Введение
Современные модели обработки естественного языка, такие как GPT (Generative Pretrained Transformer), становятся всё более популярными благодаря их способности генерировать текст, продолжать диалоги и выполнять другие задачи на естественном языке. Однако, для достижения наилучших результатов, иногда требуется адаптация модели под специфические нужды с использованием пользовательских данных. В этой статье мы рассмотрим, как создать графический интерфейс на PyQt6 для настройки и обучения модели GPT с использованием библиотеки transformers от Hugging Face.
Описание проекта
Этот проект предоставляет удобный графический интерфейс для обучения кастомной GPT модели с пользовательским датасетом. Интерфейс поддерживает выбор путей к модели и датасету, настройку параметров обучения, а также мониторинг прогресса обучения в реальном времени. Обучение модели выполняется в отдельном потоке, что позволяет интерфейсу оставаться отзывчивым.
Основные компоненты
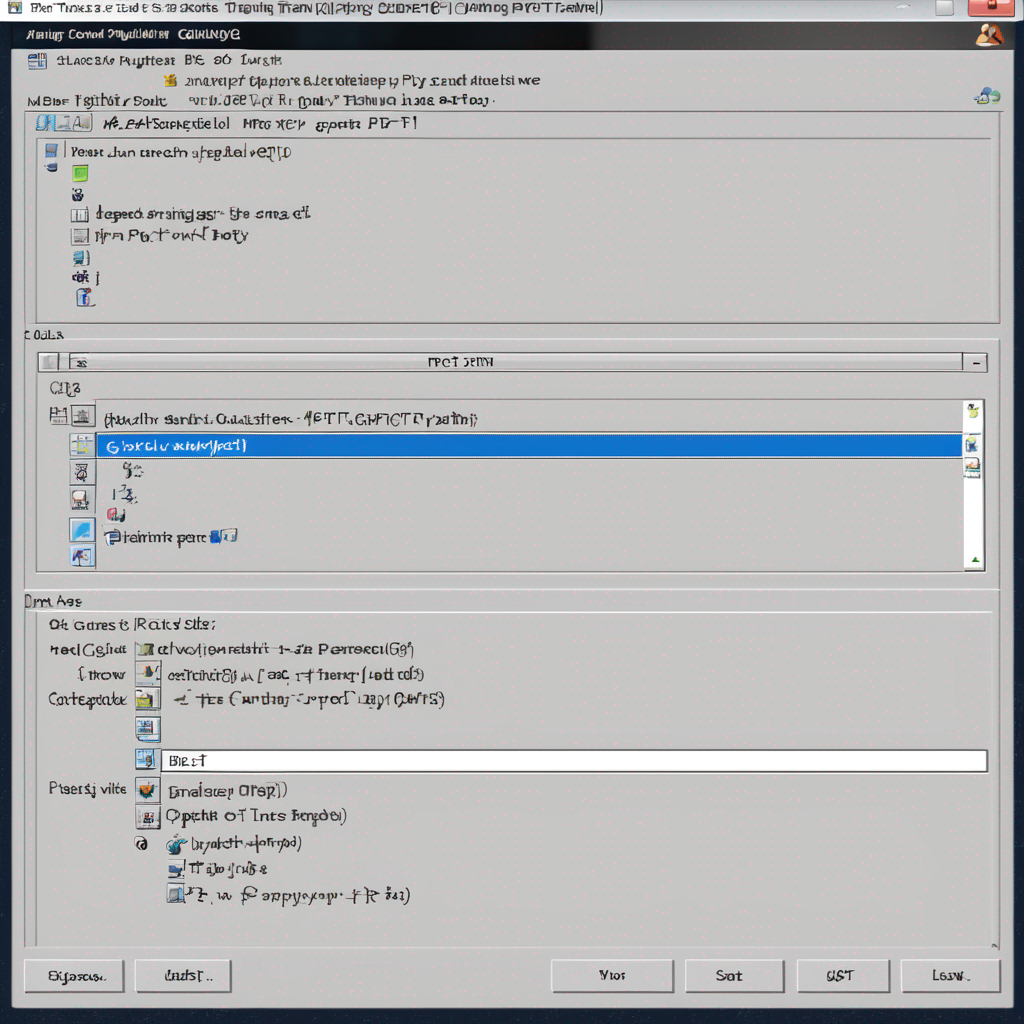
- Интерфейс пользователя (GUI)Интерфейс реализован с использованием PyQt6 и состоит из двух вкладок:Обучение: В этой вкладке пользователь может запустить процесс обучения, остановить его, а также наблюдать за логами и прогрессом выполнения.
