В последние годы распределенные системы и обработка данных в реальном времени стали неотъемлемой частью многих бизнес-процессов. Одним из самых популярных инструментов для работы с потоками данных является Apache Kafka. В этом посте мы разберем, что такое Kafka, как она работает и где может быть использована.
Что такое Apache Kafka?
Apache Kafka — это распределенная платформа для обработки потоков данных в реальном времени. Она была разработана в LinkedIn и в 2011 году была передана в Apache Software Foundation. Kafka позволяет передавать, сохранять и обрабатывать сообщения и события в реальном времени с помощью принципа, известного как публикация-подписка.
======================================================
Apache Kafka — распределённый программный брокер сообщений с открытым исходным кодом, разрабатываемый в рамках фонда Apache на языках Java и Scala. Цель проекта — создание горизонтально масштабируемой платформы для обработки потоковых данных в реальном времени с высокой пропускной способностью и низкой задержкой.
Основные компоненты Kafka:
- Брокеры (Brokers): Серверы, которые хранят данные и управляют их передачей. Kafka может состоять из одного или нескольких брокеров.
- Топики (Topics): Каналы, через которые передаются сообщения. Каждый топик можно рассматривать как отдельную категорию или поток данных.
- Производители (Producers): Приложения, которые отправляют сообщения в топики.
- Потребители (Consumers): Приложения, которые читают сообщения из топиков.
- Партиции (Partitions): Каждый топик может быть разбит на несколько партиций, что позволяет масштабировать и балансировать нагрузку.
Как работает Kafka?
Система Kafka организована на основе принципа «публикация-подписка». Производители отправляют сообщения в заданные топики, а потребители подписываются на эти топики и получают сообщения в режиме реального времени.
Kafka обеспечивает высокую производительность и надежность благодаря следующим особенностям:
Горизонтальное масштабирование: Вы можете добавлять новые брокеры в кластер, чтобы увеличить производительность и объем хранимых данных.
Устойчивость к сбоям: Посредством репликации данных между брокерами, Kafka обеспечивает сохранность сообщений даже в случае сбоя.
Сохранение сообщений: Kafka может хранить сообщения в течение определенного времени, что позволяет потребителям извлекать их в любое время.
Обработка в реальном времени: Kafka поддерживает обработку потоков данных с помощью Kafka Streams, что позволяет создавать сложные сценарии обработки в реальном времени.
Где используется Kafka?
Apache Kafka находит применение в различных областях:
- Журналирование событий: Многие компании используют Kafka для сбора журналов событий своих приложений и систем, что позволяет отслеживать действия пользователей и производить анализ данных.
- Аналитика в реальном времени: Системы, обрабатывающие данные в реальном времени, используют Kafka для передачи данных от источников к аналитическим инструментам.
- Интеграция данных: Kafka часто используется для соединения различных микросервисов и систем, обеспечивая обмен данными между ними.
- Мониторинг и алертинг: Системы мониторинга используют Kafka для сбора метрик и агрегирования информации о состоянии систем.
- Обработка потоков данных: Kafka Streams позволяет обрабатывать данные на лету, что полезно в задачах, требующих мгновенной реакции.
- Интернет вещей (IoT): Kafka может использоваться для обработки потоковых данных от множественных датчиков и устройств.
Kafka Streams
Kafka Streams (Streams API) — библиотека потоковой обработки данных, написанная на Java, добавлена в версии Kafka 0.10.0.0. Позволяет создавать в функциональном стиле приложения потоковой обработки данных с поддержкой агрегации, преобразования и анализа данных, получаемых из Kafka-тем.
