Настройка производилась на Rocky Linux 8
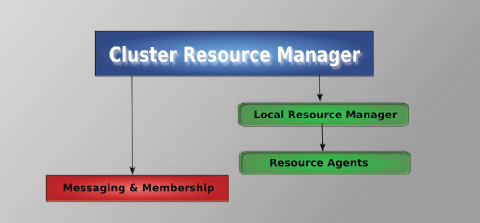
Для построения кластера, будем использовать Pacemaker. Pacemaker - менеджер ресурсов кластера (Cluster Resource Manager), задачей которого является достижение максимальной доступности управляемых им ресурсов и защита их от сбоев как на уровне самих ресурсов, так и на уровне целых узлов кластера.
Архитектура pacemaker состоит из трех уровней:
- Кластеронезависимый уровень - на этом уровне располагаются сами ресурсы и их скрипты, которыми они управляются и локальный демон, который скрывает от других уровней различия в стандартах, использованных в скриптах (на рисунке зеленый).
- Менеджер ресурсов (Pacemaker), который представляет из себя мозг. Он реагирует на события, происходящие в кластере: отказ или присоединение узлов, ресурсов, переход узлов в сервисный режим и другие административные действия. Pacemaker исходя из сложившейся ситуации делает расчет наиболее оптимального состояния кластера и дает команды на выполнения действий для достижения этого состояния (остановка/перенос ресурсов или узлов). На рисунке обозначен синим.
- Информационный уровень - на этом уровне осуществляется сетевое взаимодействие узлов, т.е. передача сервисных команд (запуск/остановка ресурсов, узлов и т.д.), обмен информацией о полноте состава кластера (quorum) и т.д. На рисунке обозначен красным. Как правило на этом уровне работает Corosync.
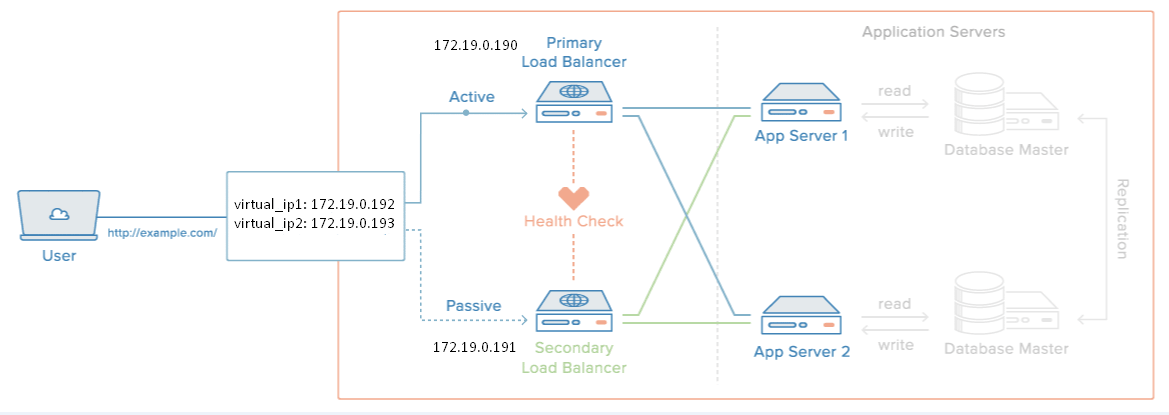
Имеем два сервера с работающим HAProxy и два плавающих(виртуальных ip-адреса)
haproxy-test-01 172.19.0.190
haproxy-test-02 172.19.0.191
virtual_ip_1 172.19.0.192
virtual_ip_2 172.19.0.193
Пропишем в /etc/hosts
172.19.0.190 haproxy-test-01
172.19.0.191 haproxy-test-02
Ставим нужные пакеты
yum install haproxy corosync pcs pacemaker
Включаем автозагрузку сервисов
systemctl enable pcsd
systemctl enable corosync
systemctl enable pacemaker
И наоборот отключаем автозагрузку haproxy
systemctl disable haproxy
systemctl daemon-reload
Для управления кластером используется утилита pcs. При установке Pacemaker автоматически будет создан пользователь hacluster. Для использования pcs, а также для доступа в веб-интерфейс нужно задать пароль пользователю hacluster
passwd hacluster
Запускаем сервис
systemctl start pcsd
Настраиваем аутентификацию (уже на одном узле)
pcs host auth haproxy-test-01 haproxy-test-02
Username: hacluster
Password:
haproxy-test-01: Authorized
haproxy-test-02: Authorized
После этого кластером можно управлять с одного узла
Создаем кластер
pcs cluster setup mycluster --start haproxy-test-01 haproxy-test-02
Автозапуск кластера при загрузке
pcs cluster enable --all
Проверяем статус кластера
pcs status
Cluster name: mycluster
Status of pacemakerd: 'Pacemaker is running' (last updated 2023-07-14 00:30:41 +03:00)
Cluster Summary:
* Stack: corosync
* Current DC: haproxy-test-01 (version 2.1.5-8.0.1.el8-a3f44794f94) - partition with quorum
* Last updated: Fri Jul 14 00:30:42 2023
* Last change: Fri Jul 14 00:23:06 2023 by root via cibadmin on haproxy-test-01
* 2 nodes configured
* 0 resource instances configured
Node List:
* Online: [ haproxy-test-01 haproxy-test-02 ]
Full List of Resources:
* No resources
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/disabled
Проверка синхронизации узлов кластера
corosync-cmapctl | grep members
runtime.members.1.config_version (u64) = 0
runtime.members.1.ip (str) = r(0) ip(172.19.0.190)
runtime.members.1.join_count (u32) = 1
runtime.members.1.status (str) = joined
runtime.members.2.config_version (u64) = 0
runtime.members.2.ip (str) = r(0) ip(172.19.0.191)
