Немного подробнее про форматы файлов .0 .1 .10 .11. Эти файлы просто перечень данных разбитых на что либо, ну и для простоты стандартным методом для себя я определяю пробел или 0x20, U+0020. Тобишь file.0 - это иероглифы, эмоджи, синапсы которые контекстуально значимы в последовательности. Примером может служить emmet: div>(header>ul>li*2>a)+footer>p, который ускоряет работу и развёртывание программы, также есть регулярные выражения к примеру /.*\/, которые также значительно ускоряют работу. Тобишь file.0 это тот файл где нет пробелов и всё идёт контекстом.
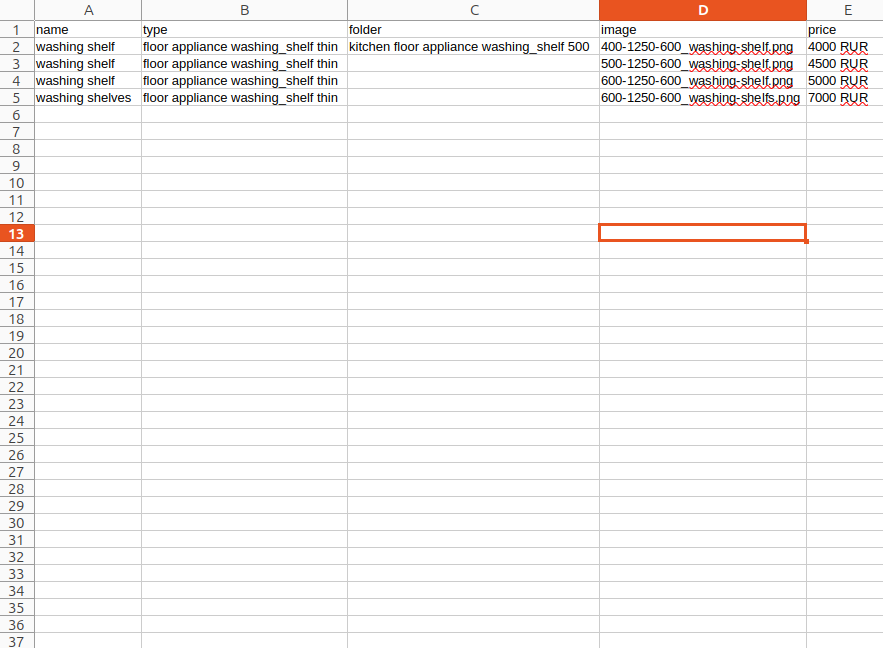
file.1 - это файл с уникальными идентификаторами между одним промежутком. К примеру из приведённого .csv файла: "floor appliance washing_shelf thin", где это уже как бы формат Array ["floor","appliance","washing_shelf","thin"], что очень удобно, но бывают случаи когда это не столь ясно и "washing_shelf" к примеру это 2 слова через пробел и чтобы не потерять контекстуального значения то проще убрать пробелы дабы программа не запуталась действуя изначально заданой логике.
file.10 - это уже файл с разбиением дважды, ну и весьма удобно делать нечёт. Тоесть 3 пробела, в любом случае это бóльшая редкость:
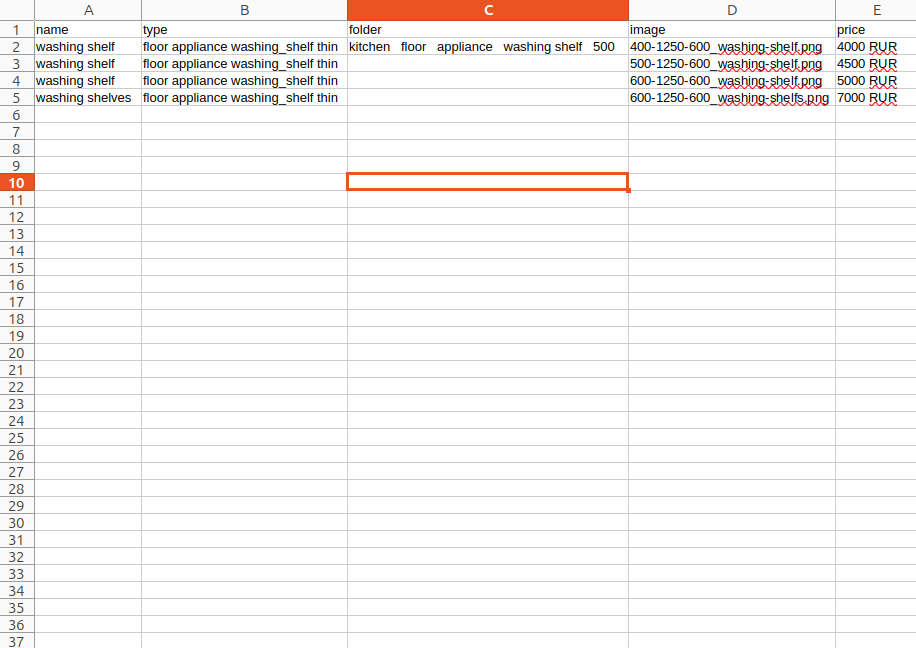
3 пробела это то что может сохранить значимость даже если передаётся пустое значение например "1","","2" 1 2, тоесть такой метод поддерживает вложенный список как минимум, и так до бескрайнего рубежа file.1111 передавая 15 массивов перворазделённых 29 пробелами приблизительно