Всем привет! Сегодня расскажу о новой для себя теме — бенчмарках, и как с их помощью измерять время выполнения и расход памяти.
Введение
Что такое бенчмарк? Это специальная библиотека, а так же созданное с её помощью приложение. В этом приложении мы пишем некоторое количество бенчмарк-тестов, для которых хотим сравнить время выполнения и расход памяти. После чего мы запускаем его, приложение (с помощью добавленной в него библиотеки) запускает наши тесты много раз, измеряет среднее время выполнения, расход памяти, количество мусора в разных поколениях сборщика и другие показатели (в зависимости от настройки) и выводит результаты в табличной форме на консоль.
Где применять
Бенчмарк довольно сильно нагружает процессор и память (даже в документации указано — при работе с ноутбука обязательно включать его в сеть, чтобы режим энергосбережения не замедлял работу и не давал ложные результаты). Тесты выполняются много раз, чтобы получить большой набор данных по результатам и исключить возможные выбросы в результатах.
Отсюда вывод — нельзя просто взять и прикрутить бенчмарк к нашему рабочему приложению (любому), потому что он предназначен для тестирования производительности. Оно проводится на этапе разработки для отдельных методов, а в самом приложении не проводится, потому что было бы странно в течение работы приложения запускать какой-либо метод 100 раз, чтобы посчитать скорость выполнения. Пользователь скажет "классно, что у вас так быстро считается всё, всего 30 наносекунд. Но почему я каждый раз жду этого подсчёта по полминуты".
Поэтому бенчмарки применяются для того, чтобы сравнить, какой из нескольких возможных подходов к выполнению какой-либо операции будет самым эффективным. Например, какой алгоритм быстрее отсортирует большой набор данных, какая способ выполнения операции отработает быстрее, каким образом мы обработаем больше запросов к серверу и так далее. Выбрав оптимальный способ, мы используем его в своём приложении
На чём будем проверять
В комментариях к прошлому посту об этой статье в моём телеграм-канале (не забывайте подписаться) возникла дискуссия о том, каким способом лучше сравнивать строки при сортировке листов по их номерам. Номера следует сортировать не по правилам сортировки строк, а по правилам сортировки чисел, но проблема в том, что в номерах строк могут быть символы, не являющиеся числами, и нам надо их отбросить.
Мне предложили использовать вместо моего способа (самописный IComparer для строк) использовать другие — встроенный Comparer из Windows, и Comparer из nuget-пакета NaturalStringComparer. Что ж, давайте попробуем создать бенчмарк-приложение и сравнить эти 3 способа:
Часть 1. Бенчмарк в консольном приложении
Как правило, для создания бенчмарков используется библиотека BechmarksDotNet. Создадим консольное приложение, добавим туда эту библиотеку и создадим пару бенчмарков. Жмём правой кнопкой мыши на проект — Управление пакетами nuget и устанавливаем нужную библиотеку:
Создадим класс StringBenchmark и для начала добавим к нему атрибуты:
[MemoryDiagnoser]
[SimpleJob(RuntimeMoniker.Net80)]
[SimpleJob(RuntimeMoniker.Net48)]
Первый атрибут позволит нам увидеть в результатах ещё и расход памяти, помимо времени выполнения.
А с помощью второго и третьего атрибута мы сравним показатели выполнения для .NET 4.8 (применяется в Revit 2020-2024), и для .NET 8 (применяется в Revit 2025.
