
Основная разница между моделями Mistral Large и GPT-4 заключается в их архитектуре, количестве параметров, производительности и стоимости использования.
Архитектура и параметры
Mistral Large: Эта модель является плотной трансформерной моделью с 7 миллиардами параметров. Она ориентирована на эффективность и высокую производительность в языковых задачах, но не достигает уровня GPT-4 в некоторых аспектах1.
GPT-4: В отличие от Mistral, GPT-4 использует архитектуру Mixture of Experts (MoE), которая включает около 1.8 триллиона параметров, из которых активируется только часть (около 280 миллиардов) во время вывода. Это позволяет модели более эффективно использовать ресурсы при обработке запросов2.
Производительность
Mistral Large: В тестах Mistral Large продемонстрировала хорошие результаты, особенно в области логики и многозначности, хотя в некоторых случаях она уступала GPT-4. Например, в сравнительных тестах Mistral Large показала себя чуть хуже в общем знании и логических задачах.
GPT-4: Эта модель считается одной из лучших на рынке, с высокой точностью в ответах на сложные вопросы и способностью к многомодальным задачам (например, обработка изображений). GPT-4 также имеет более высокий балл по критериям общего знания и меньшую склонность к галлюцинациям по сравнению с Mistral Large.
Стоимость использования
Mistral Large: Стоимость использования Mistral Large составляет примерно $0.008 за 1000 входящих токенов и $0.024 за выходящие токены, что делает её на 20% дешевле по сравнению с GPT-4.
GPT-4: Для GPT-4 стоимость составляет $0.01 за 1000 входящих токенов и $0.03 за выходящие токены. Таким образом, хотя Mistral Large дешевле, разница в производительности может повлиять на выбор модели для конкретных приложений.
Какие задачи лучше решать с помощью Mistral Large
Mistral Large, как новая языковая модель, подходит для решения ряда задач благодаря своим особенностям и производительности. Вот основные области применения, в которых Mistral Large может проявить себя особенно эффективно:
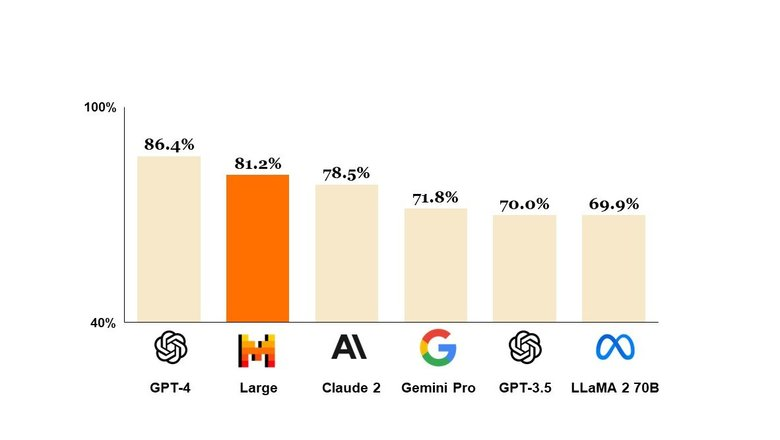
Задачи, подходящие для Mistral Large
Финансовый анализ: Модель продемонстрировала высокие способности в анализе сложных финансовых концепций. Например, в тестах она смогла правильно ответить на вопросы о теории факторного инвестирования, когда другие модели, такие как GPT-4, не смогли дать однозначный ответ.
Обработка естественного языка (NLP): Mistral Large обладает хорошими навыками в понимании и генерации текста на нескольких языках. Это делает её полезной для задач перевода и создания контента.
Логические задачи и рассуждения: Несмотря на то что Mistral Large уступает GPT-4 в некоторых аспектах логического мышления, она все же показывает достойные результаты в решении логических задач и может быть использована для создания тестов и викторин.
Образовательные приложения: Модель может быть полезна в образовательных целях, предоставляя объяснения и ответы на вопросы по различным темам. Она показывает способность к объяснению сложных концепций, что делает её подходящей для использования в обучающих платформах.
Создание чат-ботов: С учетом своей способности к многозначности и пониманию контекста, Mistral Large может быть интегрирована в чат-боты для улучшения взаимодействия с пользователями.
Преимущества использования Mistral Large
Доступная стоимость: Стоимость использования Mistral Large ниже по сравнению с GPT-4, что делает её более привлекательной для разработчиков и компаний с ограниченным бюджетом.
Широкий контекст: Модель поддерживает контекст окна до 32k токенов, что позволяет обрабатывать более длинные запросы и поддерживать более глубокие беседы.
В заключение, Mistral Large является многообещающей моделью для различных приложений в области обработки языка и анализа данных. Её сильные стороны делают её особенно полезной в финансовом анализе, образовании и создании интерактивных приложений.
Полезные ссылки:
AI Lab в Telegram @itinai — бесплатная консультация по ИИ-продуктам aihlp Сервис по подбору AI-роботов для бизнеса