Некоторе время назад я уже писал про динамическую организацию второй линии. Динамичность второй линии с одной стороны обусловлена необходимостью оперативного переключения аналитиков второй линии на задачи аналитиков первой линии, в случае завала последних, а с другой стороны, как отмечалось и ранее, это позволяет каждому аналитику поработать на разных задачах. Переключение между разными задачами в рамках одной операционной группы позволяет создать хотя бы какие-то условия для отдыха от рутины.
В нашем случае состав аналитиков второй линии меняется каждую неделю, а с учетом необходимости латания сменных графиков из-за отпусков и больничных (здесь следует отметить замечательный доклад про организацию наших сменных графиков на SOC Forum 2023 от моего коллеги и друга Альберта - От ночных недосыпов к work-life balance, или как организовать комфортный график дежурств для аналитиков - слайды, видео), за месяц в роли второй линии успевают побывать десятки аналитиков. При таких объемах для достижения наибольшей эффективности команды, что исключить дублирование функционала, работу второй линии уже необходимо планировать.
В статье перечислены задачи второй линии, это не полный перечень, и в вашем случае он может быть совсем другой, объединяющий фактор здесь - все работы, выходящие за рамки триажа алертов от систем обнаружения. При составлении графика второй линии, эти работы необходимо расписать по исполнителям. Сменные графики аналитиков составляются на месяц, удобно и графики работы второй линии также делать на месяц.
Чтобы не быть голословным приведу фрагмент нашего графика на сентябрь 2024.
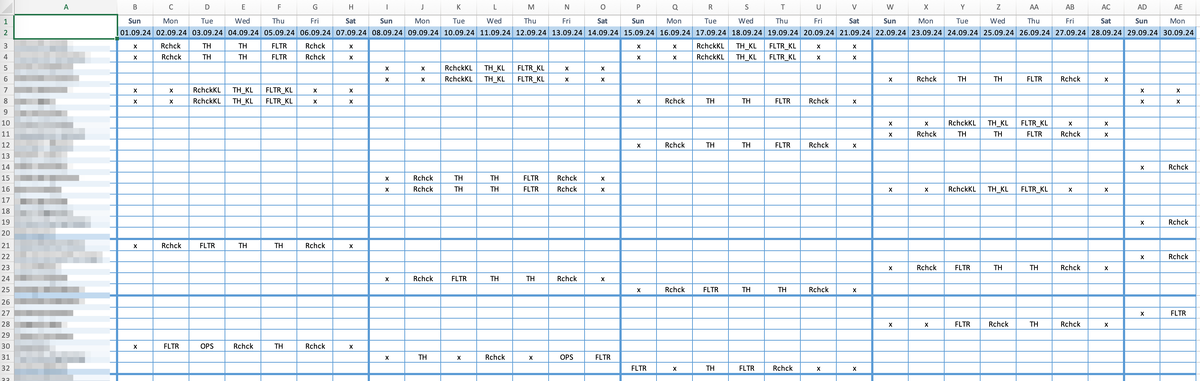
Как видно, график второй линии (или VSL, virtual second line, как мы ее называем внутри) очень похож на сменный график: строчки - аналитики, столбики - даты, ячейки-пересечения - фактическая работа, выполняемая аналитиком, весь месяц развернут в строчку, как и в сменном графике - это упрощает программный парсинг и совмещение этих двух графиков. Поскольку команда международная, все, к сожалению, не по-русски. Для лучшего восприятия картинки, поясню работы в ячейках: x - эквивалент пустой ячейки - в эту дату аналитик не работает в роли второй линии; Rchck - перепроверка работы других аналитиков (заметил, что нет публикации, надо будет исправить, вопрос очень важный, но я об этом рассказывал в докладах, например), FLTR - работа с ложными срабатываниями в общем случае, TH - ручной хантинг. Суффикс KL означает, что работа выполняется по внутреннему заказчику, так как не все члены операционной команды авторизованы для работы по внутренним инцидентам (схожая схема и с данными клиентов в разных регионах: не все аналитики авторизованы на доступ ко всем данным). Перечень работ может со временем расширяться, как угодно изменяться в общем случае.
Чтобы все совсем было контролируемо и красиво, работы VSL надо учитывать с какой-нибудь трекинговой системе, типа Jira или TFS, а для контроля успешности, каждую работу VSL обложить метриками результативности и эффективности, что эта работа по-прежнему решает проблему, являющуюся причиной появления этой работы, и решает ее наиболее дешевым способом.