Дашборды Grafana предлагают визуально привлекательный и эффективный способ отслеживания метрик сервера. В этом руководстве мы рассмотрим процесс настройки Grafana с VMWare для эффективного мониторинга различных метрик на ваших серверах.
В прошлом году я поделился гайдом по настройке Grafana для Proxmox. После перехода в основном на стек VMWare самое время изучить аналогичную конфигурацию для VMWare.
Обратите внимание: В этом руководстве предполагается, что у вас есть работающий vCenter, так как он использует свой API.
В конце этого поста вы найдете ссылки на некоторые фантастические готовые панели управления Grafana, которые помогут вам начать мониторинг VMWare.
Создание стека контейнеров
Я запускаю свой стек мониторинга с помощью контейнеров Docker, оркестрованных с помощью Docker Compose. Мы настроим три контейнера:
- Телеграф: Собирает данные из API vCenter и отправляет их в InfluxDB.
- База данных InfluxDB: База данных, в которой хранятся метрики.
- Графана: Визуализирует метрики из InfluxDB.
Заполните файл docker-compose.yml следующим содержимым:
version: "3"
services:
grafana:
image: grafana/grafana
container_name: grafana_container
restart: always
ports:
- 3000:3000
networks:
- monitoring_network
volumes:
- grafana-volume:/var/lib/grafana
influxdb:
image: influxdb
container_name: influxdb_container
restart: always
ports:
- 8086:8086
- 8089:8089/udp
networks:
- monitoring_network
volumes:
- influxdb-volume:/var/lib/influxdb
telegraf:
image: telegraf
container_name: telegraf_container
restart: always
networks:
- monitoring_network
volumes:
- ./telegraf/telegraf.conf:/etc/telegraf/telegraf.conf:ro
networks:
monitoring_network:
external: true
volumes:
grafana-volume:
external: true
influxdb-volume:
external: true
Создайте необходимые тома и сеть Docker, выполнив:
docker volume create influxdb-volume
docker volume create grafana-volume
docker network create monitoring_network
Я предпочитаю отдельные тома для InfluxDB и Grafana, в первую очередь из-за преимуществ в производительности.
Запустите контейнеры с docker compose up -d в том же каталоге, что и файл docker-compose.yml.
Устранение ошибок при запуске:
При запуске контейнеров вы можете столкнуться с сообщением об ошибке о конфигурации Telegraf. Вот как это исправить:
- Перейдите в справочник телеграфа.
- Удалите существующий файл telegraf.conf и создайте новый:
rm -rf telegraf.conf
sudo touch telegraf.conf
Настройка InfluxDB
Начните с посещения http://your_host:8086
Следуйте простому процессу настройки, записывая все детали для использования на последующих шагах.
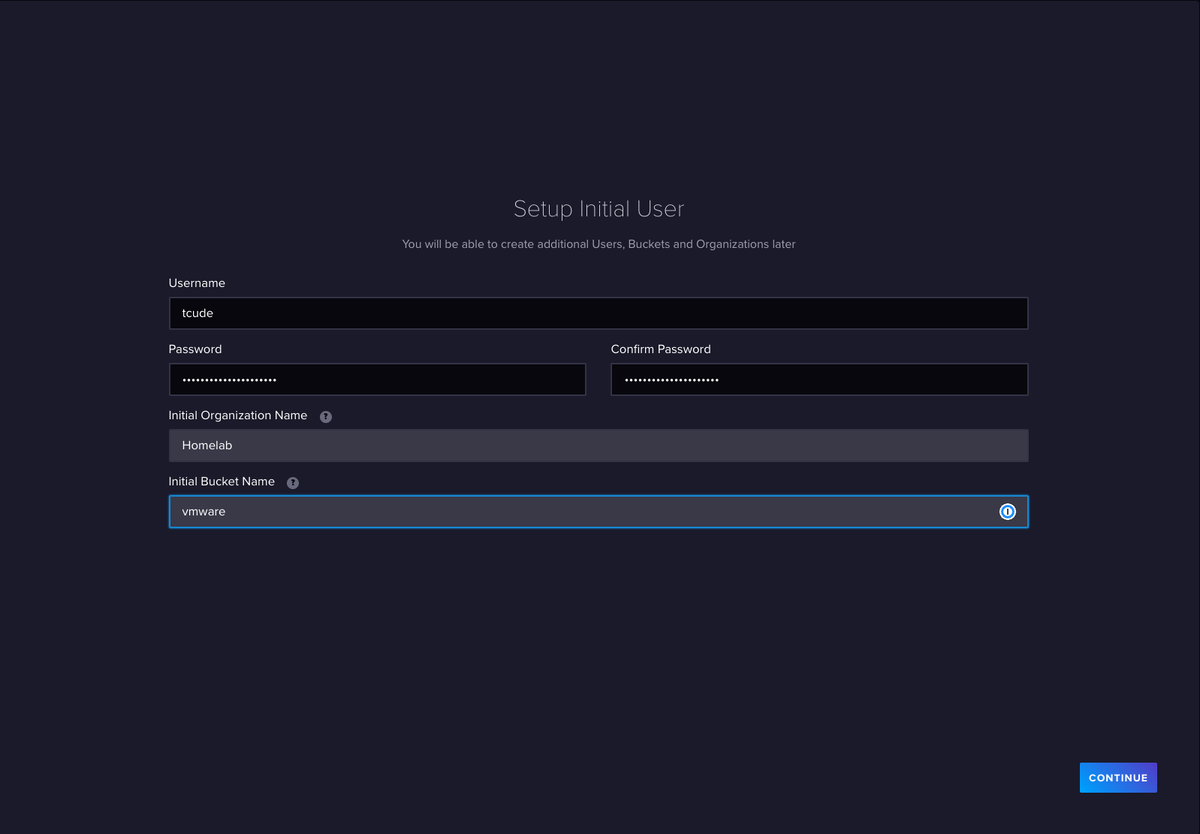
После отправки вам будет представлен токен API. Держите его подальше.
Настройка Телеграфа