Kafka Streams содержит предметно-ориентированный язык, включающий операторы, обеспечивающие фильтрацию, отображение, группировку, управление окнами, агрегацию и объединение данных. Кроме того, Processor API можно использовать для реализации пользовательских операторов для более низкоуровневого подхода к разработке. DSL и Processor API можно использовать совместно. Для потоковой обработки для сохранения состояния Kafka Streams использует RocksDB. Поскольку RocksDB может сохранять часть данных на диск, количество обрабатываемых данных может быть больше, чем доступная основная память. Для обеспечения отказоустойчивости все обновления локальных хранилищ также записываются в раздел в кластере Kafka. Это позволяет воссоздать состояние, прочитав эти разделы, и передать все данные в RocksDB.
Kafka Connect
Kafka Connect (или Connect API) — фреймворк для импорта данных из других систем и для экспортирования данных в другие системы. Его добавили в версии Kafka 0.9.0.0. Фреймворк Connect создаёт «коннекторы», которые реализуют логику чтения и записи данных во внешние системы. Connect API определяет программный интерфейс, для реализации отдельных библиотек под различные языки программирования. На большинство крупнейших языков программирования уже есть реализации API. При этом, компания Apache Kafka не занимается разработкой таких библиотек.
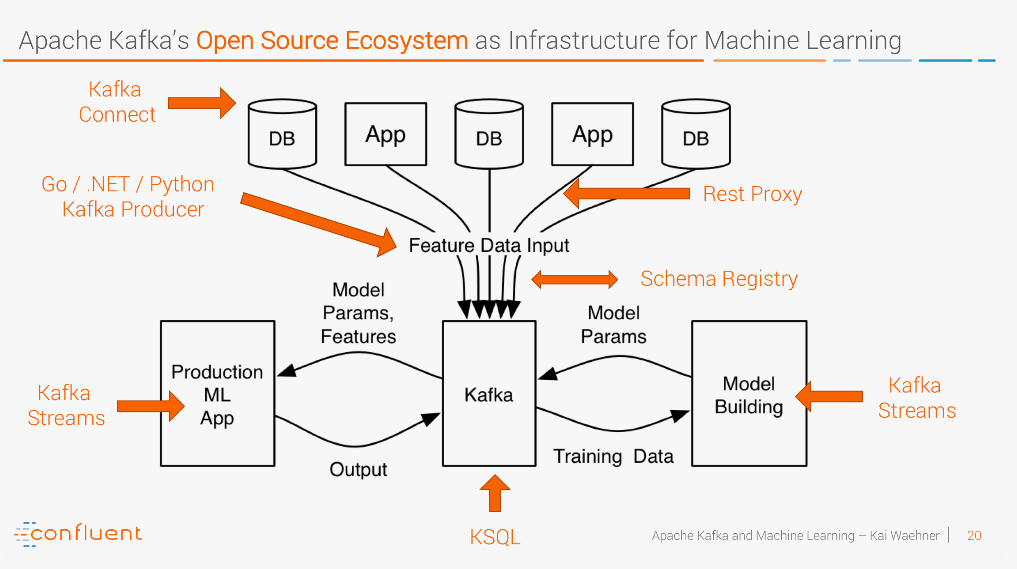
Эта схема иллюстрирует использование экосистемы Apache Kafka в качестве инфраструктуры для машинного обучения (ML).
Взаимодействие:
Данные из различных источников поступают в Kafka, где они структурируются (Schema Registry) и обрабатываются (Kafka Streams/KSQL).
Обучающие данные и параметры моделей передаются в ML-компоненты.
Готовая ML-модель интегрируется в продакшен-приложение, которое использует Kafka для ввода/вывода данных.
Итог:
Схема демонстрирует, как Kafka обеспечивает масштабируемую, надежную и реальновременную инфраструктуру для построения и эксплуатации ML-решений, объединяя данные, обработку и модели в едином потоковом конвейере.
Заключение
Apache Kafka — это мощная и гибкая платформа для обработки потоков данных, способная справляться с большими объемами информации в реальном времени. Она отлично подходит для самых различных сценариев использования и постепенно становится стандартом в мире современных распределенных систем. Если вы планируете работать с потоковыми данными или разрабатывать микро-сервисную архитектуру, изучение Kafka — это, безусловно, важный шаг на вашем пути.
