
Исследователи из Калифорнийского университета в Сан-Диего и Университета Цинхуа разработали новый подход для повышения точности больших языковых моделей (LLM). Они научили нейросеть оценивать свою уверенность в ответах и обращаться за помощью только в случае необходимости.
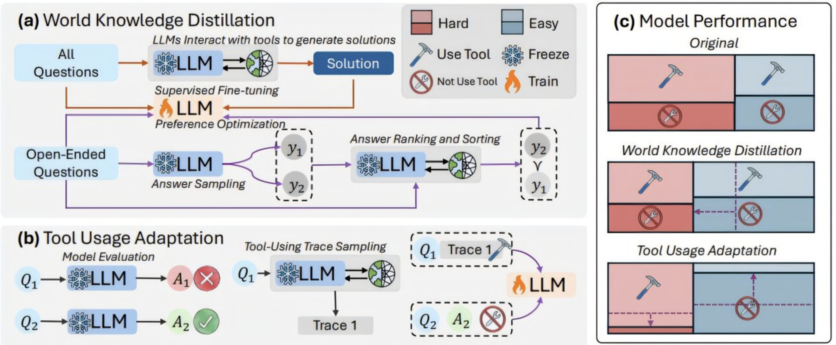
Для реализации этого подхода команда ввела двухэтапное обучение. На первом, получившем название «Дистилляция знаний», LLM учится решать задачи с использованием внешних инструментов, что позволяет копить экспертные данные по теме. На втором этапе, «Адаптации инструментов», языковая модель классифицирует задачи по уровню сложности и устанавливает уровень уверенности, с которым она может справиться самостоятельно, без привлечения дополнительных ресурсов.
Тесты показали, что модель с 8 миллиардами параметров стала на 28,18% точнее, доказав, что большие размеры не всегда необходимы. По словам исследователей, увеличение размеров моделей не всегда приводит к лучшим результатам. Новый подход позволяет создать высокоэффективные языковые модели, не увеличивая их масштаб.