Теперь пришло время настроить Телеграф. Для этого вам нужно будет вернуться в свой терминал и вернуться к файлу telegraf.conf, который мы создали ранее. Начните с заполнения его следующим образом:
[outputs.influxdb_v2]
urls = ["http://your_influxdb_host:8086"]
## Token for authentication.
token = "your_token_here"
## Organization is the name of the organization you wish to write to; must exist.
organization = "Homelab"
## Destination bucket to write into.
bucket = "vmware"
Дополнительно, после блока outputs, добавим следующий блок inputs:
# Read metrics from VMware vCenter
[[inputs.vsphere]]
## List of vCenter URLs to be monitored. These three lines must be uncommented
## and edited for the plugin to work.
vcenters = [ "https://<vcenter_hostname>/sdk" ]
username = "administrator@vsphere.local"
password = "password_here"
#
## VMs
## Typical VM metrics (if omitted or empty, all metrics are collected)
vm_metric_include = [
"cpu.demand.average",
"cpu.idle.summation",
"cpu.latency.average",
"cpu.readiness.average",
"cpu.ready.summation",
"cpu.run.summation",
"cpu.usagemhz.average",
"cpu.used.summation",
"cpu.wait.summation",
"mem.active.average",
"mem.granted.average",
"mem.latency.average",
"mem.swapin.average",
"mem.swapinRate.average",
"mem.swapout.average",
"mem.swapoutRate.average",
"mem.usage.average",
"mem.vmmemctl.average",
"net.bytesRx.average",
"net.bytesTx.average",
"net.droppedRx.summation",
"net.droppedTx.summation",
"net.usage.average",
"power.power.average",
"virtualDisk.numberReadAveraged.average",
"virtualDisk.numberWriteAveraged.average",
"virtualDisk.read.average",
"virtualDisk.readOIO.latest",
"virtualDisk.throughput.usage.average",
"virtualDisk.totalReadLatency.average",
"virtualDisk.totalWriteLatency.average",
"virtualDisk.write.average",
"virtualDisk.writeOIO.latest",
"sys.uptime.latest",
]
# vm_metric_exclude = [] ## Nothing is excluded by default
# vm_instances = true ## true by default
#
## Hosts
## Typical host metrics (if omitted or empty, all metrics are collected)
host_metric_include = [
"cpu.coreUtilization.average",
"cpu.costop.summation",
"cpu.demand.average",
"cpu.idle.summation",
"cpu.latency.average",
"cpu.readiness.average",
"cpu.ready.summation",
"cpu.swapwait.summation",
"cpu.usage.average",
"cpu.usagemhz.average",
"cpu.used.summation",
"cpu.utilization.average",
"cpu.wait.summation",
"disk.deviceReadLatency.average",
"disk.deviceWriteLatency.average",
"disk.kernelReadLatency.average",
"disk.kernelWriteLatency.average",
"disk.numberReadAveraged.average",
"disk.numberWriteAveraged.average",
"disk.read.average",
"disk.totalReadLatency.average",
"disk.totalWriteLatency.average",
"disk.write.average",
"mem.active.average",
"mem.latency.average",
"mem.state.latest",
"mem.swapin.average",
"mem.swapinRate.average",
"mem.swapout.average",
"mem.swapoutRate.average",
"mem.totalCapacity.average",