Далее определим набор строк, который мы будем сортировать. Я создал набор строк в обратном порядке, чтобы усложнить работу алгоритму сортировки:
private readonly string[] _numbers =
{
"99", "98", "97", "094", "93", "85", "81", "079", "73", "72", "60", "0052", "51", "50", "47",
"43", "42", "041", "35", "00030", "21", "019", "18", "11", "10", "09", "5", "4", "03", "1",
};
И определим 3 метода с атрибутом [Benchmark] для тестирования:
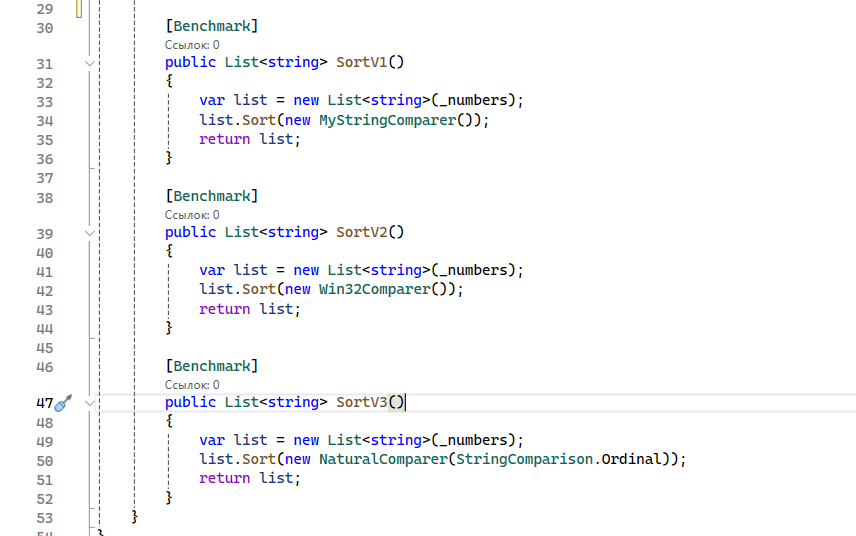
Методы возвращают не void, а список строк, потому что бенчмарк работает в конфигурации Release. В этой конфигурации по умолчанию применяются оптимизации кода, поэтому он работает быстрее. Если JIT-компилятор увидит, что мы сортируем массив, но ничего не возвращает, он может понять это, и не вычислять значение переменное, которое в будущем нигде не используется. Поэтому я копирую массив (чтобы он не оказался потом отсортированным в памяти), и каждый раз сортирую его заново.
Чтобы убедиться, что копирование массива не влияет на результат, я сделал дополнительный бенчмарк для копирования массива:
Итоговый класс получился вот таким:
Часть 2. Определение IComparer-ов
У меня применяются 3 Comparer для строк. Первый я написал вот для предыдущей статьи (тут я назвал его MyStringComparer), второй — сделан с помощью Win32API (Win32Comparer), а третий взят напрямую из nuget-пакета. Давайте взглянем на их код:
NaturalStringComparer не влезет на скрин, его исходный код лежит здесь
Часть 3. Настройка Program.cs и .csproj
Файл Program.cs получился очень простым:
Для того, чтобы код выполнился в 2 версиях .NET, нам надо нажать правой кнопкой мыши на проект в обозревателе решений — Изменит файл проекта:
И указать 2 TargetFrameworks:
Запуск
Всё готово, приложение можно запускать. Не забудьте установить конфигурацию Release и запускайте приложение без отладки, чтобы все оптимизации применились:
Всё скомпилировалось и запустилось, смотрим результаты:
Что ж, давайте посмотрим на картинку и сделаем выводы:
- Время для копирования массива составляет очень маленькую часть от времени сортировки и не особо влияет на результат.
- За счёт оптимизаций среды выполнения в .NET 8 программа выполняется намного быстрее. То есть в Revit 2025 плагины должны работать быстрее.
- Сортировке 2 способом (через Win32) практически всё равно, в какой среде мы её выполняем — на неё оптимизации не действуют. Причина этого в том, что мы вызываем исходный код Windows при импорте сборке, и по сути в обоих случаях выполняется один и тот же код WIndows (а для наших сортировок он разный, потому что среды выполнения компилируют его по разному). За счёт этого в .NET 4.8 этот код быстрейший, а в .NET 8 он уже уступил всем. Так что если пишите для Revit 2020 — 2024, смело используйте Comparer из Win32 — он и быстрее, и лучше сравнивает (относительно моего самописного)
- Мой самописный Comparer показал чуть более быстрые результаты относительно nuget-Comparer в .Net 4.8, но уступил в .NET 8. Я думаю, это связано с использованием ReadOnlySpan, и в .NET 8 они лучше оптимизированы. Впрочем, в обеих средах мой Comparer проигрывает по памяти
- Ну и самое главное — разница во времени выполнения в абсолютном времени для всех 3 вариантах настолько мала, что в принципе всё равно, чем пользоваться. Я бы советовал брать WIn32Comparer — он не добавляет дополнительных библиотек в итоговую сборку и даёт простое и удобное сравнение "прямо как в проводнике" без лишних заморочек и дописываний.
Заключение
Итоговый код вы можете посмотреть здесь. Вы можете клонировать репозиторий, запустить код у вас и посмотреть результаты на вашем компьютере. А ещё вы теперь знаете, как пользоваться бенчмарками и где найти справку по ним.
Не забывайте подписываться на мой телеграм-канал и мой GitHub, ставить лайки статьям и звёздочки репозиториям. До новых встреч!