В прошлой статье мы обсуждали структуру проекта и те самые детали, которые помогают держать всё под контролем, когда проект становится сложнее. Отдельные модули, конфигурации и логи — всё это, конечно, создаёт хорошую базу. Но что дальше?
Но на этом порядок и систематизация не заканчиваются. Важно не только грамотно организовать код, но и подумать о том, как сделать его «умным» — способным адаптироваться к задачам, требующим точности и гибкости.
Сегодня мы поговорим о фильтрации новостей и проверке дубликатов — задачах, которые важны в проектах, работающих с потоками данных, как в моём проекте по мониторингу Telegram-каналов. Каждый, кто работал с большими объёмами данных, знает, как легко утонуть в потоке повторяющихся сообщений.
Иногда одно и то же событие могут описывать десятки источников, и каждый раз сообщение чуть-чуть отличается: здесь добавлено одно слово, там изменён порядок фраз. Задача в том, чтобы научиться отличать эти «шумные» сообщения от действительно уникальных.
Как этого добиться? Сегодня я покажу вам алгоритм, который использует две библиотеки — spaCy для обработки текста и SequenceMatcher для проверки текстового сходства. Мы разберём, как добавить гибкость и точность в борьбу с сообщениями и настроить систему так, чтобы она выделяла только свежие и уникальные новости.
Лемматизация: как она помогает улучшить фильтрацию дубликатов?
Одним из важных элементов алгоритма является лемматизация — процесс приведения слов к их базовой форме (лемме). Например, слова "происходило", "произошло", "происходит" после лемматизации превращаются в одну форму — "происходить". Это позволяет системе понимать, что речь идёт об одном и том же действии, независимо от временной формы или склонения.
Лемматизация играет ключевую роль, когда нужно анализировать смысл текста. Вместо того чтобы воспринимать каждую форму слова как что-то уникальное, алгоритм работает с леммами — основными формами слов. Это сокращает количество уникальных слов, улучшает производительность и позволяет точнее определять схожесть.
В нашем примере лемматизация используется, чтобы создавать унифицированные текстовые представления сообщений. Мы сохраняем лемматизированный текст в базе данных, и это упрощает последующие проверки на дублирование, так как система проверяет сходство между "очищенными" версиями сообщений.
Как это работает в коде?
В коде лемматизация выполняется с помощью библиотеки spaCy. Она проходит по каждому слову сообщения и возвращает его лемму — основную форму. В итоге система работает с текстом, в котором все слова приведены к начальной форме, что делает проверку дубликатов более точной и надёжной.
Пример улучшенного кода: контроль за дубликатами с помощью SequenceMatcher и lemmatized_text
Для начала взглянем на улучшенный код, который делает проверку дубликатов более точной. Мы добавили дополнительные методы для оценки схожести и предусмотрели сохранение лемматизированного текста в базе данных, чтобы упростить последующие проверки. Это даёт нам двойную проверку: анализ текстового сходства и анализ семантики текста.
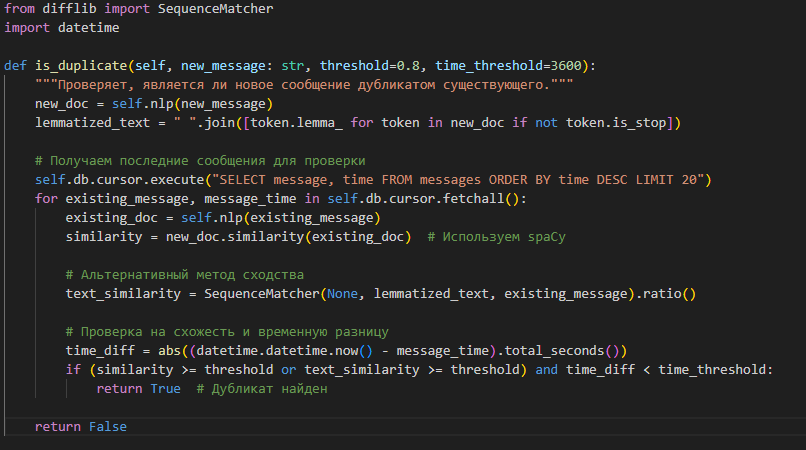
Основные фишки нового подхода
Вообще, этот код получился куда более точным и надёжным для проверки дубликатов. Несколько моментов действительно делают его сильнее:
- Двойная проверка схожести:
Я добавил SequenceMatcher к spaCy, и это даёт классный эффект. spaCy хорошо работает со смысловым сходством, но, если в вашей модели нет векторного представления слов, не всегда можно точно определить схожесть. А вот SequenceMatcher работает на уровне символов, что иногда может спасти, особенно если сообщения почти одинаковы, но где-то слегка отличается формулировка. - Гибкие пороги для настройки:
Здесь мне нравится, что можно играться с параметрами. threshold отвечает за уровень сходства, а time_threshold позволяет задавать временные рамки, чтобы оценивать актуальность сообщений. Допустим, если вам важнее получать более свежие события, можно просто ослабить временной порог, и система будет обращать внимание на более частые обновления.