"mem.usage.average",
"mem.vmmemctl.average",
"net.bytesRx.average",
"net.bytesTx.average",
"net.droppedRx.summation",
"net.droppedTx.summation",
"net.errorsRx.summation",
"net.errorsTx.summation",
"net.usage.average",
"power.power.average",
"storageAdapter.numberReadAveraged.average",
"storageAdapter.numberWriteAveraged.average",
"storageAdapter.read.average",
"storageAdapter.write.average",
"sys.uptime.latest",
]
# host_metric_exclude = [] ## Nothing excluded by default
# host_instances = true ## true by default
#
## Clusters
cluster_metric_include = [] ## if omitted or empty, all metrics are collected
# cluster_metric_exclude = [] ## Nothing excluded by default
# cluster_instances = false ## false by default
#
## Datastores
datastore_metric_include = [] ## if omitted or empty, all metrics are collected
# datastore_metric_exclude = [] ## Nothing excluded by default
# datastore_instances = false ## false by default for Datastores only
#
## Datacenters
datacenter_metric_include = [] ## if omitted or empty, all metrics are collected
# datacenter_metric_exclude = [ "*" ] ## Datacenters are not collected by default.
# datacenter_instances = false ## false by default for Datastores only
#
## Plugin Settings
## separator character to use for measurement and field names (default: "_")
# separator = "_"
#
## number of objects to retreive per query for realtime resources (vms and hosts)
## set to 64 for vCenter 5.5 and 6.0 (default: 256)
# max_query_objects = 256
#
## number of metrics to retreive per query for non-realtime resources (clusters and datastores)
## set to 64 for vCenter 5.5 and 6.0 (default: 256)
# max_query_metrics = 256
#
## number of go routines to use for collection and discovery of objects and metrics
# collect_concurrency = 1
# discover_concurrency = 1
#
## whether or not to force discovery of new objects on initial gather call before collecting metrics
## when true for large environments this may cause errors for time elapsed while collecting metrics
## when false (default) the first collection cycle may result in no or limited metrics while objects are discovered
# force_discover_on_init = false
#
## the interval before (re)discovering objects subject to metrics collection (default: 300s)
# object_discovery_interval = "300s"
#
## timeout applies to any of the api request made to vcenter
# timeout = "60s"
#
## Optional SSL Config
# ssl_ca = "/path/to/cafile"
# ssl_cert = "/path/to/certfile"
# ssl_key = "/path/to/keyfile"
## Use SSL but skip chain & host verification
insecure_skip_verify = true
Обратите внимание, что использование insecure_skip_verify = true предназначено для использования с самозаверяющим сертификатом. Скорее всего, вы уже знаете, нужно ли устанавливать значение false для вашей среды.
