12 сентября компания OpenAI представила новую большую языковую модель OpenAI o1, обученную с помощью метода «обучение с подкреплением» для выполнения сложных рассуждений. Эта модель способна создавать длинную «цепочку мыслей» прежде чем ответить пользователю, что делает её более продвинутой, чем предыдущие модели.
OpenAI o1 занимает 89-й процентиль в соревновательном программировании (Codeforces) и входит в число 500 лучших «студентов» США в отборочном туре на математическую олимпиаду США (AIME). Кроме того, она превосходит точность уровня доктора наук в тесте задач по физике, биологии и химии (GPQA).
Компания OpenAI выпустила раннюю версию модели OpenAI o1-preview для использования в ChatGPT и для пользователей API. Эта модель прошла тестирование на различных экзаменах и бенчмарках машинного обучения, показав значительное улучшение рассуждений по сравнению с предыдущей моделью GPT-4o.
OpenAI провела тестирование модели на различных задачах, включая математические задачи, задачи по физике, биологии и химии, а также задачи по программированию. Результаты показали, что OpenAI o1 значительно превосходит предыдущую модель GPT-4o в большинстве задач, требующих рассуждений.
На экзаменах AIME 2024 года GPT-4o решила в среднем только 12% (1,8/15) задач. OpenAI o1 в среднем набрала 74% (11,1/15) с одним образцом на задачу, 83% (12,5/15) с консенсусом среди 64 образцов и 93% (13,9/15) при повторном ранжировании 1000 образцов с помощью усвоенной функции подсчёта баллов.
Компания также оценила OpenAI o1 по GPQA diamond, сложному тесту интеллекта, который проверяет знания в области химии, физики и биологии. Чтобы сравнить модели с людьми, OpenAI наняла экспертов с докторской степенью для ответа на вопросы GPQA-diamond. Результаты показали, что OpenAI o1 превзошла результаты экспертов, став первой моделью, сделавшей это в этом тесте.
Кроме того, OpenAI провела тестирование модели на человеческих предпочтениях, показав, что OpenAI o1-preview предпочтительнее GPT-4o в категориях, требующих рассуждений, таких как анализ данных, написание кода и математика. Однако OpenAI o1-preview не является предпочтительным для некоторых задач на естественном языке, что говорит о том, что она подходит не для всех сценариев использования.
OpenAI o1 также показала улучшение производительности при ключевых оценках джейлбрейка и внутренних бенчмарках для оценки границ отказа безопасности модели.
Компания планирует выпустить улучшенные версии этой модели по мере продолжения итераций. Новая возможность «рассуждений» улучшит способность согласовывать модели с человеческими ценностями и принципами, открывая новые варианты использования ИИ в науке, кодировании, математике и смежных областях.
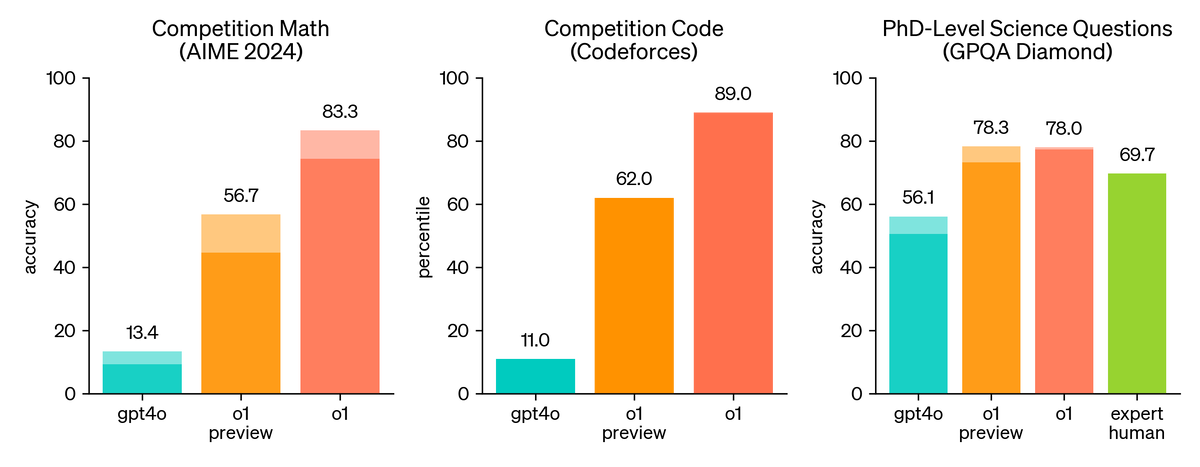
Цепочка рассуждений предоставляет новые возможности для согласования и безопасности. Компания обнаружила, что интеграция своих политик для поведения модели в «цепочку мыслей» является эффективным способом надёжного обучения человеческим ценностям и принципам. Обучая модель своим правилам безопасности и тому, как рассуждать о них в контексте, компания обнаружила доказательства того, что способность рассуждений напрямую увеличивает надёжность модели.
Для стресс-тестирования своих улучшений компания OpenAI провела ряд тестов безопасности и red-teaming [методология, используемая для тестирования и оценки безопасности, основная идея которой заключается в том, чтобы создать команду, которая будет играть роль «атакующей стороны», чтобы выявить уязвимости и слабые места в системе или стратегии] перед развёртыванием в соответствии со своей структурой готовности. Результаты показали, что цепочка рассуждений способствовала улучшению возможностей в их оценках.
Компания OpenAI считает, что скрытая цепочка мыслей представляет собой уникальную возможность для мониторинга моделей. Если она верна и понятна, то позволяет понимать «мыслительный процесс» модели. Однако для того, чтобы это работало, модель должна иметь свободу выражать свои мысли в неизменённой форме, поэтому OpenAI не может обучать какое-либо соответствие политике или предпочтениям пользователя в цепочке мыслей.
Взвесив множество факторов, включая пользовательский опыт, конкурентное преимущество и возможность продолжить мониторинг цепочки рассуждений, OpenAI решила не показывать пользователям необработанные цепочки. Компания признаёт, что это решение имеет недостатки. Чтобы частично компенсировать это, OpenAI обучает модель воспроизводить любые полезные идеи из цепочки мыслей в ответе. Для серии моделей o1 OpenAI показывает сгенерированное моделью резюме «цепочки мыслей».
Стоимость модели o1-preview составляет $15,00 за 1 млн входных токенов и $60 за 1 млн выходных токенов.
OpenAI o1 представляет собой значительный шаг вперёд в области искусственного интеллекта. Эта модель способна решать сложные задачи, требующие рассуждений, и показывает улучшение производительности по сравнению с предыдущими моделями. Компания OpenAI планирует продолжить развитие этой модели и выпустить улучшенные версии.