Всем привет! Я — практикующий исследователь данных, и на этом канале делюсь тем, что реально работает в IT. Никакой сухой теории, только личный опыт, рабочие инструменты и грабли, на которые я уже наступил за вас. Рад, что вы здесь!
Сегодня расскажу о предварительном/разведочном анализе который в большинстве случаев позволяет оценить задачу/подтвердить вероятность или опровергнуть начальную гипотезу и т.д. В моей ежедневной практике, если разложить задачи по частоте, то можно выделить несколько типов задач:
1) Задачи от бизнеса (упала выручка по отношению к прошлым периодам, выяснить возможные причины и ответственных/вышел в продажу новый товар СТМ, проанализировать аналоги и написать рекомендации отделу маркетинга/и т.п.)
2) Внутренние задачи от отделов (выполнить сегментацию клиентов по периоду/сделать годовой-квартальный прогноз продаж по регионам для отдела розничных-оптовых продаж/посчитать новую метрику/разработать новый дашборд для отдела Х/и т.д.)
3) Задачи от внутренних пользователей и отладка ошибок (на дашборде неактуальная информация - выяснить и исправить/появились новые реквизиты в выгружаемых данных - поправить ETL/ошибки в Airflow - отработать/аварии на сервере и прочее, что послужило причиной каскадных ошибок, включаемся в работу с разработчиками и тестировщиками/и т.д.)
Первые две задачи почти во всех случаях требуют EDA.
Разведочный анализ данных (EDA, Exploratory Data Analysis) — это как первое свидание с датасетом: ты пытаешься понять, что за зверь перед тобой, стоит ли с ним связываться, и где могут быть подвохи. Без EDA ты как слепой котёнок, тыкающийся в данные, а с ним — уже детектив с лупой. Расскажу, как я делаю EDA, покажу простые куски кода на Python и поделюсь лайфхаками, которые упрощают жизнь в аналитике данных.

Предисловие: мой опыт с EDA
EDA - это просто синоним определенных действий (процесса), еще новичком я делал этот самый EDA, только никак его не называл или называл просто первичным анализом. И в моей статье я использую термин EDA только потому, чтобы ввести в контекст и привыкать называть вещи общепринятыми именами.
Скажу честно, первое время, на первой работе я часто грешил начиная с анализа и проверкой гипотез, без предварительного анализа данных (EDA). На первой работе было такое, что мне кинули выгрузку с бухгалтерской системы на 50 тысяч строк с продажами и сказали: "Найди, что не так". Я открыл, глаза разбежались, и через час я понял, что без системного подхода это ад. С тех пор EDA стал моим ритуалом: я не лезу в модели или дашборды, пока не разберусь, с чем имею дело. Мой опыт — это куча граблей, от пропущенных NaN до игнора выбросов, но теперь я в большей степени знаю, как не облажаться🙃.
Что такое EDA и зачем оно надо?
EDA — это процесс, где ты изучаешь датасет, чтобы:
- Понять структуру данных (что за столбцы, какие типы).
- Найти проблемы (пропуски, выбросы, ошибки).
- Выявить закономерности (корреляции, тренды).
- Решить, что с этим всем делать дальше (чистить, трансформировать, строить модель).
Без EDA ты можешь построить модель на мусорных данных и получить мусорный результат. Обычно после первичного анализа, постановщику задачи на "... прогноз продаж ..." приходится предупреждать о том, что "Мусор на входе - мусор на выходе", тогда уже приходится подключаться к сбору данных самому и это зачастую может затянуть задачу на долгий срок (но мы не об этом).
Мой подход к EDA: шаг за шагом
Вот как я делаю EDA, с примерами кода и пояснениями. Использую Python (pandas, matplotlib, seaborn). Датасет для примера — продажи интернет-магазина.