Перезапустите контейнер Телеграф, чтобы применить новую конфигурацию:
docker compose restart telegraf
Давайте проверим, правильно ли передаются данные. Для этого можно запустить docker ps, чтобы получить идентификатор контейнера Telegraf:
tcude@monitoring02:~/monitoring$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7d9bf5c686ce telegraf "/entrypoint.sh tele…" 32 minutes ago Up 16 seconds 8092/udp, 8125/udp, 8094/tcp telegraf_container
718bb1181c55 grafana/grafana "/run.sh" 32 minutes ago Up 32 minutes 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp grafana_container
55949c1ea88b influxdb "/entrypoint.sh infl…" 32 minutes ago Up 32 minutes 0.0.0.0:8086->8086/tcp, :::8086->8086/tcp, 0.0.0.0:8089->8089/udp, :::8089->8089/udp influxdb_container
Для моей настройки у Telegraf ID 7d9bf5c686ce. Зная идентификатор контейнера, теперь можно запускать docker logs <container_id>. Вы должны увидеть что-то похожее на это:
2024-10-08T15:28:09Z I! Loading config: /etc/telegraf/telegraf.conf
2024-10-08T15:28:09Z W! DeprecationWarning: Option "force_discover_on_init" of plugin "inputs.vsphere" deprecated since version 1.14.0 and will be removed in 2.0.0: option is ignored
2024-10-08T15:28:09Z I! Starting Telegraf 1.28.5 brought to you by InfluxData the makers of InfluxDB
2024-10-08T15:28:09Z I! Available plugins: 240 inputs, 9 aggregators, 29 processors, 24 parsers, 59 outputs, 5 secret-stores
2024-10-08T15:28:09Z I! Loaded inputs: vsphere
2024-10-08T15:28:09Z I! Loaded aggregators:
2024-10-08T15:28:09Z I! Loaded processors:
2024-10-08T15:28:09Z I! Loaded secretstores:
2024-10-08T15:28:09Z I! Loaded outputs: influxdb_v2
2024-10-08T15:28:09Z I! Tags enabled: host=7d9bf5c686ce
2024-10-08T15:28:09Z W! Deprecated inputs: 0 and 1 options
2024-10-08T15:28:09Z I! [agent] Config: Interval:10s, Quiet:false, Hostname:"7d9bf5c686ce", Flush Interval:10s
2024-10-08T15:28:09Z I! [inputs.vsphere] Starting plugin
Телеграф взял файл telegraf.conf и все выглядит хорошо.
С InfluxDB и предоставлением ему данных Telegraf теперь мы можем настроить Grafana!
Настройка Grafana
Доступ к Grafana в http://<your_hostname>:3000 (учетные данные по умолчанию: admin/admin).
Измените пароль по умолчанию в целях безопасности.
Войдя в систему, перейдите в левое меню главной страницы. В разделе Connections выберите Data sources, а затем Add data sources
Теперь вам будет представлен список возможных вариантов источников данных. Выберите InfluxDB
Теперь вы захотите настроить источник данных InfluxDB аналогично тому, что у меня здесь:
Здесь стоит отметить пару моментов:
По умолчанию в качестве Query language будет использоваться InfluxQL. Я изменил это на Flux. InfluxQL — это SQL-подобный язык запросов для взаимодействия с InfluxDB, ориентированный на простоту и удобство использования, в то время как Flux — это новый, более мощный и функциональный язык сценариев данных, предназначенный для сложной обработки данных, преобразования и анализа с помощью InfluxDB.
В остальном вам просто нужно будет указать имя пользователя и пароль InfluxDB в разделе Basic Auth Details.
В InfluxDB Details вы будете использовать те же значения, которые мы использовали ранее. Token нужно заполнить значением токена API, которое мы получили ранее.
Теперь, когда с этим покончено, вы сможете нажать Save & test»
Предполагая, что все настроено правильно, вы должны увидеть что-то похожее на изображение выше.
Настройка дашборда в Grafana
Когда с трудной частью покончено, пришло время загрузить приборную панель! Для начала, используя то же левое меню, выберите Dashboards
Выберите Create Dashboard
Несмотря на то, что вы можете выбрать способ создания панели мониторинга вручную, существует также множество готовых панелей мониторинга, которые вы можете использовать для немедленной настройки и запуска. Их можно просмотреть, нажав Import dashboard»
Здесь вы можете найти идентификатор панели мониторинга, которую хотите использовать. Для моих целей я собираюсь начать с этой панели управления, которую можно найти, используя id 8159.
Все, что осталось, это в разделе InfluxDB выбрать источник данных InfluxDB. Затем нажмите Import»
Заключение
Теперь у вас должна быть рабочая панель управления Grafana!
Вот некоторые из других замечательных панелей VMWare, которые я нашел: