XPath - язык запросов к xml документу, который часто используется при поиске DOM - элементов сайта. XPath включает в себя следующие понятия:
1. УЗЕЛ - Элемент дерева документа
2. Путь - путь пройденный к искомому узлу
3. Ось - вектор движения запроса
Синтаксис
XPath состоит из последовательности блоков (пути) до определенного узла, каждый из которых строится следующим образом:
//*ТЕГ*[@*АТРИБУТ* *УСЛОВИЕ* '*ЗНАЧЕНИЕ АТРИБУТА*']
К примеру,
.//div[@class='button-wrapper']/input[@type='button']
В данном примере, в первом блоке выполняется поиск div-узла с классом 'button-wrapper'. Во втором блоке ищет потомка с атрибутом 'type' равным 'button'.
Стоит упомянуть, что вместо тега можно поставить "*", что означает "Любой"
Для дальнейшего понимания статьи составим небольшой html документ в виде дерева:
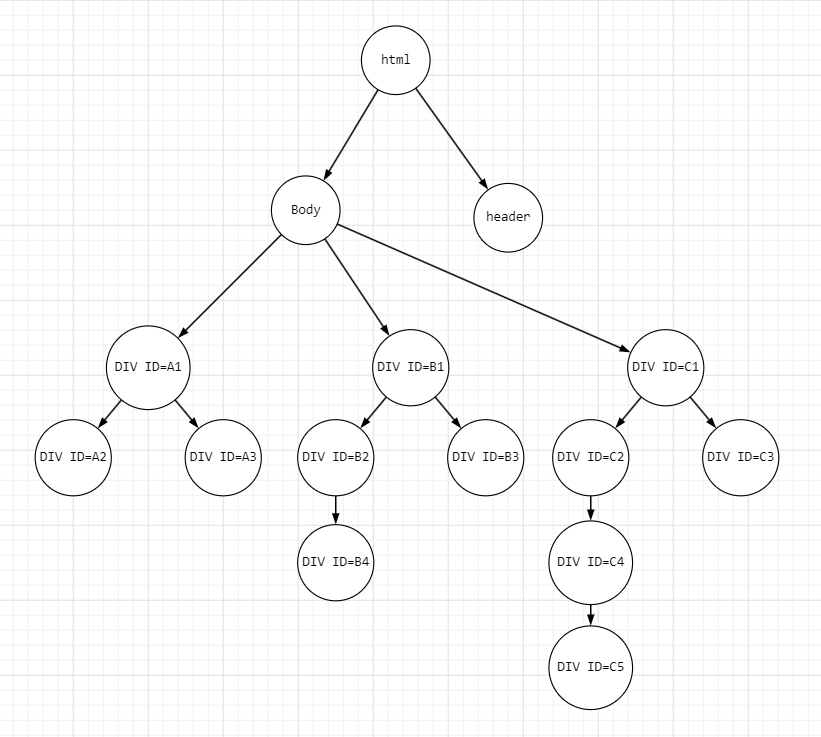
Пути
XPath по своей сути говорит как дойти до того или иного узла. Указать путь возможно двумя способами:
1. Абсолютным путем
2. Относительным путем
Абсолютный путь
Абсолютный путь формируется от верхнего узла (html) до искомого (к примеру, на графе возьмем DIV ID=C3).
Путь начинается с '/'.
Построим XPath по методу абсолютного пути:
/html/body/div[@id='C1']/div[@id='C3']
Данный запрос проведет нас по пути, показанному на рисунке ниже
![Путь. пройденный по XPath (/html/body/div[@id='C1']/div[@id='C3'])](https://avatars.dzeninfra.ru/get-zen_doc/271828/pub_6723d580510c517fe9e7b05a_6723e6f6fc2fdb7596602efe/scale_1200)
Как видно, путь начался с узла html и следовал по всем остановкам до конечной.
Относительный путь
Относительный путь формируется от начального узла, который отвечает условиям поиска, к конечному.
Путь начинается с '//'.
