Доброго времени суток, читатели, зрители моего канала programmer's notes. Не забывайте подписываться и писать свои комментарии к моим статьям и видео
Примеры использования команды select (часть 1)
Прошло уже несколько видеоуроков по команде select. И я решил, что вместо того, чтобы к каждому видеоуроку писать приложение, написать обзор возможностей команды select по всему объему последнего видеоматериала. Для начала перечислю ссылки на семь видеоуроков по команде select: урок 1, урок 2, урок 3, урок 4, урок 5, урок 6, урок 7.
Ну, а теперь приступим к примерам, но прежде напомним схему данных, которую мы используем в своих уроках.
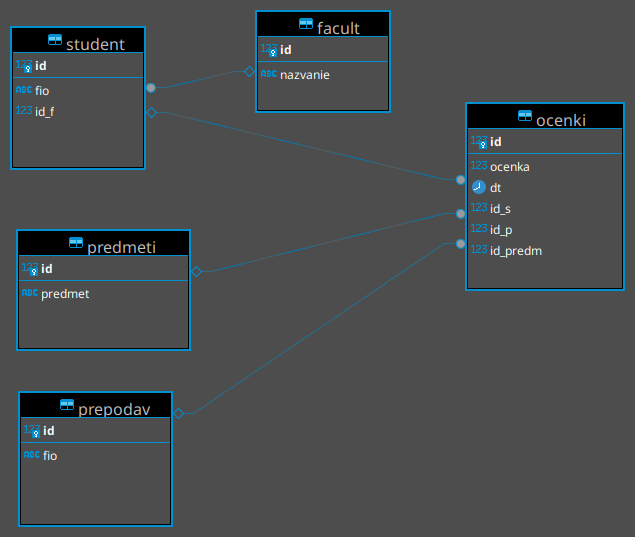
Напомню, что в своём изложении я ориентируюсь на СУБД PostgreSQL, хотя в данной статье ничего такого, что относилось бы только данному серверу данных не будет.
Простые примеры использования select
Команда select может быть использована просто для выполнения какого-либо действия. Например
select ((12.4 * 23.78)/1.5) ^ 3
Результат
7596732.4141460290331726
Или со строками
select 'Съешь '||'эту '||'вкусную '||'булочку!'
Здесь пример конкатенации строковых констант. Напомню, что строки в SQL ограничиваются одинарными кавычками. Двойные кавычки используются для имён объектов. Операция же конкатенации (слияния) строк выражается оператором "||".
Кстати в арсенале SQL есть весьма обширный набор математических функций. Надо, видимо, в будущем представить такой справочник у меня на канале.
Однако select всё таки предназначена для работы с таблицами.
select * from student
Получить полный список строк таблицы (рисунок 1)
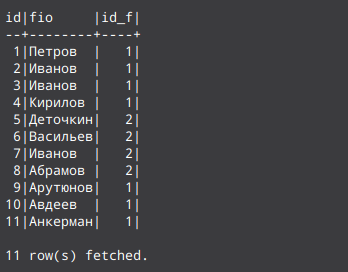
Вообще структуру команды select принято делить на разделы. Раздел select (первый) присутствует всегда. Остальные по мере необходимости. Выше добавился раздел from, где указываются имена таблиц, их псевдонимы и связи между таблицами. В последнем случае в разделе from указана только одна таблица student. Символ "*" в разделе select указывает на то, что должно выводится содержимое всех столбцов. Но можно просто указать, какие столбцы должны быть представлены.
select id, fio from student
Замечание
Отметим некоторое различие в терминах столбец (колонка) и поле. Столбец это элемент таблицы, поле элемент строки таблицы. Почти синонимы, но не синонимы.
Для имён столбцов в разделе select можно указать псевдонимы
select id as "Идентификатор", fio as "Фамилия" from student
Результат (рисунок 2)
Если указан псевдоним, то в дальнейшем вместо имени столбца можно указывать именно псевдоним.
Ещё один раздел команды select.
select id as "Идентификатор", fio as "Фамилия"
from student
order by fio
Раздел order by позволяет сортировать результат по содержимому указанного столбца. Можно сортировать сразу по нескольким полям. В результате набор строк будет разбит на группы по первому элементы, внутри группы будет сортировка по второму и т.д.
select fio as "Фамилия", id as "Идентификатор"
from student
order by fio, id
Результат см. Рисунок 3
Обращу внимание, что все группы состоят из одной строки, кроме группы "Иванов". И это понятно, ведь в таблице три человека с этой фамилией. Внутри группы сортировка по "id".