1. Загрузка и первый взгляд
Сначала загружаю данные и смотрю, что вообще в них есть.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Загружаем датасет
df = pd.read_csv('sales_rb.csv')
# Первые 5 строк
print(df.head())
# Общая инфа: типы данных, пропуски
print(df.info())
# Статистика по числовым столбцам
print(df.describe())
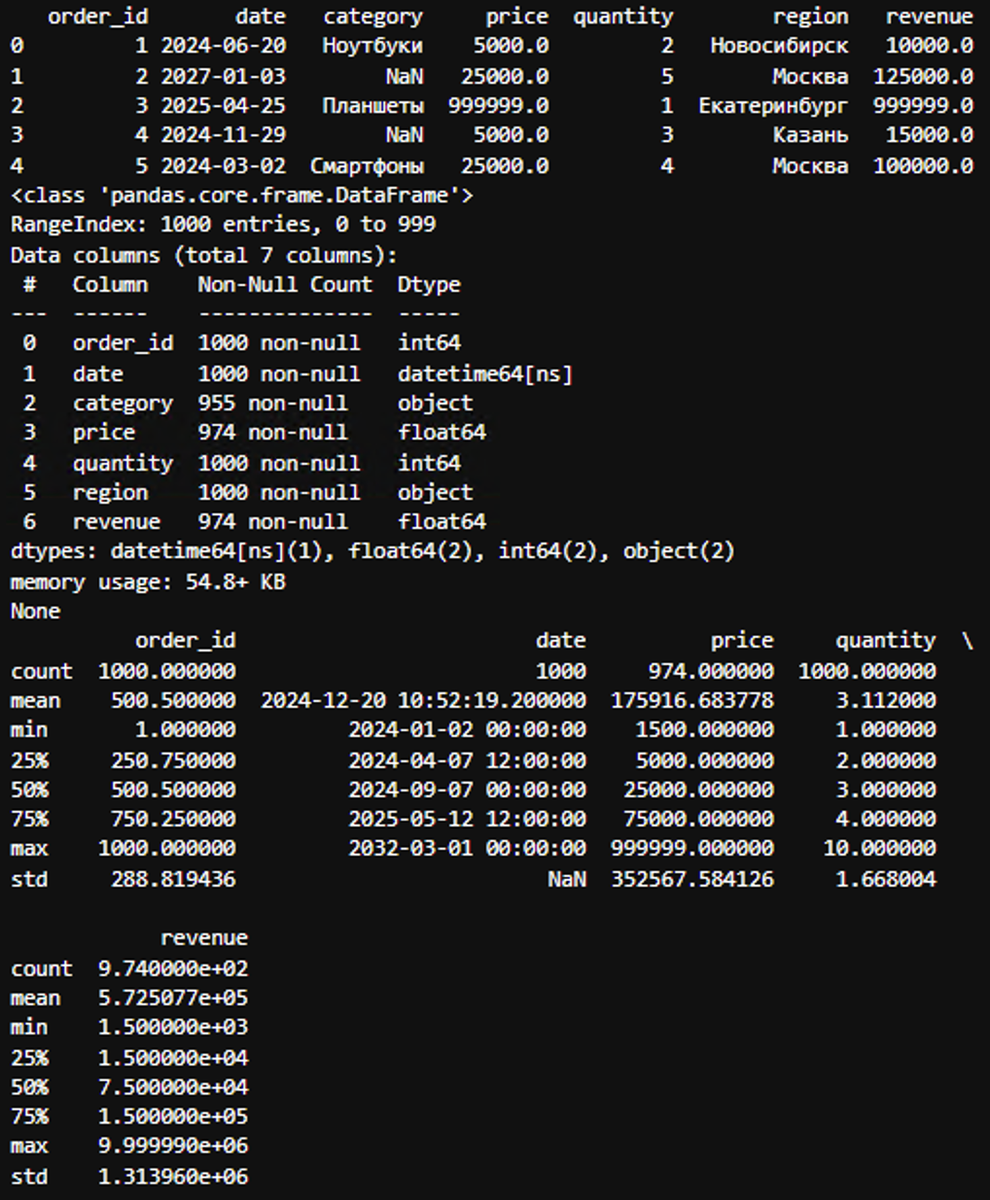
Что делаю:
- df.head() — показывает первые строки, чтобы понять, что за данные (например, столбцы: order_id, price, date, category).
- df.info() — выдаёт типы данных и количество непустых строк. Если вижу, что в столбце price 49000 non-null из 50000, значит, есть пропуски.
- df.describe() — даёт мин, макс, среднее, медиану. Если макс price = 999999, а среднее 100, — привет, выбросы!
2. Проверка пропусков
Пропуски — это бич любого датасета. Игнорировать их = подписаться на проблемы.
# Считаю пропуски
print(df.isnull().sum())
# Визуализация пропусков
sns.heatmap(df.isnull(), cbar=False, cmap='viridis')
plt.title('Пропуски в данных')
plt.show()
Что делаю:
- isnull().sum() — показывает, сколько NaN в каждом столбце. Если в category 10% пропусков, думаю, можно заполнить модой (самым частым значением). Если 80% — проще дропнуть столбец.
- Тепловая карта (heatmap) помогает увидеть, где пропуски сгруппированы. Если они случайные — ок, если в определённых строках — надо копать глубже.
Лайфхак: Если пропусков мало (<5%), я заполняю медианой для чисел или модой для категорий. Если много, спрашиваю бизнес: "Это баг или так задумано?" (НО, вообще лучше по каждым случаям если ты не шаришь пока в бизнес процессах, лучше советоваться с бизнесом, возможно где-то лучше поставить нули вместо средних или скользящих и т.п.)
3. Анализ распределений
Теперь смотрю, как данные распределены, чтобы понять их природу.
