🚀 Всем data привет!
Вам необходимо проверять сходство или различие данных? Возможно, вы уже используете некоторые методы в своей работе или учебе. В этой статье я подробно рассмотрю три подхода к оценке данных:
- Population Stability Index (PSI)
- Критерий Колмогорова-Смирнова
- Adversarial Validation Score
Мы пошагово разберём, как рассчитывать эти популярные метрики с визуальными примерами.
Весь код и дополнительные комментарии доступны на моём GitHub.
Population Stability Index (PSI)
Population Stability Index (PSI) — это метрика, оценивающая изменения в распределении данных между двумя временными периодами или наборами данных. Она часто используется в кредитном скоринге и других областях, где важно отслеживать стабильность данных и ML моделей.
Почему важен PSI?
PSI помогает выявить значительные изменения в данных, которые могут указывать на проблемы, такие как ухудшение качества данных, изменения в поведении клиентов или необходимость обновления ML модели.
Как рассчитывается PSI?
Получаем два распределения данных и сравниваем их визуально.
Разбиваем данные на n бинов (например, 4).
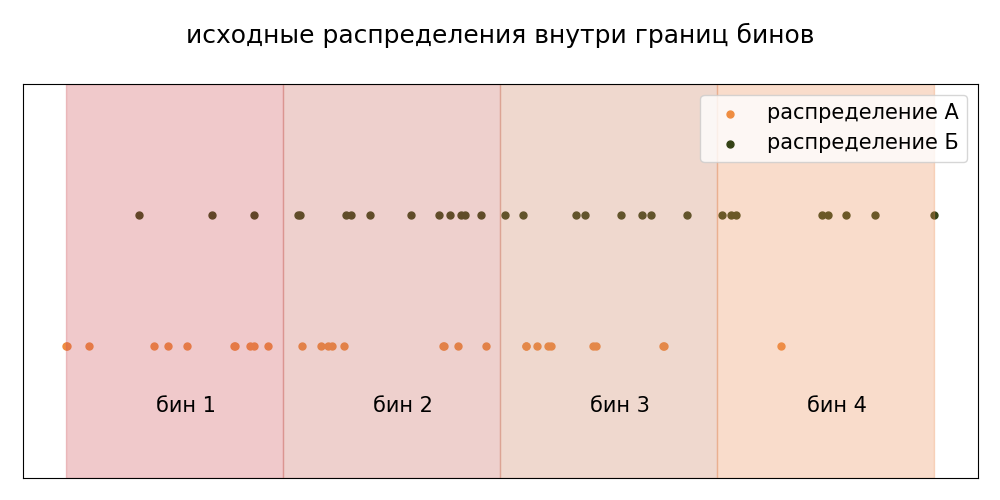
Считаем количество элементов в каждом бине для обоих распределений.
Вычисляем разницу в количестве элементов для каждого бина и делаем её относительной.
Делим попарно значения количества элементов для каждого бина.
Используем формулу для расчёта PSI
PSI = Σ (распределение_а% – распределение_б%) * ln(распределение_а% / распределение_б%)
Критерий Колмогорова-Смирнова
Критерий Колмогорова-Смирнова — непараметрический тест для сравнения двух выборок или проверки соответствия одной выборки теоретическому распределению. Он оценивает различия между эмпирическими функциями распределения (ЭФР) двух выборок.
Как рассчитывается статистика из критерия Колмогорова-Смирнова?
Сортируем значения в каждом распределении и визуально оцениваем данные.
Определяем проверяемую гипотезу: одно распределение может быть "меньше" или "больше" другого.
Находим максимальные различия между эмпирическими функциями распределения, которые называются статистикой Колмогорова-Смирнова.
Adversarial Validation Score
Adversarial Validation Score используется для оценки различий между двумя выборками данных, например, между тренировочной и тестовой в задачах машинного обучения.
Как рассчитывается Adversarial Validation Score?
Размечаем данные бинарной переменной, где каждая выборка получает свою метку. Эта метка становится целевой переменной для классификатора, задача которого — определить, к какому распределению относится каждый семпл данных. Качество предсказаний измеряется метрикой бинарной классификации — ROC AUC Score.
Если распределения схожи, значение ROC AUC будет ≤ 0.55, если сильно различаются — ≥ 0.85 (верхняя граница условная и может варьироваться в зависимости от задачи).
Заключение
Каждый из этих методов актуален и полезен для оценки двух распределений данных и активно используется в индустрии. Надеюсь, этот детальный разбор был вам полезен.
Больше полезных и интересных материалов вы найдёте в моём Telegram-канале: https://t.me/+V6en3uh-2qUyYzgy