Еще один элемент, раздела select. Если мы хотим получить список фамилий студентов (а не студентов), то нам из списка нужно удалить дублирующие строки. В нашей таблице есть три однофамильца. Поэтому используем ключевое слово distinct
select distinct fio
from student
order by fio
Строки-дубли будут удалены.
Наконец один из важных разделов команды select - where. Этот раздел предназначен для указаний условия отбора. Условие, в принципе, может быть сколь угодно сложным, так как оно может сконструировано с помощью логических связок or и and, а также с использованием оператора отрицания - not.
select fio
from student
where fio='Иванов' or id > 7
order by fio
Результат выполнения см. на рисунке 4
Группировка в команде select и агрегирующие функции
Перейдём теперь к важному элементу использования команды select - группировке. Да термин этот я уже использовал в отношении раздела order by, но в select есть и специальный раздел. Но в начале об агрегирующих функциях.
Замечание
Термин 'агрегатные функции' кажется мне не точным.
Агрегирующие функции воздействуют не на величину, а на набор строк.
select count(*)
from student
Функция count() как раз является агрегирующей функцией и считает количество строк в наборе. В данном случае результат запроса: количество строк в таблице student. Вместо звёздочки может стоять имя конкретного столбца или даже некоторое выражение. В таком варианте при счёте пропускаются строки, для которых выражение будет равно NULL.
Пять классических агрегирующих функций: count() - количество строк, sum() - сумма по набору строк по конкретной величине; max() - максимальное значение в наборе по конкретной величине, min() - минимальное значение по конкретной величине, avg() - среднее по конкретной величине. Есть, разумеется, другие, причём часто специфические для конкретной СУБД. Я вернусь к агрегирующим функциям СУБД PostgreSQL в свое время.
Но вот при использовании группировки агрегирующие функции просто незаменимы.
Группировка осуществляется использованием раздела group by.
select fio
from student
group by fio
данный запрос по сути эквивалентен
select distinct fio
from student
Что происходит при группировке в представленном выше запросе? Все строки разбиваются по группам, в которых fio строк равны друг другу. А далее возвращается набор из представителей каждой группы.
Что нам даст использование агрегирующих функций? Мы можем получить результат по каждой группе отдельно.
select fio, count(*) as "Количество"
from student
group by fio
Результат выполнения запроса см. на рисунке 5
В правой колонке количество строк в каждой группе. Ну по-сути мы узнали сколько у нас однофамильцев.
Сделаем остановку на нюансах функции count().
1. count(*) — считает количество строк в наборе (всех);
2. count(имя_столбца) — считает количество строк в наборе, в которых в стобце имя_столбца стоит значение отличное от NULL;
3. count(distinct имя_столбца) — считает количество строк в наборе с разным значение в столбце имя_столбца. Строки в которых имя_столбца=NULL также не учитываются.
Многотабличные запросы select
Многотабличные запросы - это запросы к нескольким таблицам сразу. Речь идёт в сущности о связывании таблиц по некоторым признакам. Чаще всего такая связь идёт по линии первичный-внешний ключи. Т.е. по статической связи. Впрочем это не обязательно, см. ниже в разделе.
select s.fio, o.ocenka
from student s inner join ocenki o on s.id=o.id_s
order by s.fio
Результат выполнения запроса: фамилии учащихся и полученные оценки.
Несколько замечаний по запросу.
- В многотабличных запросах используются псевдонимы для таблиц, чтобы знать к какой таблице относится колонка. Мы видим, что у таблицы student псевдоним s, у таблицы ocenki псевдоним o. Псевдонимы можно заменить на имена таблиц, но запрос сразу станет длиннее.
- В разделе from указан способ соединения inner join (см. ниже) и условия связи (после on). В данном случае таблицы соединяются по линии статической связи.
Перечислим типы соединений
- inner join - в результирующий набор попадают только связанные строки по разделу on;
- left join - все строки по inner join, плюс строки из левой таблицы, которые по условию не попадают (студенты без оценок);
- right join - все строки по inner join, плюс строки из правой таблицы, которые по условию не попадают (оценки без студентов);
- full join - строки, удовлетворяющие left join или right join.
- cross join - декартово произведение множества строк левой и правой таблицы, ключевое слово on использовать не нужно.
