
- e - константа (~2.718).
Подставляя данные в формулу распределения Пуассона (см. выше), получаем:
P(3) ≈0.06 или 6%.
Т.е. вероятность того, что за один час будет получено ровно 3 входящих звонка составляет 6%.
Распределение Пуассона — способ предсказать вероятность, когда что-то случается «редко».
В общем случае, если количество входящих звонков, зависят от многих факторов, то математически это будет выглядеть следующим образом:
Где:
- λ =E(Y∣X) - это ожидаемое значение Y (например, количество входящих звонков) зависящее от X (например, количество аварий на электросетях и дня недели).
- Ln (λ) - Логарифм обеспечивает, что λ будет >0 (положительный), при любых значениях X. ЭТО ВАЖНО!
- wi - веса (коэффициенты), которые модель обучается находить.
Эффективность регрессии Пуассона над линейной регрессией для данного типа задач очевидна из рисунка ниже:
Рассмотрим обобщающий пример, который позволит собрать все воедино:
Условия задачи:
- Y- среднее количество входящих звонков в день.
- X1 - количество аварий на электросетях в день (например, 3 аварии).
- X2 - день недели (1 — будний, 0 — выходной).
Известные коэффициенты модели:
- w1=0.4 (влияние аварий на звонки)
- w2=0.8 (влияние буднего дня)
Какова вероятность получить ровно 10 звонков в будний день, если произошло 3 аварии?
Шаг 1: Расчет λ = E(Y|X)
Подставляем значения в формулу:
ln(λ)=w1⋅X1+w2⋅X2=0.4⋅3+0.8⋅1=1.2+0.8=2.0
Находим λ:
λ= e2.0≈7.39 (ожидаемое среднее число звонков)
Шаг 2: Нахождение вероятности через распределение Пуассона
- λ=7.39 (ожидаемое среднее число звонков),
- Y =10 (интересующее нас количество звонков),
- e - константа (~2.718)
Находим P(10):
P(10) ≈0.082 или 8,2%
Интерпретация результатов:
- Ожидаемое среднее: ~7.39 звонков в будний день при 3 авариях.
- Вероятность ровно 10 звонков: составляет 8.2%, что возможно, но маловероятно.
Главные особенности применения регрессии Пуассона:
- Только для целых чисел
Подходит, когда считаем количество чего-то: звонков, аварий, покупок.
Нельзя использовать для дробных значений (например, вес или рост). - Чем чаще в среднем — тем сильнее разброс
Если в данных:
• среднее = 3, то типичные значения: 1-5,
• среднее = 10, то разброс будет 7-13.
Модель автоматически это учитывает. - Прогнозы — как "проценты"
Если коэффициент (w) = 0.2, это значит:
• увеличение X на 1 → рост числа событий на ~22% (т.к. e0.2≈1.22e0.2≈1.22).
Пример: больше рекламы (+1 пункт) → на 22% больше звонков.