
Здравствуйте, уважаемые читатели. Сегодня я продолжу тему элементарных процессов и расскажу более подробно о том, в каком виде они существуют внутри системы CYFERTALK и почему.
В предыдущем посте я выкладывал небольшую гифку, которая демонстрировала, как несколько описательных полей трансформируются в краткое расцвеченное сокращение. Такой способ записи позволяет однозначно определять элементарные процессы и их числовые выражения.
Идея семантической идентификации пришла ко мне, когда мы с коллегами вырабатывали формулу артикула продукции. Наши полиэтиленовые пакеты различались по десяти параметрам:
- Вид, тиснение, завязки, ширина, фалец, толщина, коэффициент давления полиэтилена, процент добавления вторичного сырья, шёв и цвет.
Эти параметры характеризуют именно пакет, а конечным товаром был загруженный европоддон, поэтому к ним добавлялись:
- количество в рулоне, этикетка, количество в коробке, вид коробки и количество коробок на поддоне.
Таким образом, продукт характеризовало уже 15 параметров, которые нужно было как-то фиксировать в документах, чтобы общение между сотрудниками компании, а также клиентами велось на одном языке. Сначала мы записывали параметры в отдельных столбцах, но спустя какое-то время, стало понятно, что необходимо создать более простой способ идентификации товара. После краткого коллективного брэйн-сторма мы приняли решение соединять отдельные параметры в артикул. Такая запись одновременно занимала мало места и точно идентифицировала объект прибыли. Получался примерно такой вид:
- M70(35)/110/18-95(50)-ШЗ-Ч-30-НЭ/10_С_32
И читался он следующим образом:
- Пакет мусорный(М), шириной 70 см (70), зафальцованный на 35 см(35), длиной 110 см(110), толщиной 18 микрон(18), из полиэтилена низкого давления(95), с добавлением 50% вторичного сырья(50), швом звёздочкой(ШЗ), чёрного цвета(Ч), тридцать пакетов в рулоне(30), наша этикетка(НЭ), десять рулонов в коробке(10), средняя коробка(С), 32 коробки на поддоне(32).
Незнакомым с конкретным тех-процессом, такая запись может показаться неудобной, но для сотрудников компании чёткая стандартизация наименований быстро стала привычной и без неё уже не представлялось возможным какое-либо конструктивное обсуждение товаров. Работать с таким артикулом было удобно тем, что два человека могли легко понять, что за продукт представлен в документе. Ушли уточняющие вопросы и ошибки, связанные с неправильной интерпретацией наименований.
Отдельно стоит упомянуть проблему записи для клиентов, которые перепродавали пакеты под видом более толстых/длинных/широких, а значит и более дорогих. Почему так делают и насколько это распространённая практика – тема отдельной статьи, главное, - что наши клиенты(оптовики и торговые дома) требовали писать либо свой артикул, либо наш, но с теми параметрами, которые будут предоставляться уже их клиентам. То, что пакеты записывались по-разному, - создавало для меня дополнительную головную боль. Ведь разные пакеты – это разный вес, а разный вес – это разная цена. И, попробуй, сведи данные, когда по документам производятся одни пакеты, продаются другие, а клиенту приезжают третьи. Именно введение таких описательных артикулов помогло наладить стабильную аналитику.
Постоянно обрабатывая числовые значения, закреплённые за артикулами, я заметил интересную закономерность: контекст, в котором они фигурируют, всегда определяется одними и теми же полями. Так происходит потому что артикул в таблице выражает продукт, с которым осуществляются одни и те же операции: выпуск, упаковка, складирование, отгрузка и т.п. Количество операций невелико и определено тех-процессом, а значит каждая из них вместе с объектом представляет собой элементарный процесс. Для меня стало очевидным, что если составить по принципу кодирования артикула идентификаторы операций, - все числовые потоки улягутся в стройную матрицу на координатной сетке времени.
Стремление свести аналитическую деятельность к координатной плоскости было естественным, даже, наверное, подсознательным желанием. Это логично, - ещё со школьной скамьи мы учились работать с системами координат, они привычны. Поэтому, выражая деятельность предприятия в таком виде, я получал действенный и самое главное – привычный инструмент по анализу числовых данных.
А имея в руках реализующее подобную методу ПО, я мог бы в любой момент сопоставлять товарно-сырьевые потоки, оценивать их, определять потенциальные дефициты/профициты, исключать риски кассовых разрывов и многое другое. Словом, вести полноценную аналитическую деятельность в одном интерфейсе, без необходимости форматирования таблиц. Польза такого интерфейса очевидна, но для его организации необходимо два элемента: шкала времени(ось Y) и шкала процессов(ось X). Если со шкалой времени всё относительно просто, то для создания шкалы процессов необходим механизм идентификации.
У меня уже был артикул, определяющий товар, к нему нужно было добавить идентификатор операции и определить единицу измерения. Я потратил немало времени на разработку концепции кодирования семантических идентификаторов, которая впоследствии легла в основу патента. Без углубления в подробности, скажу что сама концепция довольно проста и понятна на интуитивном уровне. Основной метод работы схож с процессом составления слов из букв и предложений из слов, - навыки, которые, опять же закладываются ещё в начальной школе.
Всё что нужно для определения элементарного процесса – закодировать признаки операции, признаки объекта и единицу измерения, после чего собрать их в читаемый идентификатор. Именно из таких читаемых идентификаторов и будет состоять шкала процессов. Если взять уже упомянутый артикул и закодировать приход определяемого им товара на склад, то идентификатор будет выглядеть следующим образом:
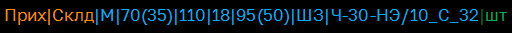
Или для количества в килограммах:
Накладывая такие идентификаторы на шкалу времени, мы получаем динамику закупки/выпуска в зависимости от контекста. Меняя признаки в идентификаторе, мы определяем операции, объекты и единицы измерения. Я назвал закодированные признаки Буквами, а получающиеся из них идентификаторы – Словами, потому что вся механика идентификации CYFERTALK похожа на создание языка, описывающего бизнес. Помимо того, что такие Слова-идентификаторы позволяют создать сопоставительную координатную плоскость, они идеально подходят для поиска, группировки и фильтрации нужных процессов.
Ещё одно примечательное свойство такого подхода – деятельность предприятия можно рассматривать совокупно, без разделения на отделы. Нужно тебе скорректировать план поступлений, – выбираешь поток плана продаж и видишь даты отгрузок, добавляешь план оплат и видишь временные лаги наглядно. Добавляешь потоки закупки и сработки сырья, - и корректируешь соответственно. Можно прикидывать, не отрываясь от переговоров с поставщиками/клиентами – когда лучше запланировать очередную поставку/оплату. В общем и целом, семантическая идентификация - довольно необычный но при этом полезный метод идентификации, открывающий широкие возможности для аналитика.
На этой оптимистичной ноте закончу сегодняшний пост. Постараюсь и дальше рассказывать о CYFERTALK в том же ключе.
Подписывайтесь. С вами был A.V.M.