А вот ещё пример
select distinct f.nazvanie, p.fio
from facult f inner join student s on f.id=s.id_f
inner join ocenki o on s.id=o.id_s
inner join prepodav p on o.id_p=p.id
В результате выполнения запроса получаем список факультетов и фамилии преподавателей, которые там работают (рисунок 6). Надеюсь, понятно, зачем здесь distinct?
Вернёмся теперь к теме группировка.
select s.fio, avg(o.ocenka)
from student s inner join ocenki o on s.id=o.id_s
group by s.id
Результат выполнения см. Рисунок 7
Результатом работы запроса является список студентов и их средних оценок. Тут важно, что группировка идёт не по фамилиям, а по идентификаторам. Ведь у нас есть однофамильцы!!!
Попробуем теперь отобрать студентов по их средним оценкам. Сразу замечу, что раздел where нам не подойдёт. Он срабатывает до того, как строки разбиты на группы. А для нашей задачи подойдёт раздел having, который работает после того, как группы созданы.
select s.fio, avg(o.ocenka)
from student s inner join ocenki o on s.id=o.id_s
group by s.id
having avg(o.ocenka)>=4
Т.е. этим запросом мы отбираем учащихся у которых средняя оценка выше или равна 4.
Ну и наконец, последнее в этом разделе. Использование оператора case в команде select.
select s.fio, case
when avg(o.ocenka) >= 4.5 then 'Отличник'
when avg(o.ocenka) >= 4.0 then 'Хорошист'
when avg(o.ocenka) >= 3.5 then 'Не очень'
when avg(o.ocenka) > 2 then 'Двоечник'
else 'Просто никак'
end as "Характеристика", avg(o.ocenka)
from student s inner join ocenki o on s.id=o.id_s
group by s.id
order by s.fio
Результат выполнения запроса см. на рисунке 8. case позволяет вставлять вместо поля в разделе select некий результат вычисления. Оператор начинается со слова case и заканчивается словом end. А между этими словами произвольное количество when с условием и тем, что нужно в этом случае подставлять вместо поля. Проверка идёт последовательно, поэтому результат вычисляется по методу последовательных исключений: если выполняет первое условие, то идёт соответствующая подстановка и оператор case заканчивает свою работу. Если не выполняется первое условие, то проверяется второе условие. Если оно не выполняется, то проверяется третье условие. И т.д.
Объединение запросов
Связь таблиц по линии раздела from можно назвать объединением таблиц по столбцам. Такое горизонтальное соединение. Но разные запросы можно соединять по строкам или вертикально. Есть три способа соединения:
- union [all] - просто объединение. Все строки из первого набора (строки от первого запроса) со всеми строками из второго набора (строки от второго запроса);
- intersect [all] - строки, которые входят в первый и второй наборы;
- except [all] - строки. которые входят в первый набор, но не входят во второй набор.
Можно объединять произвольное количество наборов. Слово all добавляется в том случае, если мы не хотим, чтобы из результирующего набора удалялись дубли.
Важное правило:
- Количество столбцов в объединяемых наборах должно быть одинаково;
- Соответствующие друг другу поля объединяемых наборов строк должны быть одного типа, либо совместимого типа.
Следующий пример
select s.fio
from student s left join ocenki o on s.id=o.id_s
except all
select s.fio
from student s inner join ocenki o on s.id=o.id_s
Данный запрос даёт нам возможность получить фамилии тех студентов, у которых нет оценок. Мы просто вычитаем из всего списка список студентов у которых есть оценки.
Кстати многие студенты последнюю задачу пытаются решить так
select s.fio
from student s inner join ocenki o on s.id<>o.id_s
но это не правильно, так как для каждой строки таблицы находится множество строк второй таблицы, как раз удовлетворяющих записанному условию.
Важное замечание
Если вы объединяете несколько запросов, то раздел order by можно ставить только в конце последнего запроса. И этот раздел действует на полный результат.
Предположим мы хотим получить список студентов, а в конце списка итог: сколько всего студентов. Задача решается объединением запросов
select fio
from student
group by id
union all
select 'Всего:'||cast(count(*) as text)
from student
Обратим внимание на оператор cast, который отвечает за преобразование типов.
Ранее мы рассматривали простую задачу: получить список фамилий из таблицы student. Приведём три варианта решения этой задачи. Первые два вам знакомы.
-- использование слова distinct
select distinct fio
from student
order by fio
-- использование группировки
select fio
from student
group by fio
order by fio
-- путём объединения запросов
select fio
from student
union
select fio
from student
order by fio
Обратите внимание, что union используется без слова all, это значит, что из результата удаляются дубли. Это нам и нужно было.
