- Предупреждение: все изображения, представленные здесь, не являются реальными, а сгенерированы нейросетью.
Как ИИ генерирует картинку по линиям нашего рисунка.
Многие пользуются нейросетью только как "генератором случайных изображений на приблизительно описанную тему и сюжет". Как она построит кадр, что будет слева, что справа, где точно будет находиться указанный и описанный объект — все отпускают "на усмотрение нейросети", как ей вздумается, так и будет.
Такое положение вещей лично меня не устраивает, и я руковожу сим процессом самостоятельно, давая "художественного пенделя" сети, если она начинает уж слишком "самовольничать" (немного можно... но в меру!).
Ниже — максимум простой пример, как я даю указание нейросети где и что нарисовать.
Нейросеть может читать и обрабатывать любые изображения, извлекая из них информацию о цвете, композиции, линиях, пятнах, да о чем угодно, и выдавать ее в отличных от входного изображения форматах.
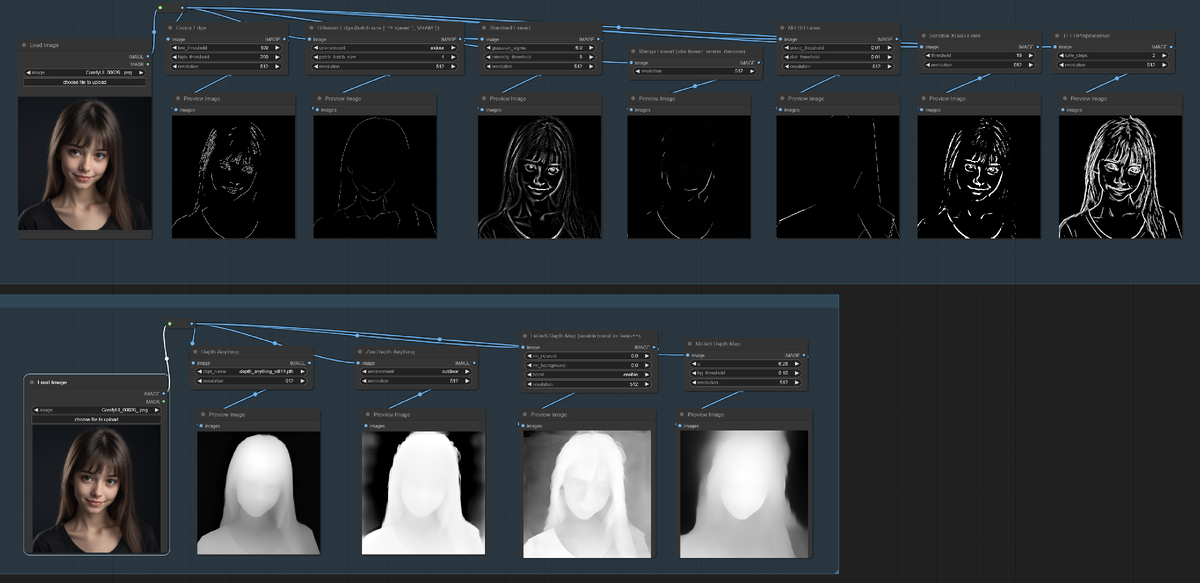
Как пример: обработка сетью обычного женского портрета. Программа может "вычленить" контуры, линии, пятна, тоновые переходы и т.п., и выдать на выходе только их. На снимке внизу 11 итоговых варианта преобразования входного изображения:
А здесь я даю команду нейросети "покажи мне возможные варианты преобразования исходного изображения". Она прочитает фото на входе, и на основании его выведет мне несколько вариантов того, КАК она может интерпретировать то, что увидела на входе.
Было БЕЗ преобразования:
Варианты преобразования (где каждый квадратик показывает мини-изображение, обработанное по определенной технологии):
Вот они крупно:
Нейросеть умеет как разбивать нормальную картинку на элементы (как тут), так и обратно из элементов создавать нормальное изображение используя их как "подсказку". Точно так же, как "вычленяет", нейросеть может и "прислушиваться" к изображению, которое ей подается на вход, и подстраивать то, что она рисует, под какой-то "примерный шаблон", поданный на вход.
Обычно мы работаем с нейросетью путем задания ей текстового описания того, что она должна сгенерировать на выходе, но часто этого бывает недостаточно для точного позиционирования объектов на "холсте", и приходится подключать технологию "графической подсказки".
