
Создание документации к REST API может показаться сложной и утомительной задачей, особенно если вы только начинаете. Я расскажу вам о способе документировать сделанное прямо в процессе разработки. С n8n это реально! Простой интерфейс и мощные функции автоматизации помогают создать документацию за считанные минуты, избавляя от рутинной работы и снижая риск ошибок.
В этой статье вы узнаете, как с помощью n8n даже новичок может быстро и легко создать полную и понятную документацию для своего REST API. сделанного на n8n.
Проблема разработки документации известна с античных времен
(шутка одного разработчика)
Для большинства разработчиков документация, это правильно оформленный аннотационный блок в коде.
Автодокументор пройдет по нему и сверстает документацию. Всегда возникает задача поддержания в актуальном виде этого блока на протяжении всего времени проекта. Но оставим традиционную разработку.
Поговорим о разработчиках нетрадиционной ориентациизанимающихся задачами интеграции.
Тем, кто связан с REST API, конечно известна нотация OpenAPI и, название ставшее нарицательным, Swagger.
Здесь нужно отметить, что становление этой идеологии полностью изменило подход к разработке API и созданию документации.
Раньше мы разрабатывали, затем делали документацию. Теперь мы проектируем, затем включаем автогенератор. Он генерирует шаблоны эндпоинтов, объекты данных на нужном нам языке и, сразу, документацию. Затем дорабатываем логику.
Современный подход ставит проектирование на первое место и берет на себя большую часть рутинных действий. Что хорошо.
Применение этой идеологии делает наши подходы к созданию API стандартизованными. А значит негибкими.
К тому же, иногда сложно спроектировать все API сразу. Постепенное же проектирование, при использовании таких инструментов, приводит к необходимости глубоких переработок. Со временем, когда кодовая база нарастает, если вы не покрыли тестами весь проект, велика вероятность возникновения ошибок.
Одним словом концепция: проектирование-документация-рутинный код, негибкая. И из-за связанности несет риски упущений на поздних этапах разработки.
Интересный подход предлагает команда телеграм. Его API выполняется слоями. И каждый раз, пересобираясь в новую версию, авторы сохраняют наследие старых функций и документов. А значит, принимая изменения, видят несоответствия и вынуждены вносить изменения.
Как у вас выполнен каталог сервисов?
На заре моих занятий интеграции, побывав на нескольких тусовках интеграторов, я видел как матерые "интеграторы от клиентов" задавали разработчикам шинных решений вопрос: "Как вы предлагаете поддерживать каталог сервисов?". Те отвечали нечто невнятное. Будучи новичком, я не понимал о чем идет речь. На самом же деле речь идет о поддержании необходимого объема информации о том сервисе, который предоставляет шина. Документация.
И в использовании n8n решение этой задачи важно. Ведь разработчики различных клиентов, востребующих эндпоинты, должны быть обеспечены источником знания о том, как это работает.
Итак... пару лет назад... шина n8n... эндпоинты для сервиса с мобильным приложением на flutter и web-клиентом на Vue.Js.
Это был первый опыт "промышленного использования" шины...
Когда количество эндпоинтов переваливает за 10
Проектную документацию на мобильное приложение я делал сам. К полноте информации были вопросы. Сэкономил. Однако документы обладали исчерпывающей информацией для стыковки клиента (приложения) и API шины. Ну и для создания самого приложения, тоже).
Рабочка казалась не нужной. n8n достаточно визуальна, чтобы тратить много времени на документирование. Так думал я на старте...
Но как только количество эндпоинтов перевалило за 10. А значит общее число процессов подошло к 30 (это, кстати плохое соотношение. Расскажу на канале как сделать более эффективно), я стал понимать, что теряю контроль.
Эта задача была не основной. Я переключался. При возврате нужно было все больше и больше времени тратить на "вспоминание" того "что хотел сказать этот художник". Да и разработчики все чаще и чаще задавали вопросы по API.
Все это начинало спускать мое время в ТБД (трубу большого диаметра). Нужно было что-то делать...
Коммунизм = систематизация всего + n8n
На помощь мне пришел блок StickyNote. Для новичков: в n8n это текстовой блок, понимающий MarkDown. Предназначен он для оформления и комментирования процессов.
