При парсинге сайтов и адаптации их для выгрузки на другие ресурсы. Требуется грамотно подобрать ключевые слова. Данный плагин берет код html страницы, получает данные по TITLE, KEYWORDS, DESCRIPTION. Анализирует их на наличие слов и делает выводы каких слов используется больше и размещает их через запятую в порядке убывания. Вот код для обработки: using System;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using DynamicPluginData;
namespace DatacolDynamicPluginNS
{
public class DynamicPluginClass
{
public static string processDataFieldValue(string htmlContent, ItemInfo itemInfo, GlobalInfo globalInfo)
{
// Шаблоны регулярных выражений для извлечения содержимого тегов
string titlePattern = @"<title>(.*?)<\/title>";
string keywordsPattern = @"<meta\s+name=[""']keywords[""']\s+content=[""'](.*?)[""']\s*\/?>";
string descriptionPattern = @"<meta\s+name=[""']description[""']\s+content=[""'](.
При парсинге сайтов и адаптации их для выгрузки на другие ресурсы. Требуется грамотно подобрать ключевые слова.

Данный плагин берет код html страницы, получает данные по TITLE, KEYWORDS, DESCRIPTION. Анализирует их на наличие слов и делает выводы каких слов используется больше и размещает их через запятую в порядке убывания.
Вот код для обработки:
using System;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using DynamicPluginData;
namespace DatacolDynamicPluginNS
{
public class DynamicPluginClass
{
public static string processDataFieldValue(string htmlContent, ItemInfo itemInfo, GlobalInfo globalInfo)
{
// Шаблоны регулярных выражений для извлечения содержимого тегов
string titlePattern = @"<title>(.*?)<\/title>";
string keywordsPattern = @"<meta\s+name=[""']keywords[""']\s+content=[""'](.*?)[""']\s*\/?>";
string descriptionPattern = @"<meta\s+name=[""']description[""']\s+content=[""'](.*?)[""']\s*\/?>";
// Список для хранения всех слов
List<string> words = new List<string>();
// Извлечение содержимого <title>
Match titleMatch = Regex.Match(htmlContent, titlePattern, RegexOptions.IgnoreCase);
if (titleMatch.Success)
{
words.AddRange(SplitIntoWords(titleMatch.Groups[1].Value));
}
// Извлечение содержимого <meta name="keywords">
Match keywordsMatch = Regex.Match(htmlContent, keywordsPattern, RegexOptions.IgnoreCase);
if (keywordsMatch.Success)
{
words.AddRange(SplitIntoWords(keywordsMatch.Groups[1].Value));
}
// Извлечение содержимого <meta name="description">
Match descriptionMatch = Regex.Match(htmlContent, descriptionPattern, RegexOptions.IgnoreCase);
if (descriptionMatch.Success)
{
words.AddRange(SplitIntoWords(descriptionMatch.Groups[1].Value));
}
// Подсчитываем частоту каждого слова
Dictionary<string, int> wordFrequency = new Dictionary<string, int>();
foreach (string word in words)
{
if (wordFrequency.ContainsKey(word))
{
wordFrequency[word]++;
}
else
{
wordFrequency[word] = 1;
}
}
// Сортируем слова по частоте вручную
List<KeyValuePair<string, int>> sortedWords = new List<KeyValuePair<string, int>>(wordFrequency);
sortedWords.Sort((pair1, pair2) => pair2.Value.CompareTo(pair1.Value));
// Выбираем самые частые слова и возвращаем их через запятую
List<string> mostCommonWords = new List<string>();
int count = 0;
foreach (var pair in sortedWords)
{
if (count >= 10) break; // Можно изменить количество слов
mostCommonWords.Add(pair.Key);
count++;
}
return string.Join(", ", mostCommonWords);
}
// Метод для разбивки строки на слова, удаляя знаки препинания, приводя к нижнему регистру и отбрасывая слова короче 3 букв
private static List<string> SplitIntoWords(string input)
{
List<string> words = new List<string>();
foreach (var word in Regex.Split(input.ToLower(), @"\W+"))
{
if (!string.IsNullOrEmpty(word) && word.Length >= 3)
{
words.Add(word);
}
}
return words;
}
}
}
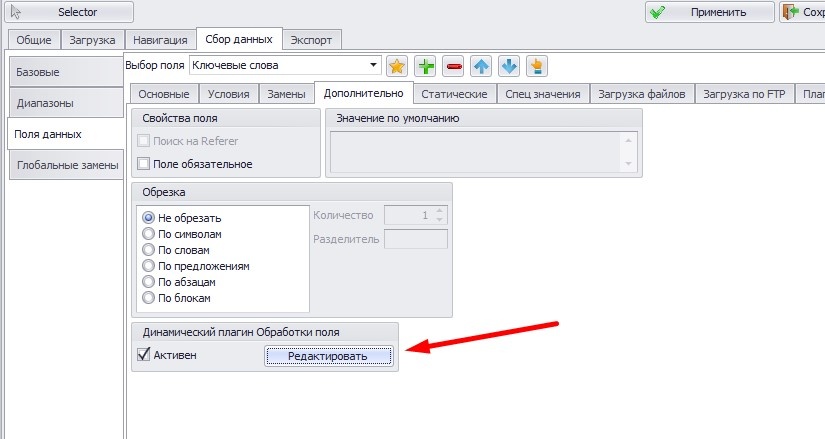
Пользуемся.