runtime.members.2.join_count (u32) = 1
runtime.members.2.status (str) = joined
pcs status corosync
Membership information
----------------------
Nodeid Votes Name
1 1 haproxy-test-01 (local)
2 1 haproxy-test-02
Выключаем STONITH
pcs property set stonith-enabled=false
Так как узла у нас всего два, то кворума у нас не будет, поэтому отключаем эту политику
pcs property set no-quorum-policy=ignore
Настройки можно посмотреть так
pcs property
Cluster Properties:
cluster-infrastructure: corosync
cluster-name: mycluster
dc-version: 2.1.5-8.0.1.el8-a3f44794f94
have-watchdog: false
no-quorum-policy: ignore
stonith-enabled: false
К тому времени у нас уже доступен веб-интерфейс управления кластером https://172.19.0.190:2224
Создаём ресурс, а именно виртуальные плавающие ip-адреса(VIP)
pcs resource create virtual_ip_1 ocf:heartbeat:IPaddr2 ip=172.19.0.192 cidr_netmask=32 op monitor interval=10s
pcs resource create virtual_ip_2 ocf:heartbeat:IPaddr3 ip=172.19.0.193 cidr_netmask=32 op monitor interval=10s
Проверяем
pcs resource
* virtual_ip_1 (ocf::heartbeat:IPaddr2): Started haproxy-test-01
* virtual_ip_2 (ocf::heartbeat:IPaddr3): Started haproxy-test-01
Видим на интерфейсе появились эти самые VIP
ip a
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:0a:04:24 brd ff:ff:ff:ff:ff:ff
inet 172.19.0.190/24 brd 172.19.0.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 172.19.0.192/32 brd 172.19.0.255 scope global ens192
valid_lft forever preferred_lft forever
inet 172.19.0.193/32 brd 172.19.0.255 scope global ens192
valid_lft forever preferred_lft forever
inet6 fe80::250:56ff:fe0a:424/64 scope link
valid_lft forever preferred_lft forever
Изначально ресурса haproxy нет. Так что загружаем его из интернета на оба узла
cd /usr/lib/ocf/resource.d/heartbeat
curl -O https://raw.githubusercontent.com/thisismitch/cluster-agents/master/haproxy chmod +x haproxy
Создаем ресурс haproxy
pcs resource create haproxy systemd:haproxy
Создаём группу ресурсов, в которую пихаем ранее созданные ресурсы
pcs resource group add HAproxyGroup virtual_ip_1 virtual_ip_2 haproxy
Проверяем, и видим что всё запущено на haproxy-test-01
pcs resource
* Resource Group: HAproxyGroup:
* virtual_ip_1 (ocf::heartbeat:IPaddr2): Started haproxy-test-01
* virtual_ip_2 (ocf::heartbeat:IPaddr2): Started haproxy-test-01
* haproxy (systemd:haproxy): Started haproxy-test-01
Порядок загрузки – сначала VIP, потом стартует haproxy (чёт не работает)
pcs constraint order virtual_ip_1 then haproxy
Теперь можно проверить отказоустойчивость кластера. Выключаем haproxy-test-01 и видим, что haproxy и VIP переехали на haproxy-test-02
pcs resource
* Resource Group: HAproxyGroup:
* virtual_ip_1 (ocf::heartbeat:IPaddr2): Started haproxy-test-02
* virtual_ip_2 (ocf::heartbeat:IPaddr2): Started haproxy-test-02
* haproxy (systemd:haproxy): Started haproxy-test-02
ip a
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:0a:04:25 brd ff:ff:ff:ff:ff:ff
inet 172.19.0.191/24 brd 172.19.0.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet 172.19.0.192/32 brd 172.19.0.255 scope global ens192
valid_lft forever preferred_lft forever
inet 172.19.0.193/32 brd 172.19.0.255 scope global ens192
valid_lft forever preferred_lft forever
inet6 fe80::250:56ff:fe0a:424/64 scope link
valid_lft forever preferred_lft forever
Если требуется сменить рабочую ноду руками(для технических работ например), переносим ресурсы таким образом
pcs resource move HAproxyGroup haproxy-test-02
Добавление новой ноды в кластер
pcs host auth haproxy-test-03
pcs cluster node add haproxy-test-03