Первоначально замышлял доработать алгоритм LZW вот отсюда:
Но работа с произвольным количеством битов оказалась самостоятельной задачей, которая заслуживает отдельного выпуска.
Итак, обычно мы работаем с данными по 8, 16, 32 и так далее бит. Компьютерная память приспособлена для ведения операций чтения и записи именно такими порциями. Но это же приводит к тому, что если наши данные, допустим, занимают всего 3 бита, то для хранения потребуется минимум 8. А если данные занимают 12 бит, то потребуется 16.
Когда речь идёт о сжатии данных, лишние биты становятся хорошими кандидатами на выход.
Посмотрим, как по умолчанию хранятся два 3-битных числа, красное и синее:
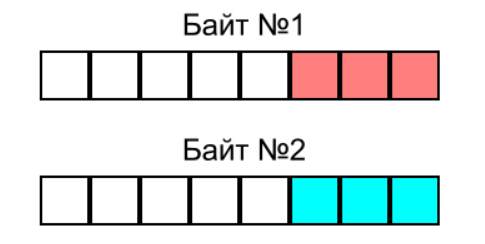
Чтобы выбросить лишние биты, нужно переместить значимые биты из Байта №2 в незанятую часть Байта №1:
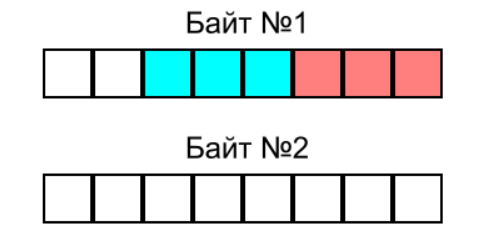
Так мы освободили весь Байт №2, и в Байте №1 остались ещё два незанятых бита. Поместим туда следующее 3-битовое число (зелёное):
Как видим, два зелёных бита поместились в Байт №1, а последний бит перешёл в Байт №2, где осталось ещё 7 свободных бит.
Таким образом, один байт может содержать несколько чисел, но также одно число может содержаться в нескольких байтах.
Теперь посмотрим, как собственно перемещать биты. Реализуем сначала самый примитивный способ. Будем переносить по одному биту.
Берём младший бит из Байта №2. Для для этого делаем операцию "И" с единицей, которая обнулит все биты, кроме младшего:
Теперь надо этот бит сдвинуть в позицию первого свободного бита в Байте №1. Для этого используем буквально операцию сдвига влево на 3 бита:
Теперь, когда бит правильно спозиционирован, надо наложить его на Байт №1, используя операцию "ИЛИ":
Обратим внимание, что операция "ИЛИ", как и любая другая, действует на байт целиком. Но кроме выбранного бита все остальные биты в маске заведомо нулевые, поэтому значение Байта №1 реально может поменяться только в этом выбранном бите.
Мы перенесли младший бит Байта №2 в первый свободный бит Байта №1. Теперь приготовим следующий бит из Байта №2. С помощью сдвига вправо на 1 бит сделаем его младшим:
Бывший младший бит просто выбрасывается из байта, и на его место приходит тот, который стоял слева. После чего мы можем повторить всё сначала, чтобы переместить очередной младший бит в Байт №1.
В коде на языке C это выглядит так:
Полученное значение 34 в двоичной системе выглядит как 100010, и нетрудно увидеть, что 100 это 4, а 010 это 2.
Теперь надо обработать ситуацию, когда часть числа пишется в один байт, а другая часть в другой. Для этого нужно, чтобы результат был не одним байтом, а буфером, состоящим из нескольких байт. И должна быть позиция записи не только в текущий бит, но и в текущий байт, которая будет перемещаться на следующий байт после заполнения текущего.
Теперь оформим код нормально, чтобы им можно было пользоваться. Нужно сделать функцию, которая запишет указанное число в указанный буфер с указанным числом битов. При этом между записями нужно запоминать позицию байта в буфере и позицию бита внутри байта.
Сделаем структуру для хранения состояния битового кодировщика:
Мы не храним в ней указатель на буфер, потому что он будет передаваться извне.
