3 рабочих примера, из-за которых я переступил порог, и 1, из-за которого меня чуть не вышвырнули.

Анализ проектов моего портфолио в области науки о данных
Как и у многих выпускников, у меня не было подходящей работы после получения степени магистра наук о данных; причина в том, что я никуда не подавал заявление.
В течение трех месяцев.
Я закончил университет весной, но всерьез искать работу начал только летом.
То ли страх, то ли предвидение заставили меня поверить, что я не готов, и эта эмоция побудила меня потратить часы, которые я не работал на почасовой основе в местном отеле, на создание востребованного портфолио в области науки о данных.
Когда я получаю комментарии и сообщения LinkedIn с вопросами, связанными с внедрением в индустрию обработки данных,, мой первый совет - всегда создавать портфолио на GitHub, которое вы можете использовать как профессиональную визитную карточку.
Бонусные баллы, если вы создаете интересную документацию или делитесь этим контентом на платформе, такой как Medium или LinkedIn, для общения с потенциальными менеджерами по найму.
Хотя я писал о важности наличия стороннего проекта, даже будучи работающим профессионалом, и делился своими советами по коммуникации для представления проектов в области обработки данных , я понял, что никогда не делился содержанием своего собственного портфолио.
Я надеюсь, что для тех из вас, кто задается вопросом, с чего начать, когда дело дойдет до показа ваших работ, вы увидите реальные примеры того, какие проекты привлекают внимание рекрутера или интервьюера и почему.
Прежде чем я поделюсь своей работой и процессом, я должен признать, что, хотя у меня не было формального технического образования, у меня были следующие качества, которые рекрутеры и менеджеры сочли желательными (на основе отзывов, а не моего эгоизма, клянусь):
- Степень магистра в области науки о данных
- Знание предметной области (я намеренно подавал заявки на должности в сфере СМИ, образования и гостиничного бизнеса, во всех из которых я работал раньше)
- Опыт разработки на Python / SQL / BI (курсовая работа, личные проекты)
- Коммуникативные навыки (огромный плюс даже для младших инженеров или разработчиков)
Примечание: Излишне говорить, что ваши результаты могут отличаться.
Проект 1: Панель управления анализом данных курса Udemy
Обновить: С момента первоначальной публикации я создал пошаговое руководство по этому проекту, чтобы вы могли понять не только код, но и процесс, лежащий в основе его концепции и выполнения.
Создание информационной панели, благодаря которой мне предложили работу аналитика данных
Пошаговое руководство по информационной панели Udemy, благодаря которому мне поступило предложение о работе от одного из крупнейших имен в академических издательствах.
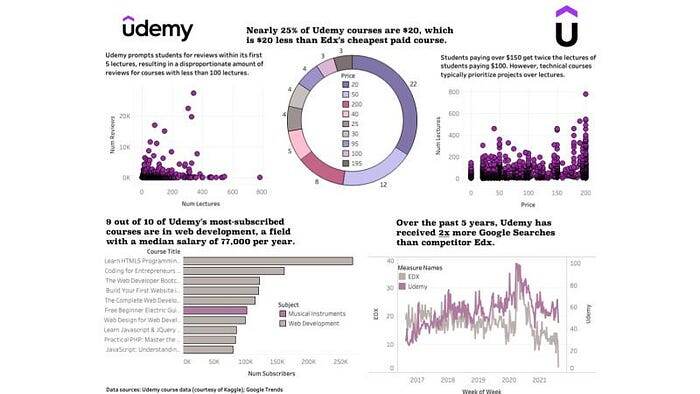
Краткое описание: Статическая панель мониторинга, которая объединяет данные поиска Google и набор данных из Kaggle для получения информации о посещаемости курсов и спросе на контент на платформе размещения курсов Udemy.
Используемые технологии:
- SQL
- Таблица
- Python
Наборы данных:
- Набор данных Udemy от Kaggle
- Данные Google Trends
Делимся ключевыми идеями:
- Почти четверть курсов Udemy стоят менее 20 долларов, что на 20 долларов меньше средней цены Edx-конкурента
- За последние 5 лет Udemy получил почти в 2 раза больше поискового трафика, чем Edx
- 9 из 10 курсов Udemy, на которые чаще всего подписываются, посвящены веб-разработке
Почему этот проект работает:
- Релевантность предметной области (я подавал заявление в образовательную компанию)
- Продемонстрированные лучшие практики визуализации данных
- Продемонстрировал способность проводить конкурентный анализ
Проект 2: K-Word
Резюме: После нескольких лет заголовков с участием различных "Карен’ я решил исследовать тенденции, связанные с популярностью имени "Карен" за последние 100 лет, и создать визуализации, которые превратятся в историю, основанную на данных.
Слово на букву “К": расцвет и падение имени "Карен” с 1920 по настоящее время
Ранее этим летом Администрация социального обеспечения сообщила, что имя “Карен” ассоциируется в прессе с негативом…
Используемые технологии:
- Python
- BigQuery (база данных)
- BigQuery (SQL)
Наборы данных:
- Данные об имени ребенка в системе социального обеспечения (BigQuery)
- Google Trends
Делимся ключевыми идеями:
- Карен достигла своего пика в 1957 году, когда родилось в среднем 725 Каренов
- У Карен положительная корреляция с запросами "расист", "противный" и "менеджер" и отрицательная корреляция с запросами "доброта"
- Испания, Ирак и Иран - страны за пределами США, в которых больше всего искали оскорбление ‘Карен’
Почему этот проект работает:
- Новинка
- Поток повествования
- Использование нескольких источников данных
- Четкая визуализация
Извините, что прерываю: для получения дополнительных инструкций по Python, SQL и облачным вычислениям следуйте за Pipeline: вашим ресурсом по разработке данных.
