
Что необходимо сделать:
Подключитесь к СУБД через psql и создайте базу данных skillbox_db, которая должна быть доступна юзеру, указанному в env-переменных.
С помощью метакоманд подключитесь к созданной базе данных и создайте таблицу test_psql_table.
Во flask-приложении с помощью ORM SqlAlchemy настройте соединение со skillbox_db и опишите модели пользователя и кофе, который предпочитает пить наш пользователь:
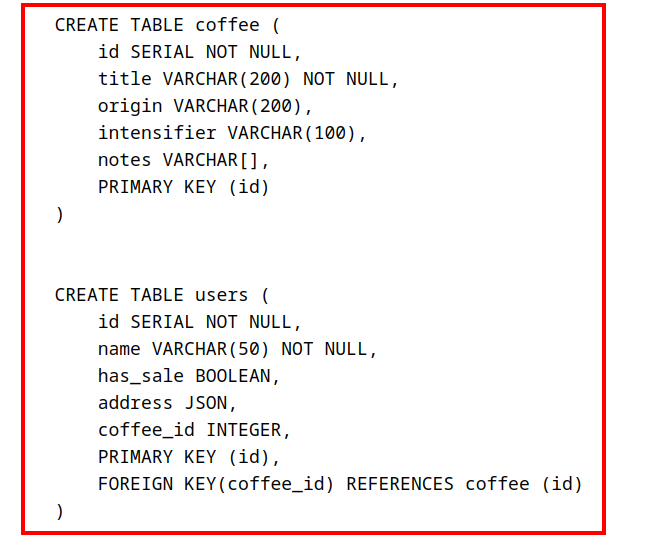
мы имеем вот такой qsl-скрипт по созданию таблиц coffee и users
С помощью функции before_first_request создайте десять пользователей и десять сортов кофе.Для этого воспользуйтесь сервисом генерации тестового api-ответа Для заполнения атрибута address у пользователей — https://random-data-api.com/api/address/random_address.
Для кофе — https://random-data-api.com/api/coffee/random_coffee. Обработайте ответ получения кофе, где title=blend_name, origin=origin, notes=notes, intensifier=intensifier.
Для пользователя поле name и связь с кофе заполните рандомно.
Создайте роуты для выполнения запросов (название не играет роли).Добавление пользователя. В ответе должна быть информация о новом пользователе с его предпочтением по кофе.
Поиск кофе по названию (используйте полнотекстовый поиск, название — входной параметр).
Список уникальных элементов в заметках к кофе.
Список пользователей, проживающих в стране (страна — входной параметр).
Ну и соответственно я начал с самого начала, с запуска сервиса докер, после чего запуск контейнера skillbox-postges, вход в psql и создание базы данных skillbox_db:
- systemctl start docker.service
- docker run --name skillbox-postgres --rm -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres -e PGDATA=/var/lib/postgresql/data/pgdata -v /tmp:/var/lib/postgresql/data -p 5432:5432 -it postgres
- docker exec -it skillbox-postgres /bin/sh
- # psql -U postgres
P.S. При запуске контейнера skillbox-postgres способом, описанным выше есть небольшая проблема, после перезагрузки компа все базы, таблицы и юзеры пропадают, и на следующий день приходится всё восстанавливать. Мелочь, а неприятно!
И да, мне надоело каждый день запускать сервис докера, поэтому я не поленился и нашел решение, чтобы он в следующие разы запускался со стартом системы:
Ну и инструкция, как развернуть постгрес докер контейнер на своем линух компе
После чего получаем консоль управления базами данных:
Если абы чего написать в качестве пользователя БД и пароля, при создании движка (engine), и postgres всё примет - как бы не так, выскочит ошибка нужно создать пользователя test_db, ну и присвоить ему пароль, и чтобы данный пользователь имел право совершать действия с таблицами в БД. Я, на данный момент, не придумал ничего лучше как наделить пользователя правами суперпользователя.
Хотя и понимаю, что суперпользователем он должен быть только для этой БД (может разберусь как сделать по другому). Если вы это знаете - напишите в комментах.
Тестовая база данных нужна для того чтобы правильно написать модель, потому как некоторые поля у меня вызывают вопросы, например что за поле типа VARCHAR[ ], что-то типа списка, а как его написать в sqlalchemy?