Как порог схожести влияет на проверку дубликатов?
Порог схожести (threshold) определяет, насколько похожи два сообщения должны быть, чтобы система посчитала их дубликатами. Разберёмся, как это работает на практике, начиная с более строгого порога 0.9 и заканчивая менее строгим 0.6.
Порог 0.9 (90%): только почти идентичные сообщения
- Сообщение 1: "В Москве произошло крупное ДТП на улице Ленина."
- Сообщение 2: "В Москве произошло серьёзное ДТП на улице Ленина."
При пороге 0.9 такие сообщения считаются дубликатами, так как разница минимальна: всего одно слово изменено. Подобный высокий порог подходит, если вам нужно фиксировать только самые явные повторы. Это полезно, если хотите избежать излишней чувствительности и учитывать только почти идентичные сообщения.
Порог 0.8 (80%): допускаются небольшие отличия
- Сообщение 1: "На улице Ленина в Москве произошло ДТП."
- Сообщение 2: "В Москве на улице Ленина произошло серьёзное ДТП."
Здесь добавлены и переставлены слова, но смысл практически не изменился. При пороге 0.8 такие сообщения всё равно определяются как дубликаты, потому что схожесть всё ещё достаточно высока. Такой порог подойдёт, если вы хотите учитывать небольшие изменения, например, добавленные детали или синонимы, но всё же не отслеживать слишком разные сообщения.
Порог 0.7 (70%): больше гибкости в перефразировке
- Сообщение 1: "На улице Ленина произошло столкновение двух машин."
- Сообщение 2: "Две машины столкнулись на улице Ленина, образовалась пробка."
При пороге 0.7 эти сообщения считаются дубликатами, хотя фраза перестроена, и добавлена новая деталь про пробку. Это значение удобно, если хотите отслеживать новости с перефразировками, но основной смысл сообщений должен совпадать.
Порог 0.6 (60%): минимальные совпадения, допустимы больше отличий
- Сообщение 1: "На улице Ленина произошло ДТП, пострадал один человек."
- Сообщение 2: "Произошло столкновение машин на Ленина в Москве, пострадавший один человек."
При пороге 0.6 эти сообщения могут быть определены как дубликаты, даже несмотря на то, что некоторые фразы изменены и добавлена информация о местоположении. Порог 0.6 подойдёт, если важен сам факт события, а детали могут отличаться. Это будет полезно для случаев, когда нужно учитывать даже малые сходства между сообщениями, чтобы зафиксировать все, даже слегка изменённые дубли.
Как выбрать оптимальный порог?
Если вы работаете с потоком новостей и сообщений, начните с порога 0.7 и протестируйте результаты. Если система фиксирует слишком много дубликатов, снизьте порог до 0.6, но если пропускается важная информация, поднимите его до 0.8. Настройка зависит от ваших задач, и гибкость этого подхода позволяет адаптировать его под любую специфику.
Ваш опыт — ценен! Поделитесь своим мнением!
Как вы справляетесь с проблемой дублирования данных? Какие подходы, библиотеки или методы сходства вам помогают? Поделитесь своим опытом — ваш вклад может помочь улучшить инструменты для работы с данными и фильтрацией новостей.
Спасибо, что были с нами!
Надеюсь, эта статья вдохновила вас на новые идеи и дала ценные советы для работы с дубликатами в данных. Если у вас есть вопросы, предложения или идеи для сотрудничества — пишите, буду рад обсудить их и обменяться опытом. Подписывайтесь на "Кодовый Самописец" и следите за новыми материалами. До встречи и удачного кода! 👨💻🚀