Современные большие нейросети обучаются на системах с огромным количеством компонентов. А чем больше компонентов, тем выше вероятность отказа. Свежий отчёт Meta* содержит информацию о том, что компания сталкивалась со сбоями ускорителей Nvidia H100 примерно раз в три часа.

Во время обучения модели Llama 3 405B на кластере, содержащем 16 384 ускорителя Nvidia H100 80 ГБ, в течение 54 дней было зафиксировано 419 сбоев, то есть в среднем один сбой каждые три часа. В 58,7% случаев виноваты были либо графические процессоры, либо их память HBM3. В целом сбои в таких сложных системах — это норма, и вопрос скорее в способности специалистов справляться с этими сбоями. В случае Meta* команда сохранила более 90% эффективного времени обучения.
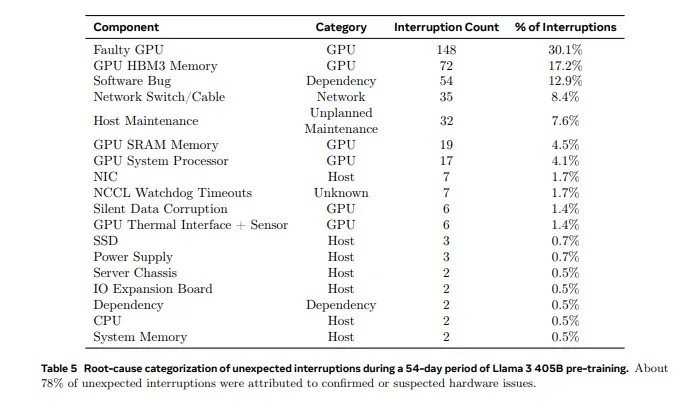
Проблемные GPU были идентифицированы с помощью специализированных инструментов. Эти инструменты приоритизировали проблемные коммуникации, обеспечивая эффективное обнаружение и своевременное разрешение отстающих GPU, что гарантировало минимизацию замедлений, поддерживая общую эффективность обучения.
* Meta признана в России экстремистской организацией, её деятельность запрещена.