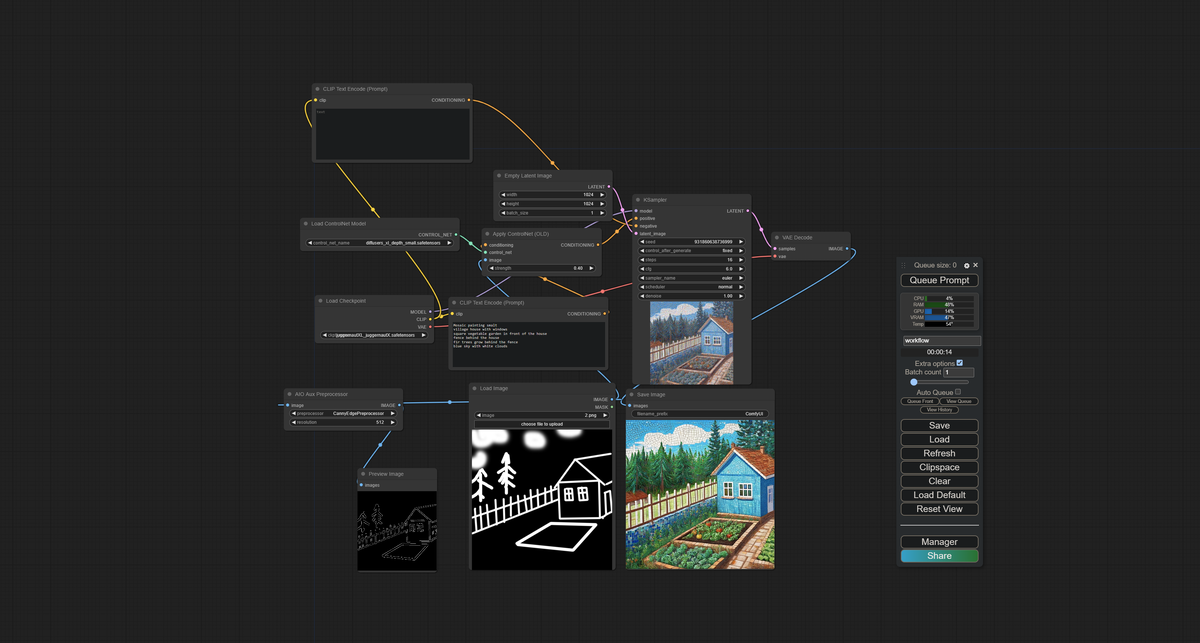
Создадим специально упрощенные: домик, дверь, забор, елки, огород, "типа облака":
(пример СПЕЦИАЛЬНО упрощен до уровня "Тяп-Ляп"!)
Загрузим наш домик в нейросеть, и создадим текстовое описание нашего "ТЯП-ЛЯП" рисунка (это как дети часто объясняют, что именно они нарисовали, если папа с мамой "не вдупляют"):
Описание рисунка:
- Фото высокого качества
- деревенский дом с окнами
- квадратный огород перед домом
- забор за домом
- ёлки растут за забором
- голубое небо с белыми облаками
... т.е. просто "описание всех объектов" на картинке и то КАК их надо интерпретировать — как "Фото высокого качества".
Теперь "скидаем схему" для нейросети, где создадим "смеситель" смешивающий в нужной пропорции "нашу картинку" и "наш текст", с "ручкой регулировки" для нейросети, которым будем задавать сети указание, к чему сильнее прислушиваться, к "нашей картинке" или к "нашему тексту":
Вариант 1 -
"Слушаться только текстового описания, игнорировать картинку"
Вариант 2 -
"Видеть только картинку, игнорировать текстовое описание"
Варианты, кроме 1 и 2
А дальше мы просто "крутим ручку смесителя", генерируя несколько картинок с разной степенью "смешения картинки и текстового описания" и выбираем лучшее, то, что нас устроит.
Вот на этом "уровне смешения" (красный кружочек) начала "проступать" картинка "из текста" на картинке "из картинки":
Картинка "фото-качества" начинает "проявляться" на нашей "каляке-маляке":
Еще больше "сдвигаемся" в сторону "текстового описания":
И еще больше:
И еще больше:
И еще больше:
Заметьте, что с каждым следующим "шагом смешивания", уменьшающего "вес" "нашей картинки", сеть вносит все больше и больше своих, "додуманных" ею объектов, чтобы "было похоже на реальное фото", но основная композиция все равно сохраняется! Пока появился лишь второй дом (которого не было на нашем рисунке), огород стал побольше, грядок прибавилось, количество окон у дома изменилось...
И вот на этом "уровне" (0.2), сеть уже почти не прислушивается к "нашей картинке", и почти все внимание перенесла на "текстовое описание".
Я заметил, что между 0.5 и 0.3 уровнями "смешивания" происходит переход от "примера картинки" к "описательному тексту", поищем "золотую середину":
Поставим уровень = 0.4
Пока я генерировал картинки остановив "фантазию нейросети" установив ей переключатель "варианты" а положение "fixed" (фиксировано).
Теперь я установлю его в положение "случайно" и сгенерирую 10 картинок с найденным мною уровнем смешения равным 0.4
Генерируем, смотрим (10 вариантов):
Обратите внимание КАК нейросеть "додумывает" все то, что не строго оговорено в "текстовом описании" сюжета, и отсутствует как "графическое описание" в "нашей картинке"!
Ну вот, это и был "самый топорный" пример, как и в чем человеку может помочь нейросеть в области генерации изображений.
А начиналось все вот с чего:
(Сам то я только так умею делать...)
Причем, я в качестве "модели" выбрал именно один из "фото-реалистичных" стилей создания картинки, а у меня их много всяких.
Давайте опять "зафиксируем композицию" и попробуем изменить СТИЛЬ рисования нейросети применительно к тому же сюжету:
Вот на немного другой "фото-реалистичной" модели рисования:
- А почему я написал в "тексте" как "Фото высокого качества" ???
А давайте заменим слова
- Фото высокого качества
на
- Детский рисунок акварелью
Смотрим:
Теперь заменим на "Картина маслом мастихином"
Смотрим:
А теперь на "Картина мозаичной смальтой"
Смотрим:
Ну вот, как то так...
P.S.
А сам я (от руки) рисовать вообще не умею, только так...
Продолжение тут (
)
На главную:
Удачи!
NStor
https://t.me/stable_cascade_rus
https://t.me/srigert