Слышал, что большие языковые модели вроде GPT просто угадывают следующее слово? Это как назвать шахматиста «двигателем фигурок». Технически да, но суть глубже. Погнали разбираться, как работают LLM и почему они такие мощные.

Почему это не просто угадывание?
LLM не просто смотрят на текст и выдают слово. Они минимизируют ошибку через функцию потерь. Проще говоря, учатся быть точнее, а не тыкать пальцем в небо.
Логарифмические потери: как это работает
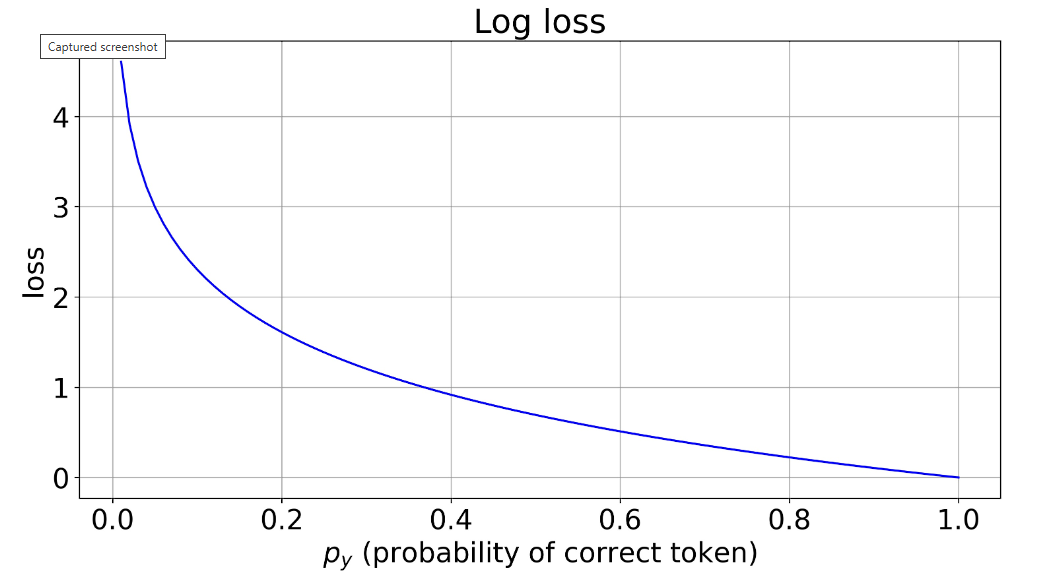
Модели используют логарифмические потери — это как штраф за промах. Уверен в слове? Потери маленькие. Ошибся? Получай штраф побольше.
Обучение с подкреплением — модель как игрок
LLM учатся с подкреплением, как собака за вкусняшки. Модель — агент, который получает «награду» за хорошие предсказания.
Как это устроено
Агент (модель) работает с данными (среда), делает предсказания (действия) и получает награду (меньше потерь). Со временем он понимает, что работает лучше.
Шахматы как пример важности контекста
Представь шахматную партию. LLM не выбирает случайный ход, а оценивает доску, как профи. Контекст решает всё.
Почему это круто
Модель видит весь текст, а не только последнее слово. Это как шахматист, который помнит ходы и строит стратегию.
Математика внутри
Для гиков: LLM оптимизируют выбор слов через градиентный спуск и вероятности. Чем меньше разница между ожидаемым и реальным, тем лучше.
График для понимания
Показывает, как потери зависят от расхождений между входом и выходом. Меньше разница — меньше ошибок.
Вывод
Большие языковые модели — это не просто «угадай слово». Они анализируют, учатся и планируют, как шахматные мастера. Их возможности огромны, и это только начало. Хочешь узнать больше? Пиши свои мысли в комментариях! 🚀