Подзапросы в select и других командах
Рассмотрим задачу и два решения к ней. По прежнему используем схему данных из рисунка в начале статьи.
Требуется получить список студентов и факультетов, на которых они учатся.
Первое решение, которое вам, несомненно знакомо
select s.fio, f.nazvanie
from facult f inner join student s on f.id=s.id_f
order by f.nazvanie, s.fio
Результат выполнения
Но тоже самое можно сделать с помощью подзапроса, если использовать его в разделе select
select s.fio, (select f.nazvanie from facult f where s.id_f=f.id) as nazvanie
from student s
order by nazvanie, s.fio
Выражение в скобках будет представлять значение (название) факультета для конкретного студента. Это выражение представляет собой подзапрос, обращённый к другой таблице.
Ещё один пример, когда подзапросы расположены в разделе select
select s.fio,
(select f.nazvanie from facult f where s.id_f=f.id),
(select avg(o.ocenka) from student s2 inner join ocenki o on o.id_s=s2.id
where s.id=s2.id group by s2.id)
from student s
Выводит фамилию студента, название факультета и среднюю оценку студента. Во втором подзапросе есть связь между таблицами. Но подзапрос можно упростить, и просто воспользоваться идентификатором студента из внешнего запроса.
select s.fio,
(select f.nazvanie from facult f where s.id_f=f.id),
(select avg(o.ocenka) from ocenki o where s.id=o.id_s group by s.id)
from student s
Теперь рассмотрим решение также уже знакомой задачи: получить список студентов. у которых нет оценок. Решим её с использованием подзапроса в разделе where.
select s.fio
from student s
where id not in (select id_s from ocenki)
order by s.fio
Тут следует обратить внимание на оператор in. Он возвращает истину, если значение слева входит в набор справа. Т.е. мы просто берём тех учащихся, которые не попадают в набор внешних ключей таблицы ocenki.
Рассмотрим пример, который показывает использование подзапроса select в команде insert.
insert into student (fio, id_f)
(
select 'Перунов А.А.', 1
union
select 'Васькин А.А.', 2
)
Мы добавляем новые строки в таблицу student с помощью команды select. В данном примере значения формируются непосредственно в теле команды select. Но с тем же успехом данные могут браться и из других таблиц. Обращаю только внимание, что должно быть соответствие по полям в команде insert и подзапросе select.
Рассмотрим следующую задачу. Получить список учащихся с количеством оценок у каждого. Следует также учесть тех, у кого оценок нет совсем.
select s.id, s.fio, count(*) as "Количество оценок"
from student s inner join ocenki o on s.id=o.id_s
group by s.id
union all
select s.id, s.fio, 0 as "Количество оценок"
from student s left join ocenki o on s.id=o.id_s
where s.id not in (select id_s from ocenki)
order by "Количество оценок" desc
Наш запрос состоит из двух запросов, объединённых union all. Второй запрос как раз даёт список тех учащихся, у кого нет оценок. Подзапрос используется в разделе where. Обратим внимание, что раздел order by стоит в конце объединения и действует на весь результат.
Следующий запрос интересен двумя вещами. Во-первых, в нём есть подзапрос, в котором есть ещё подзапрос. Во-вторых, при условии с подзапросом используется обычное равенство. Задача заключается в том, чтобы получить список студентов с максимальным количеством оценок.
select s.id, s.fio
from student s inner join ocenki o on s.id=o.id_s
group by s.id
having count(*) =
(
select max(p1."cou")
from
(
select count(*) as "cou"
from ocenki
group by id_s
) p1
)
В самом внутреннем подзапросе мы получаем список количества оценок у каждого студента. Запросом select max(p1."cou") получаем максимальное значение количества оценок у учеников. Подчеркнём, что этот запрос имеет только одну строку. Именно поэтому далее можно использовать having count(*) =, т.е. знак равенства. Как видим подзапросы используются в разделе having.
Перейдём теперь к команде delete. Предположим нам нужно удалить учащихся из таблицы student, у которых нет оценок. Вот два решения
delete from student
where student.id not in (select id_s from ocenki where id_s=student.id)
Т.е. удаляются те строки, первичные ключи которых не попадают в набор внешних ключей id_s таблицы ocenki. Другое решение использует функцию exists(), которая разбирается в следующем разделе статьи.
delete from student
where not exists(select * from ocenki where student.id=id_s)
В сущности, это всё тот же запрос, но использует exists().
Использование операторов any/some, all с подзапросами. Функция exists.