Так и повелось. В каждом процессе теперь был свой StickyNote, который содержал:
- Имя процесса
- Описание процесса
- Описание входных данных
- Описание выходных данных
- Именованные ссылки на используемые процессы
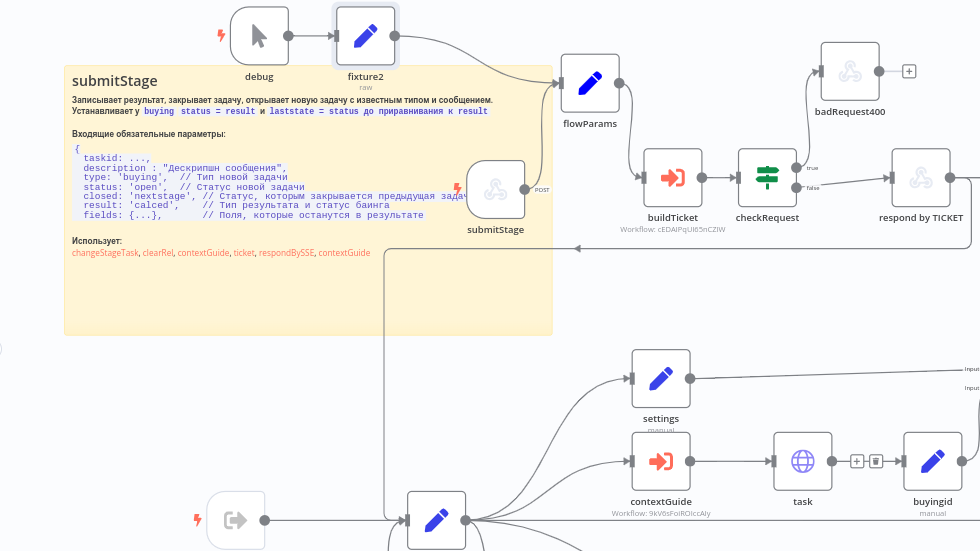
Теперь понятно, что легко пстроить процесс, который собирает много маленьких MarkDown сниппетов в один большой README.md.
Этот самый README.md сложен в корень репозитория в GitLab. Это репозиторий, куда бэкапируется состояние шины (тема бэкапов и ресторов - обширна. Поговорим об это на телеграм канале отдельно).
Что получилось:
- локальная документация собирается в документацию по проекту
- красиво отображается в WEB системе
Ну... раз так, то по четко структурированным блокам, мы можем создать OpenAPI спецификацию и положить все в тот же репозиторий.
И... О ЧУДО! GitLab сразу превращает все это в Swagger клиент. Разработчик, приходя в GitLab, сразу же может протестировать работу эндпоинта.
Мы сразу структурируем наши процессы по типам. При помощи ТЭГОВ. У меня это выглядит так:
- API - процессы эндпоинтов, которые попадают и в OpenAPI.json и в общую документацию.
- share - внутренние процессы. Попадают в общую документацию
- без меток API и share - не попадают в документацию
Вкалывают роботы, а не человек!
(фраза из песни к кинофильму "Приключения электроника")
Вся эта несложная система решает задачу соответствия доступной команде документации и документации, которую использует разработчик интеграций.
Но как же решить задачу соответствия документации и фактического состояния процесса?
Делюсь секретом...
Это достигается за счет структурирования блока StickyNote (о его структуре я писал выше) и структурирования самих процессов share и API.
Для ускорения создания интеграционных процессов, я придерживаюсь мнения, что любой процесс устроен по схеме: обработка и проверка входных данных - логика процесса - формирование выходных данных.
Во вселенной с такими принципами все сразу встает на свои места. Сразу появляется процесс-автоматический сборщик, который актуализирует состояние StickyNote. Не генерирует от только словесное описание процесса.
Сложная схема? ПРОСТАЯ)
А чтобы не тратить время на проработку деталей, приходите лучше ко мне на канал. Там вы сможете получить все это и еще много много много инструментов, котрорые снимут с вас рутинные операции из которых состоит ваша жизнь. Останется время на себя и близких)
Чтобы быстро вникнуть в детали, я подготовил для вас небольшой подарок. Это краткий материал о том как правильный подход к интеграции ускорит разработку вашего сервиса.
Подписывайтесь на канал. Забирайте ГАЙД!)