# Гистограмма для числовых столбцов
df['price'].hist(bins=30)
plt.title('Распределение цен')
plt.xlabel('Price')
plt.ylabel('Count')
plt.show()
# Боксплот для выбросов
sns.boxplot(x=df['price'])
plt.title('Боксплот цен')
plt.show()
Что делаю:
- Гистограмма показывает, нормальное ли распределение. Если price скошено вправо (много дешёвых товаров, мало дорогих), это нормально для продаж.
- Боксплот выявляет выбросы. Если вижу точки за пределами "усов" (например, price = 999999), проверяю, баг это или реальная люксовая покупка.
Лайфхак: Если выбросов много, не дропай их сразу. Проверь, может, это важные данные (например, крупные B2B-продажи, в моем случае мне данные попадают именно такие, где все продажи перемешаны, а дальнейшая работа - дело техники).
4. Корреляции и зависимости
Ищу, как столбцы связаны между собой.
# Корреляционная матрица
corr = df[['price', 'quantity', 'revenue']].corr()
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('Корреляции')
plt.show()
# Парный график для ключевых столбцов
sns.pairplot(df[['price', 'quantity', 'revenue']])
plt.show()
Что делаю:
- Тепловая карта корреляций показывает, какие столбцы "дружат". Если price и revenue коррелируют на 0.9, это ожидаемо. Если вдруг коррелируют те признаки которые не должны — копаю, что за фигня.
- pairplot даёт визуальную связь между переменными. Например, если quantity растёт, а revenue падает, это подозрительно.
Лайфхак: Не доверяй корреляциям слепо. Высокая корреляция ≠ причинность. Всегда проверяй бизнес-контекст.
5. Категориальные переменные
Для столбцов вроде category или region смотрю распределение.
# Количество по категориям
sns.countplot(x='category', data=df)
plt.title('Распределение по категориям')
plt.xticks(rotation=45)
plt.show()
Что делаю:
- Считаю, сколько раз встречается каждая категория. Если 90% продаж в категории одной, а в другой почти нет, это уже инсайт.
- Проверяю, нет ли ошибок (например, "Электроника" и "Электроникка" — опечатка).
6. Временные тренды
Если есть даты, анализирую тренды.
# Преобразуем дату
df['date'] = pd.to_datetime(df['date'])
# Продажи по месяцам
df.groupby(df['date'].dt.to_period('M'))['revenue'].sum().plot()
plt.title('Продажи по месяцам')
plt.xticks(rotation=45)
plt.show()
**не пугаемся годов, датасет я сгенерировал🥸
Что делаю:
- Группирую по месяцам/неделям, чтобы найти сезонность. Если продажи падают в декабре, это странно — надо копать.
- Проверяю аномалии: нулевые продажи в какой-то день — баг или выходной?
Частые грабли и как их избежать
- Игнор пропусков. Заполнил NaN нулями в price и получил среднюю цену 10 рублей. Всегда проверяй, что заполняешь.
- Слепая чистка выбросов. Дропнул "дорогие" заказы, а это были VIP-клиенты. Спрашивай бизнес, прежде чем удалять.
- Слишком много графиков. Не строй 50 визуализаций — хватит 3–5 ключевых, чтобы понять суть.
- Забыл сохранить выводы. Я раньше делал EDA и шёл дальше, а потом забывал, что нашёл. Теперь веду заметки: "20% пропусков в category, сильная корреляция price и revenue".
Лайфхаки для EDA
- Автоматизируй рутину. Используй библиотеки вроде pandas-profiling или ydata-profiling для быстрого отчёта по данным. Один код — и готовый HTML с графиками.
!pip install ydata-profiling
from ydata_profiling import ProfileReport
profile = ProfileReport(df, title="EDA Report")
profile.to_file("eda_report.html")
- Сохраняй код. Пиши EDA в Jupyter Notebook, чтобы потом вернуться и доработать.
- Задавай вопросы. EDA — это не просто графики, а поиск ответов. Почему продажи упали? Что влияет на цену?
- Не бойся простоты. Даже базовый анализ (гистограммы, корреляции) даёт кучу инсайтов.
Файл Jupyter Notebook со всем вышеописанным кодом тут.
Файл отчета eda_report.html тут.
Итоги
EDA — это твой первый шаг к тому, чтобы данные заговорили. Без него ты как повар, который готовит суп, не зная, что в кастрюле. Мой подход: загрузи, посмотри пропуски, проверь распределения, найди зависимости и запиши выводы. Это не rocket science, но спасает от кучи проблем.
Я не претендую на истину в последней инстанции, просто рассказываю, как иду по пути аналитика. Спасибо, что дочитали! 😎 Подписывайтесь 👇👇👇, лайкайте 👍🏽👍🏽, пишите в комментах пожелания, вопросы, замечания. Буду рад любой активности. Впереди разборы инструментов, навыков и IT-фишек!