Искал совпадения (LIST, DICT, SET), оказалось ключевое слово ARRAY и вот какая получилась модель таблицы coffee:
Осталось дело за малым - написать таблицу юзеров:
!!! Эти модели не совсем верные, в последствии, это приведет к ошибке, при поиске пользователей из определенной страны!!! Смотри ниже, правильные модели!!!
Ну вот, задача выполнена, пока у меня написан код только на создание таблиц в базе данных, один единственный роут, перед выполнением которого, запускается очистка таблиц и создание их заново:
Ну и собственно engine:
Ну вот можно теперь подумать о создании массива из 10 пользователей и 10 сортах кофе, которые нужно загрузить в базу данных, согласно заданию выше.
SkillBox предоставил нам две ссылки для получения данных по адресам для наших пользователей и для данных по сортам кофе. Но эти ссылки предназначены для получения одного экземпляра данных (для одного пользователя и для одного сорта кофе) а нам нужно 10!!! Я было попытался создать цикл из десяти запросов, но на сайте установлена защита от DDOS атак, он просто не дает делать много запросов в короткие промежутки времени. Я было даже попытался создать свои собственные конструкции, но быстро понял что это все не то...
Когда я уже настряпал своих JSONов, и сделал чтобы оно у меня все работало, до меня дошло - ведь наверняка можно как то получить сразу 10 пакетов данных для того и другого запроса а не "городить огород" и не изобретать велосипед. Скиллбокс мог бы и подсказать ответ на этот вопрос в описании к домашней работе. Надо просто было дописать в конце адреса "?size=10". Я перебрал много вариантов ключевого слова... В конечном итоге ссылки стали выглядеть так:
Ну а из своих "сочинений" в "RandomDataAPI" я использовал лишь получения имен пользователей, чот мне не захотелось фантазировать над их именами. Итак, получение данных:
Изначально, заполнение таблиц полученными данными, я организовал при помощи @app.before_request, но понял что эта штука мне не годится для работы над последующими пунктами домашнего задания, потому как перед каждым запросом обновляет данные в таблицах. Ты делаешь поиск по марке кофе или пользователя по стране а у тебя перед этим все марки кофе и страны сменились... Поэтому before_request отправил в комментарии до лучших времен.
А вместо этого воспользовался главным эндпойнтом для создания и обновления таблиц:
Ну вот таблицы созданы, можно заняться реализацией роутов:
Для отправки запросов к эдпойнтам я пользуюсь программой httpie (http) некое подобие curl и все скриншоты запросов будут показаны через использование этой программы. В Manjaro Linux (я пользуюсь этой системой) эта программа устанавливается обычным pacman:
sudo pacman -S httpie
Добавление пользователя. В ответе должна быть информация о новом пользователе с его предпочтением по кофе
Поиск кофе по названию (используйте полнотекстовый поиск, название — входной параметр)
Тут перед запросом нужно посмотреть в БД какие марки кофе у нас имеются чтобы правильно составить запрос, а чтобы ответ был более полным, я изменю какую нибудь марку кофе чтобы слово поиска встречалось не в одной марке кофе а в, скажем, трёх местах и соответственно выдача результата была - три вида кофе:
Как можно видеть, поиск выдал три марки кофе в котором встречается слово "Light"
Список уникальных элементов в заметках к кофе.
В этом пункте нам нужно пройтись по всем массивам в notes и собрать в список только уникальные элементы.
Список пользователей, проживающих в стране (страна — входной параметр)
Вот здесь у меня возникли трудности, потому как неверно задал модель адреса пользователя. Тут нужно было импортировать JSON из:
- from sqlalchemy.dialects.postgresql import JSON
А я импортировал из чего-то другого (вот даже и не припомню уже из чего, а лезть в GIT и смотреть - лень)
Как и писал выше, вот полная рабочая модель:
Ну и собственно сам запрос пользователей "по городу":
Так как данные у нас динамичные и могут меняться, 'Germany' может не быть, поэтому я насильно напишу данную страну в базе данных, в поле адрес:
Хотя, не исключаю что, возможно, и еще в каких то строках имеется страна - Германия... Одна точно теперь есть в базе данных!
Ну вот, вроде бы и готовы все пункты задания. Осталось только сделать задание с миграциями...
На том сказочке конец, а кто изучал - молодец!