Для примера возьмем элемент DIV ID=B1 и найдем в нем потомка DIV ID=B3 и составим запрос:
//div[@id='B1']/div[@id='B3']
В итоге мы пройдем путь на картинке ниже:
Как видно, относительный путь выглядит короче, но абсолютный путь более производительный, так как отбрасывает ответвления, однако, есть важное замечание "Абсолютный путь не приемлет изменений", т.е. если на страницу добавить новый элемент, то XPath ломается. Следовательно, относительный путь более предпочтителен.
Условия
В XPath есть три классических логических условий: AND, OR, NOT
Оператор OR - логическое или. Вспоминая булевскую алгебру: истинна будет, когда один из частей выражения является истинной. Внизу оставлю таблицу истинности
| А | B | Результат |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
Для примера получим три дочерних элемента 'BODY' с помощью условного оператора OR (ИЛИ):
Составим XPath:
//div[@id='A1' OR @id='B1' OR @id='C1']
В итоге получаем необходимые элементы
Оператор AND - логическое И. Истинной будет, когда все части выражения истинны.
Таблица истинности
| А | B | Результат |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Для понимания работы оператора AND (И) добавим дополнительные узлы и атрибут (изменения обведены красной рамкой).
Итак, для того чтобы найти элемент [DIV ID=A1 ARIA=2] составим следующий запрос:
//div[@aria='2' and @id='A1']
В итоге найдем нужный элемент.
Оператор NOT - Логическое отрицание.
Таблица истинности
| А | Результат |
| 0 | 1 |
| 1 | 0 |
Для проверки работы логического отрицания NOT найдем другой элемент из созданных. Составим запрос XPath:
//div[@aria='2' and not(@id='A1')]
В итоге получим искомый элемент
ОСИ
Оси необходимы, чтобы мы смогли указать как и в какую сторону будем двигаться по пути.
Для формирования осей необходимо воспользоваться следующей конструкцией:
*ОСЬ*::*УЗЕЛ*[*Условия поиска*]
Основными осями являются:
1. parent - к родителю
2. ancestor - к предкам
3. ancestor-or-self - к предкам, включая текущий
4. child - к непосредственному потомку
5. descendant - ко всем потомкам
6. following - братские элементы (того же уровня справа), включая потомков
7. following-sibling - братские элементы (того же уровня справа)
8. preceding - выше текущего, включая потомков
9. preceding-sibling братские элементы (того же уровня слева)
Для отображения движения за текущий элемент возьмем DIV ID=B1
Parent
Движение происходит к непосредственному родителю текущего узла
Составим запрос:
//div[@id='B1']/parent::body
В итоге получим родительский узел "BODY"
Ancestor
Движение происходит не только к родительскому, но к более верхне-уровневым узлам-прародителям
Составим запрос
//div[@id='B1']/ancestor::html
По результатам данного запроса получим корневой узел "HTML"
Ancestor-or-self
Работает так же, как и предыдущая ось "ancestor". Разница заключается в том, что также захватывает и текущий узел
Составим запрос:
//div[@id='B1']/ancestor::*
Для большей наглядности выберем все узлы с помощью символа '*'. В результате получаем следующие узлы:
Child
Движется к непосредственным потомкам
Составим запрос:
//div[@id='B1']/child::*
В итоге получаем следующие узлы
Descendant
Движется ко всем потомкам
Составим запрос:
//div[@id='B1']/descendant::*
В итоге получаем следующие узлы
Following
Движется к узлам, находящиеся на одном уровне, ниже/справа от текущего узла, включая потомков
Составим запрос:
//div[@id='B1']/following::*
В итоге получаем следующие узлы
Following-sibling
Движется к узлам, находящиеся на одном уровне, ниже/справа от текущего узла
Составим запрос:
//div[@id='B1']/following-sibling::*
В итоге получаем следующие узлы
Preceding
Движется к узлам, находящиеся на одном уровне, выше/слева от текущего узла, включая потомков
Составим запрос:
//div[@id='B1']/preceding::*
В итоге получаем следующие узлы
Preceding-sibling
Движется к узлам, находящиеся на одном уровне, выше/слева от текущего узла
Составим запрос:
//div[@id='B1']/preceding-sibling::*
В итоге получаем следующие узлы
Функции
Последним о чем бы хотелось поговорить - это функции.