Настройки: Здесь пользователь может указать путь к модели и датасету, а также настроить размер батча. - Обработка данныхДля загрузки данных используется кастомный класс CustomTextDataset, который преобразует текстовый датасет в формат, пригодный для обучения модели GPT. Он разбивает текст на блоки фиксированного размера и кодирует их с помощью токенизатора.
- Поток обученияКласс TrainingWorker реализует процесс обучения в отдельном потоке, чтобы основной интерфейс оставался интерактивным. Поток получает на вход модель, датасет, устройство (CPU или GPU), параметры обучения и управляет процессом обучения, включая оптимизацию и сохранение модели.
Как работает приложение?
- Настройка интерфейсаВ главном классе MainWindow создается основной интерфейс с двумя вкладками: "Обучение" и "Настройки". Вкладка "Обучение" содержит кнопки для запуска и остановки обучения, текстовое поле для логов, прогресс-бар, а также поля для ввода количества эпох. Вкладка "Настройки" позволяет указать путь к модели и датасету, а также задать размер батча.
- Загрузка и обработка данныхДля обучения модели используется кастомный датасет, загружаемый из текстового файла. Датасет разбивается на примеры фиксированного размера, каждый из которых кодируется с помощью токенизатора GPT. Этот процесс обеспечивает, чтобы модель могла эффективно обрабатывать входные данные во время обучения.
- Процесс обученияПосле запуска обучения, приложение создает поток TrainingWorker, который отвечает за выполнение всех шагов обучения:Загрузка модели и токенизатора
Модель и токенизатор загружаются из указанного пользователем пути.
Создание оптимизатора и планировщика обучения
Для обновления весов модели используется оптимизатор AdamW, а планировщик StepLR управляет скоростью обучения.
Обучение модели
Модель обучается на заданном количестве эпох, и на каждом шаге обновляется лог и прогресс-бар.
Сохранение модели
По завершении обучения, модель и токенизатор сохраняются в указанную директорию. - Мониторинг и управление процессомВо время обучения пользователю отображаются текущие логи и прогресс в процентах. Если необходимо остановить обучение, можно нажать кнопку "Остановить обучение", которая прекратит выполнение потока и сохранит текущее состояние модели.
Применение и возможности
Это приложение идеально подходит для исследователей и разработчиков, работающих в области обработки естественного языка, которые хотят обучить кастомную модель GPT на своих данных. Интерфейс позволяет легко настроить процесс обучения без необходимости писать код, а также предоставляет полный контроль над настройками модели и параметрами обучения.
Заключение
Проект представляет собой удобный инструмент для обучения моделей GPT с использованием пользовательских данных. Он объединяет мощь библиотек PyTorch и Hugging Face с интуитивным графическим интерфейсом, что позволяет пользователям быстро и эффективно настраивать и обучать свои модели, не погружаясь в детали программирования. Этот подход упрощает процесс разработки и экспериментирования с моделями NLP, делая его доступным даже для пользователей без глубоких знаний в области машинного обучения.
