
Если вы разработчик и еще не сталкивались с этой проблемой, все равно стоит ознакомиться, так как на каком-то этапе вашей карьеры, понадобится создать REST эндпоит, выполняющий запрос к базе данных с результатами, которые не помещаются в память.
В этой статье давайте углубимся в пример REST эндпоит, который невозможно реализовать традиционным способом из-за потребления памяти.
Входные данные
В этом упражнении давайте воспользуемся простым сценарием, включающим Customer, Order, OrderItem и Product.
Наша цель — создать эндпоит, который будет генерировать отчет. Этот эндпоит будет запрашивать и возвращать:
- Миллион заказов.
- Более 5 миллионов заказов.
Традиционная реализация
Давайте определим DTO с некоторыми полями:
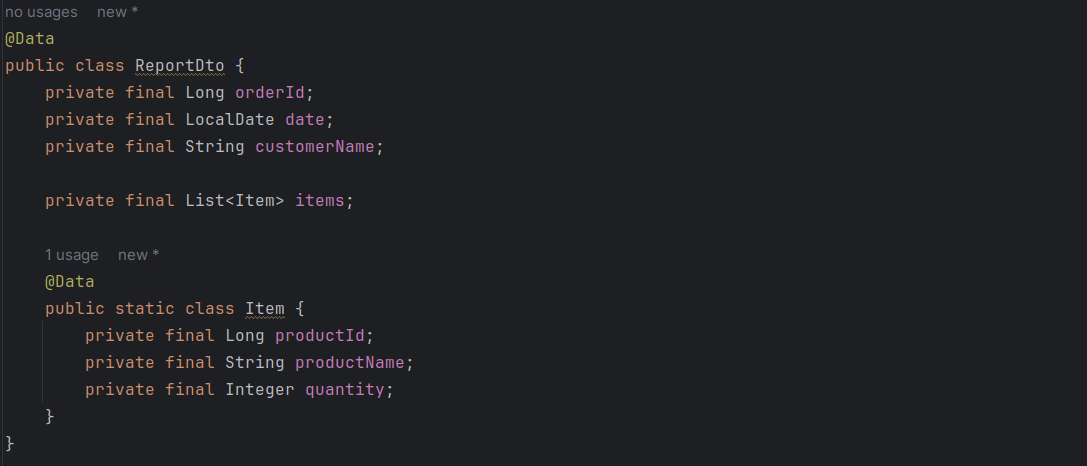
Репозиторий представляет собой CrudRepository для сущности Order, который позволяет нам получать все остальные данные через отношения JPA. Для простоты мы будем использовать метод findAll для возврата данных.
Сервисный класс выполняет следующие действия:
- Создает ArrayList для хранения результата выполнения метода.
- Вызывает метод findAll из репозитория для получения данных заказов.
- Просматривает результаты запроса и сопоставляет их с DTO.
Контроллер просто вызывает службу и возвращает результаты.
При использовании Curl для проверки эндпоинта через 45 минут мы столкнулись с 500 ошибкой. Проверив логи мы обнаружили следующие сообщения:
Нашей реализации не удалось запросить данные из базы данных, поскольку результат запроса превысил доступную память.
Решение проблемы
Наш первый шаг — улучшить процесс запросов, чтобы эффективно обрабатывать большие объемы данных.
Во-первых, давайте определим в репозитории метод, который возвращает поток вместо списка или итерируемого объекта. При использовании Stream в качестве возвращаемого типа данные не извлекаются из базы данных сразу. Вместо этого он возвращается частями по мере потребления потока.
Сервисный класс, так же необходимо изменить:
Поскольку репозиторий возвращает поток, а данные будут извлекаться из базы данных по требованию, нам необходимо держать транзакцию открытой на протяжении всего выполнения. Нам нужна транзакция только для чтения, которую мы достигаем с помощью аннотации @Transactional(readOnly = true).
Поскольку мы имеем дело с потоком, который извлекает данные из базы данных, нам необходимо убедиться, что мы правильно закрываем поток. Для этого мы используем оператор try-with-resources.
Чтобы гарантировать, что JPA не сохранит объект в памяти после его обработки, мы отключаем его вручную с помощью EntityManager.
Контроллер остался прежним, но теперь он относится к версии 2 API. В результате мы наконец получаем результат. Мы решили проблему с памятью JPA; однако для возврата результата потребовалось 42 минуты, и я уверен, что мы можем добиться большего.
Потоковая передача результата
Время, затрачиваемое на обработку и возврат результатов, слишком велико, поскольку Java приходится обрабатывать большой объем данных, а внутренние структуры данных теряют производительность по мере их увеличения.
Решение состоит в том, чтобы использовать поток для возврата данных. Для вызывающего абонента это работает аналогично загрузке файла, при этом результаты отправляются сервером частями.
Контроллер теперь возвращает StreamingResponseBody:
Сервисный класс тоже требует некоторых изменений:
Поскольку для возврата данных мы используем поток, нам необходимо вручную управлять транзакцией с помощью TransactionTemplate. Чтобы создать его экземпляр, нам нужен PlatformTransactionManager, который передается в конструкторе.
Мы используем Transaction Template для инкапсуляции основного выполнения, выполняемого методом fillStream.
Метод fillStream использует ObjectMapper для преобразования результата в JSON. Для каждого заказа, полученного из базы данных, он сопоставляется с DTO, преобразует его в JSON и записывает в StreamingResponseBody.
После внесения этого изменения через несколько секунд после вызова конечных точек мы начинаем получать ответ. Поскольку результат передается в потоковом режиме, память, используемая Java для его обработки, становится незначительной, что значительно повышает производительность этого выполнения. Фактически, улучшение производительности было настолько существенным, что время выполнения сократилось с 42 минут до всего лишь 30 секунд!
Мы можем дополнительно улучшить этот код, оптимизировав сам запрос, например, используя конкретный запрос, который возвращает результат непосредственно в формате DTO, с целью уменьшить количество запросов к базе данных.