Функция для записи бит в буфер:
Теперь можно выделить буфер и записать в него три числа подряд:
Результат, представленный в виде 32-битного числа, равен 418, и в двоичном виде это 110100010. Можно видеть: 110, 100, 010, это 6, 4 и 2. При этом 6 переходит через границу двух байтов.
Теперь нужно прочитать это всё обратно. Действия в принципе уже понятны, и они противоположны тем, что делались при записи. Вот с каких данных в буфере мы начинаем:
Первый шаг не выглядит сложным. Берём младший бит из байта в буфере и помещаем его в младший бит результата:
Но дальше мы должны взять следующий младший бит, для чего сдвигаем байт вправо:
И полученный младший бит надо теперь сдвинуть влево, чтобы попасть на нужный бит в результате. Этот сдвиг влево будет увеличиваться с каждым следующим битом.
Функция чтения числа из буфера:
Теперь проверим всё вместе:
В результате чтения выдаются числа 2, 4, 6. Можно изменить количество битов на 11, например, и записать другие числа:
Результат: числа записаны и прочитаны правильно.
Оптимизация
Так как битовые операции работают сразу с целыми байтами, то нет нужды устанавливать биты по одному. За один раз можно установить столько битов, сколько доступно.
Рассмотрим сразу непростой случай с размещением числа на границе байтов.
Байт уже частично заполнен, в нём свободно 5 бит, а число занимает 7 бит. Мы можем взять младшие 5 бит числа и поместить их в свободную часть байта:
Для этого нужна операция "И" с маской, состоящей из 5 единиц, чтобы обнулить лишние биты:
Потом надо передвинуть биты на свободные позиции. Это сдвиг влево на 3 бита:
И можно сделать операцию "ИЛИ" с байтом:
Нетрудно заметить, что сдвиг влево делается на количество битов, которые уже заняты в байте, то есть на bit_pos. Другой вопрос, как рассчитать маску, состоящую из нужного количества единиц? Количество свободных битов получаем как 8 - bit_pos. Далее воспользуемся особенностями бинарной арифметики и вычислим степень двойки с этим числом, сдвинув единицу влево на это количество раз:
mask = 1 << (8 - bit_pos);
Результат в двоичном виде будет такой: 1000..., где количество нулей после единицы равно количеству свободных бит. Теперь отнимем от результата единицу и получим 0111..., где количество единиц после 0 будет равно количеству свободных битов. Это и будет искомая маска.
mask = (1 << (8 - bit_pos)) - 1;
Теперь надо разобраться с оставшимися битами числа. Нужно сдвинуть их вправо на уже использованное количество битов, то есть 5.
Байт №1 уже заполнен, поэтому мы переходим на Байт №2 и продолжаем процесс как и раньше. В Байте №2 биты ещё не использованы, то есть bit_pos = 0. Маска для числа будет состоять из 8 единиц: 11111111. Сдвигаться она не будет, то есть по факту число будет просто наложено на текущий байт как есть. Единственное замечание, что текущий байт должен быть перед использованием обнулён, так как операция "ИЛИ" только устанавливает единицы, но не может обнулить их. Результат:
Осталось только скорректировать позицию бита внутри текущего байта, чтобы быть готовыми для записи следующего числа. Так как мы записали 7 бит, начиная с bit_pos = 3, новое значение bit_pos должно стать 3+7=10. Но так как bit_pos не может быть больше 7, мы отнимаем от него 8 (длину целого байта) и в остатке имеем 2. Это соответствует двум заполненным битам в Байте №2.
Оптимизированная функция записи:
Разница в скорости выполнения на добавлении 10 миллионов чисел с длиной 25 бит достигает 4-х раз (0.88 секунды против 0.22 секунды).
Аналогичным образом доработаю функцию чтения:
Ссылка на онлайн-компилятор языка C с кодом программы
Место для оптимизаций ещё есть. Но это, во-первых, потребует усложнять код, и во-вторых, будет заметно только на числах с большой длиной, типа 256 бит и более.
Так что пока хватит.