Сам скрипт:
import sys
import os
import torch
from torch.utils.data import DataLoader, Dataset
from transformers import GPT2Tokenizer, GPT2LMHeadModel
from torch.optim import AdamW
from torch.optim.lr_scheduler import StepLR
from PyQt6.QtWidgets import QApplication, QWidget, QVBoxLayout, QPushButton, QTextEdit, QProgressBar, QLabel, QLineEdit, QFileDialog, QTabWidget, QFormLayout, QHBoxLayout
from PyQt6.QtCore import QThread, pyqtSignal
class CustomTextDataset(Dataset):
def __init__(self, tokenizer, file_path, block_size):
with open(file_path, 'r', encoding='utf-8') as f:
lines = [line for line in f.read().splitlines() if (len(line) > 0 and not line.isspace())]
self.examples = tokenizer.batch_encode_plus(lines, add_special_tokens=True, max_length=block_size, truncation=True, padding="max_length")["input_ids"]
def __len__(self):
return len(self.examples)
def __getitem__(self, i):
return torch.tensor(self.examples[i], dtype=torch.long)
class TrainingWorker(QThread):
update_progress = pyqtSignal(int)
update_log = pyqtSignal(str)
training_finished = pyqtSignal()
def __init__(self, model_path, dataset_path, device, batch_size, epochs):
super().__init__()
self.model_path = model_path
self.dataset_path = dataset_path
self.device = device
self.batch_size = batch_size
self.epochs = epochs
self.is_running = True
def run(self):
try:
if not os.path.exists(self.model_path):
self.update_log.emit(f"Модель не найдена по указанному пути: {self.model_path}")
self.training_finished.emit()
return
if not os.path.exists(os.path.join(self.model_path, 'tokenizer_config.json')):
self.update_log.emit(f"Токенизатор не найден по указанному пути: {self.model_path}")
self.training_finished.emit()
return
tokenizer = GPT2Tokenizer.from_pretrained(self.model_path)
model = GPT2LMHeadModel.from_pretrained(self.model_path)
model.to(self.device)
dataset = CustomTextDataset(tokenizer, self.dataset_path, block_size=512)
data_loader = DataLoader(dataset, batch_size=self.batch_size, shuffle=True)
optimizer = AdamW(model.parameters(), lr=5e-5)
scheduler = StepLR(optimizer, step_size=1, gamma=0.95)
model.train()
total_steps = len(data_loader) * self.epochs
for epoch in range(self.epochs):
if not self.is_running:
break
for i, batch in enumerate(data_loader):
if not self.is_running:
break
inputs = batch.to(self.device)
labels = batch.to(self.device)
optimizer.zero_grad()
outputs = model(inputs, labels=labels, attention_mask=inputs != tokenizer.pad_token_id)
loss = outputs.loss
loss.backward()
optimizer.step()
current_step = epoch * len(data_loader) + i + 1
self.update_progress.emit(int((current_step / total_steps) * 100))
self.update_log.emit(f"Эпоха {epoch+1}/{self.epochs}, Партия {i+1}/{len(data_loader)}, Потеря: {loss.item()}")
scheduler.step()
self.update_log.emit(f"Эпоха {epoch+1}/{self.epochs} завершена.")
if self.is_running:
model.save_pretrained(self.model_path)
tokenizer.save_pretrained(self.model_path)
self.update_log.emit("Обучение завершено. Модель сохранена.")
self.update_progress.emit(100)
self.training_finished.emit()
except Exception as e:
self.update_log.emit(f"Произошла ошибка: {str(e)}")
self.training_finished.emit()
def stop_training(self):
self.is_running = False
class MainWindow(QWidget):
def __init__(self):
super().__init__()
self.thread = QThread()
self.worker = None
self.initUI()
def initUI(self):
self.setWindowTitle("Обучение GPT")
self.setGeometry(100, 100, 600, 400)
layout = QVBoxLayout()
# Создаем вкладки
self.tabs = QTabWidget()
# Вкладка для обучения модели
self.trainingTab = QWidget()
self.trainingLayout = QVBoxLayout()
self.startButton = QPushButton("Начать обучение")
self.stopButton = QPushButton("Остановить обучение")
self.logText = QTextEdit()
self.logText.setReadOnly(True)
self.progressBar = QProgressBar()
self.epochsLabel = QLabel("Количество эпох:")
self.epochsInput = QLineEdit("1")
self.trainingLayout.addWidget(self.startButton)
self.trainingLayout.addWidget(self.stopButton)
self.trainingLayout.addWidget(self.epochsLabel)
self.trainingLayout.addWidget(self.epochsInput)
self.trainingLayout.addWidget(self.logText)
self.trainingLayout.addWidget(self.progressBar)
self.trainingTab.setLayout(self.trainingLayout)
# Вкладка для настроек обучения
self.settingsTab = QWidget()
self.settingsLayout = QFormLayout()
self.modelPathEdit = QLineEdit()
self.modelPathButton = QPushButton("Выбрать...")
