Учёные представили новую мощную ИИ-технологию для создания масштабируемых 3D-моделей. VFusion3D решает проблему нехватки 3D-данных для обучения ИИ и создания контента — вместо использования существующих 3D-моделей, VFusion3D обучается на текстах, изображениях и видео.
Исследователи утверждают, что VFusion3D "может генерировать 3D-объект из одного изображения за считанные секунды", демонстрируя при этом высокое качество и точность. Если создаваемые модели действительно окажутся на высоте, это значительно упростит работу в таких областях, как геймдизайн, VR и цифровое проектирование.
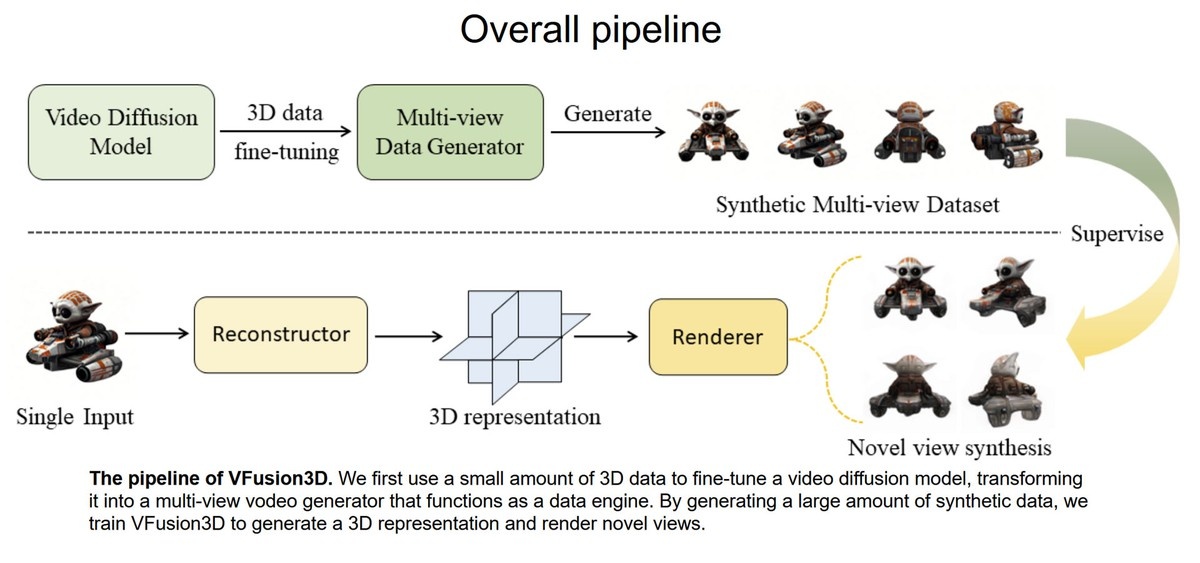
Команда, возглавляемая Джунлином Ханом, Филиппосом Коккиносом и Филипом Торром, разработала специальный конвейер для VFusion3D, в котором небольшое количество 3D-данных используется для тонкой настройки модели видео-диффузии. Видео были выбраны в качестве основного источника данных, так как они часто показывают объект с разных углов, что способствует точному воспроизведению в 3D.
Для модели видео исследователи выбрали EMU Video, обученную на различных роликах, включая панорамные съемки объектов и кадры с дронов. Такие видеоматериалы содержат подсказки о 3D-структуре мира, что позволяет VFusion3D генерировать высококачественные 3D-объекты из одного изображения независимо от угла обзора.

Кроме того, разработчики сравнили VFusion3D с другими 3D-генеративными моделями, чтобы оценить качество и производительность. В проекте на GitHub, который курирует Джунлин Хан, можно найти примеры анимированных объектов, созданных VFusion3D, и их сравнение с конкурентами.
Желающие могут протестировать VFusion3D через доступную онлайн-демонстрацию, где можно загрузить изображение и получить 3D-модель. Однако очередь из желающих большая.