1. boolean(*Значение*) - Конвертация в булевское значение
boolean('true') -> true
2. ceiling(*Значение*) - Возвращает наименьшее целое число, которое не меньше заданного. Если число не удается преобразовать - возвращается NaN
ceiling(123.5) -> 124
ceiling('ds;lf'') -> NaN
3. comment() - Получает комментарий к узлу
К примеру представим html страницу:
<html>
<head>
</head>
<body>
<div>
<!-- Коммент -->
</div>
</body>
</html>
Для получения комментария сформируем запрос
/html/body/div/comment() -> Коммент
4. concat(*Значение 1*, *Значение 2*, ...) - конкатенация (склеивание) строк
concat('a', 'b', 'c') -> abc
5. contains(*Значение источник*, *Значение для поиска*) - содержит ли значение источник
contains('ab', 'b') -> true
6. count(XPath) - количество найденных узлов
contains('/html/body') -> 1
7. document(URL) - преобразование в дерево документа по ссылке
document('https://test.com') -> <html> .... </html>
8. true()/false() - возвращает истину/ложь
9. floor(*Значение*) - Округляет до целого, но не более задаваемого. Если число не удается преобразовать - возвращается N
floor(2.3) -> 2
floor('sfdfsdfsd') ->NaN
10. last() - Возвращает true если элемент последний
Рассмотрим html-документ
<html>
<head>
</head>
<body>
<div>
<!-- Коммент -->
</div>
<div id = '1'>
</div>
</body>
</html>
Составим запрос
/html//body/div[last()] -> <div id=1> ...
11. normalize-space(*Значение*) - Удаляет лишние пробелы
normalize-space('a c') -> a c
12. node() - получает текст всех дочерних узлов (внутри тега)
Рассмотрим html-документ
<html>
<head>
</head>
<body>
<div>
a
</div>
<div id = '1'>
b
</div>
</body>
</html>
Составим запрос:
/html/body/node() -> [a, b]
13. text() - получает текст узла. В отличии от node() требуется дойти до узла с текстом
Рассмотрим html-документ
<html>
<head>
</head>
<body>
<div>
a
</div>
<div id = '1'>
b
</div>
</body>
</html>
Составим запрос:
/html/body/div[@id='1']/text() -> b
14. not(*Булевское выражение*) - отрицание
not(2 = 2) -> false
15. number(*Значение*) - преобразование в число. Если не удалось преобразовать в число, то вернется NaN
number('2') -> 2
number('adsaf') -> NaN
16. round(*Значение*) - округление до целого
round(2.3) -> 2
17. starts-with(*Значение источник*, *Значение искомое*) - проверка начинается ли источник с искомым значением
starts-with('abc', 'a') -> true
starts-with('abc', 'b') -> false
18. string(*Значение*) - преобразование в строку
string(2.2) -> '2.2'
19. string-length(*Значение*) - получает длину строки
string-length('abcd') -> 4
20. substring(*значение источник*, *Индекс начала*, *Индекс конца*) - выделение подстроки по индексам начала и конца
substring('abcd', 0, 2) -> 'abc'
21. substring-after(*значение источник*, *Разделитель*) - выделение подстроки после указанного разделителя
substring-after('ab-cd', '-') -> 'cd'
22. substring-before(*значение источник*, *Разделитель*) - выделение подстроки до указанного разделителя
substring-before('ab-cd', '-') -> 'ab'
23. sum(*Значение 1*, *Значение 2*...) - суммирует значения
sum(1, 2, 3) -> 6
24. translate(*Значение источника*, *Искомое значение*, *Значение для замены*) - выполняет замену символов
translate('ab-cd', '-', '') -> abcd