self.datasetPathEdit = QLineEdit()
self.datasetPathButton = QPushButton("Выбрать...")
self.batchSizeEdit = QLineEdit("4")
modelPathLayout = QHBoxLayout()
modelPathLayout.addWidget(self.modelPathEdit)
modelPathLayout.addWidget(self.modelPathButton)
datasetPathLayout = QHBoxLayout()
datasetPathLayout.addWidget(self.datasetPathEdit)
datasetPathLayout.addWidget(self.datasetPathButton)
self.settingsLayout.addRow("Путь к модели:", modelPathLayout)
self.settingsLayout.addRow("Файл датасета:", datasetPathLayout)
self.settingsLayout.addRow("Размер батча:", self.batchSizeEdit)
self.settingsTab.setLayout(self.settingsLayout)
# Добавляем вкладки в основной layout
self.tabs.addTab(self.trainingTab, "Обучение")
self.tabs.addTab(self.settingsTab, "Настройки")
layout.addWidget(self.tabs)
self.setLayout(layout)
# Подключаем события
self.startButton.clicked.connect(self.start_training)
self.stopButton.clicked.connect(self.stop_training)
self.modelPathButton.clicked.connect(self.select_model_path)
self.datasetPathButton.clicked.connect(self.select_dataset_path)
def start_training(self):
self.logText.clear()
self.progressBar.setValue(0)
self.startButton.setEnabled(False)
self.stopButton.setEnabled(True)
model_path = self.modelPathEdit.text()
dataset_path = self.datasetPathEdit.text()
batch_size = int(self.batchSizeEdit.text())
epochs = int(self.epochsInput.text())
# Проверяем наличие указанных путей к модели и датасету
if not os.path.exists(model_path):
self.logText.append(f"Модель не найдена по указанному пути: {model_path}")
self.reset_ui()
return
if not os.path.exists(os.path.join(model_path, 'tokenizer_config.json')):
self.logText.append(f"Токенизатор не найден по указанному пути: {model_path}")
self.reset_ui()
return
if not os.path.exists(dataset_path):
self.logText.append(f"Датасет не найден по указанному пути: {dataset_path}")
self.reset_ui()
return
# Создаем экземпляр класса TrainingWorker для выполнения обучения
self.worker = TrainingWorker(model_path, dataset_path, torch.device("cuda" if torch.cuda.is_available() else "cpu"), batch_size=batch_size, epochs=epochs)
self.worker.update_progress.connect(self.progressBar.setValue)
self.worker.update_log.connect(self.logText.append)
self.worker.training_finished.connect(self.on_training_finished)
# Запускаем поток для выполнения обучения
self.worker.start()
def stop_training(self):
if self.worker:
self.worker.stop_training()
def on_training_finished(self):
self.startButton.setEnabled(True)
self.stopButton.setEnabled(False)
self.worker = None
def reset_ui(self):
self.startButton.setEnabled(True)
self.stopButton.setEnabled(False)
def select_model_path(self):
model_path = QFileDialog.getExistingDirectory(self, "Выберите директорию для загрузки и сохранения модели")
if model_path:
self.modelPathEdit.setText(model_path)
def select_dataset_path(self):
dataset_path, _ = QFileDialog.getOpenFileName(self, "Выберите файл с датасетом для обучения", "", "Текстовые файлы (*.txt)")
if dataset_path:
self.datasetPathEdit.setText(dataset_path)
def main():
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec())
if __name__ == '__main__':
main()