Чтобы получать мои последние статьи, вы также можете подписаться на меня.
Проект 3: прогнозирование оттока при массовом зачислении на открытые онлайн-курсы
Резюме: Используя многомерную логистическую регрессию, я создал 4 модели для определения вероятности оттока студентов MOOC, группы, известной своим хорошо документированным отсутствием приверженности образовательным продуктам.
Используемые технологии:
- Python
- GitHub
Наборы данных:
- Edx data (Kaggle)
Делимся ключевыми идеями:
- Несмотря на точность в 90%, точность модели была значительно ниже (максимум 60%)
- Включены наилучшие показатели вероятности оттока: процент пройденных курсов, процент пройденных аудитов курсов и наличие у человека степени бакалавра.
- Сокращение функций позволило создать более точную модель с показателями точности, колеблющимися в пределах 95%
Почему этот проект работает:
- Решает распространенную бизнес-проблему: отток
- Демонстрирует мастерство в построении моделей ML
- Демонстрирует способность интерпретировать и представлять результаты моделирования
И проект, из-за которого у меня возникли проблемы…
Трагическое порно
Резюме: В 2018 году 5 звезд фильмов для взрослых умерли в течение 3 месяцев. Хотя о большинстве смертей сообщалось заниженно, самоубийство 23-летней порнозвезды Август Эймс привлекло новое внимание к индустрии, в которой наблюдается всплеск числа исполнителей, умирающих в возрасте до 30 лет из-за самоубийств, передозировок и насилия.
Трагическое порно
В 2018 году в течение 3 месяцев умерли 5 звезд фильмов для взрослых. Хотя информация о большинстве смертей была занижена, самоубийство порнозвезды…
Используемые технологии:
- Python
- SQL (SQL Lite)
- Таблица
Наборы данных:
- Пользовательский набор данных, созданный путем объединения данных, взятых из Википедии, с данными Kaggle
Делимся ключевыми идеями:
- В 2018 году 5 популярных актрис для взрослых умерли с разницей в 3 месяца друг от друга
- За последние 5 лет 10 исполнителей умерли в возрасте до 26 лет
- в 2018 году умерло 12 исполнителей, что является 25-летним максимумом
Почему этот проект работает:
- Продемонстрировал способность создавать пользовательские агрегированные наборы данных (чрезвычайно важный навык для любой работы с данными)
- Рекомендуемые данные, взятые из Интернета (очень востребованный навык)
- Продемонстрированные знания о лучших практиках визуализации
- Рассказывает четкую, легкую для понимания историю данных, которая привлекает аудиторию
Почему у меня из-за этого возникли проблемы
(К настоящему моменту вы, вероятно, уже догадываетесь)
Я представил этот проект во время группового интервью со старшими аналитиками данных.
В тот момент они были вовлечены и задавали вопросы о том, как я собирал, манипулировал и отображал свои данные.
Судя по всему, собеседование прошло хорошо.
Затем позвонил рекрутер.
Хотя она была рада сообщить мне, что я перехожу к следующему раунду собеседования, она предположила, что я, возможно, не буду представлять руководителям компании информационную панель под названием "Трагическое порно" в заключительном раунде собеседования.
Она поделилась, что мои интервьюеры предположили, что, хотя анализ был основательным, содержание было немного противоречивым (если не сказать больше).
Я родом из мира журналистики и медиа, где обсуждается очень мало тем, так что для меня это был полезный опыт.
В конце концов, я получил предложение от компании, а затем отклонил его.
В целом это был прекрасный опыт с ценным уроком для любого кандидата: знайте свою аудиторию и соответствующим образом ориентируйтесь на свой контент.
Краткое описание
Портфолио в области науки о данных нельзя воспринимать легкомысленно.
Рекрутеры, интервьюеры и ваши будущие начальники могут безошибочно отличить разрозненное репозиторий кода от настоящего, отточенного портфолио.
Хотя вашей целью не должно быть повторение работы, которой я поделился здесь, безусловно, есть уроки, которые следует извлечь:
- Убедитесь, что выбранные вами проекты сосредоточены на анализе или попытках решения реальных бизнес-задач (бонусные баллы, если они включают проблемы, с которыми сталкивается ваша целевая организация).
- Скорее всего, вы будете работать над этими проектами много неоплачиваемых часов. Выбирайте темы и данные, которые вас интересуют.
- Интерпретация и представление результатов - недооцененный, но очень ценный навык. Научитесь уверенно представлять последующие вопросы и отвечать на них.
- Сделайте домашнее задание и попробуйте использовать технологию, которая отражает то, что использует ваша целевая организация. Во многих должностных инструкциях, с которыми я сталкивался, были высокие требования к Python и SQL, отсюда и акцент.
- Знайте свою аудиторию и выбирайте темы соответствующим образом.
Надеюсь, если вы стремитесь попасть в эту область, вы увлечены данными (или, по крайней мере, заинтересованы в такой степени, что можете выполнять работу, не слишком скучая).
Помимо того, что вы делитесь своим портфолио, не бойтесь рассказывать интервьюерам историю вашего процесса.
Менеджерам нужны кандидаты, увлеченные данными и решающие бизнес-задачи. Покажите им доказательства того, что эти описания применимы к вам.