Операторы any/some и all очень удобны в запросах select. Они предназначены для проверки определённых условий. any и some являются синонимами, так что мы в дальнейшем будем использовать только any. C данными операторами можно использовать обычные знаки сравнения: =, <, >, >=, =<, <>.
select distinct s.id, s.fio
from student s inner join ocenki o on s.id=o.id_s
where 2 = any (select ocenka from ocenki where s.id=id_s)
В данном запросе мы ищем тех студентов, у которых есть оценка 2. Т.е. =any даёт истину, если справа есть строки, которые равны выражению слева. При этом как обычно можно всё выражение взять в скобки и использовать оператор not: not(a=any(select ...)).
Следующий запрос можно использовать для проверки того, есть ли студенты у которых все оценки одинаковы
select distinct s.id, s.fio
from student s inner join ocenki o on s.id=o.id_s
where 5 = all (select ocenka from ocenki where s.id=id_s)
В данном случае мы ищём тех студентов, у которых все оценки пятёрки. Т.е. оператор all даёт истину, если для всех строк выполняется данное условие.
Функция exists() проверяет, есть ли в запросе хотя бы одна строка. Если строк нет, то возвращается ЛОЖЬ.
Например
select case
when exists(select * from table) then 'Таблица не пуста'
else 'Таблица пуста'
end
проверка того, есть ли в таблице строки.
А вот серьёзный пример и на exists() и на объединение запросов. Иногда требуется определить состоят ли результаты запросов из одинаковых строк. Запросы могут быть сложные и не всегда лёгко увидеть это путём просмотра, визуально. Подобный же вопрос возникает, когда мы пытаемся сравнить две таблицы на их идентичность. Сравнить можно в частности тем способом, который представлен ниже.
Суть метода заключается в следующем. Если у вас есть два набора табличных строк (набор A и набор B), которые совпадают по структуру, то и (A except B) и (B except A) дадут в результате пустой набор. Ну, а проверить пустой набор или нет можно с помощью exists().
select case
when
not exists
(
(
select distinct s.id
from student s inner join ocenki o on s.id=o.id_s
)
except
(select distinct id_s
from ocenki)
)
and
not exists
(
(
select distinct id_s
from ocenki
)
except
(
select distinct s.id
from student s inner join ocenki o on s.id=o.id_s
)
)
then 'Идентичны'
else 'Не идентичны'
end
Выражение несколько громоздко, в целом очень простое. Две условные конструкции с exists() мы соединяем логической связкой and.
Раздел limit в команде select
В разделе limit указывается максимальное количество выводимы строк. Если строк больше то выводятся первые N строк, где N указано в limit.
Например, следующий запрос выводит последние 3 оценки ученика Авдеева.
select s.id, s.fio, o.ocenka, o.dt
from student s inner join ocenki o on s.id=o.id_s
where s.fio='Авдеев'
order by o.dt desc
limit 3
Отметим, что limit выполняется уже после того, как набор строк отсортирован. В данном случае он отсортирован по убыванию, начиная с последней даты. Таким образом взяв три оценки, мы получим как раз три последних.
Возьмём следующий запрос
select 'Географии' as fc, s.fio, avg(o.ocenka)
from facult f inner join student s on s.id_f=f.id
inner join ocenki o on o.id_s=s.id
where f.nazvanie='Географии'
group by s.id
order by avg desc
limit 3
Он даёт три лучших ученика факультета Географии. Расчёт идет по средним оценкам. Чтобы получить лучших учеников по всем факультетам, а их у нас два, если считать те, где есть студенты, то можно объединить запросы. Но есть важный момент, oder by и limit должны стоять в конце объединения, т.е. воздействовать на результат. Выйти из такой ситуации можно при помощи подзапросов, изящное решение, кстати.
select * from
(
select 'Географии' as fc, s.fio, avg(o.ocenka)
from facult f inner join student s on s.id_f=f.id
inner join ocenki o on o.id_s=s.id
where f.nazvanie='Географии'
group by s.id
order by avg desc
limit 3
) a
union
select * from
(
select 'Физики' as fc, s.fio, avg(o.ocenka)
from facult f inner join student s on s.id_f=f.id
inner join ocenki o on o.id_s=s.id
where f.nazvanie='Физики'
group by s.id
order by avg desc
limit 3
) b
order by fc, avg
Результат выполнения (Рисунок 11)
Пока всё
См. также
Хорошего программирования. Оставляйте свои комментарии, не забывайте про лайки и подписывайтесь на мой канал programmer's notes.