
Несмотря на эффективность обхода дерева, существуют случаи, когда поиск по индексу работает не так быстро, как ожидалось. Это противоречие долгое время подпитывало миф о дегенерированном индексе. Миф утверждает, что перестроение индекса является чудодейственным решением. Стоит принять как данность, что перестроение индекса не улучшает производительность в долгосрочной перспективе. Истинная причина медленной работы простых запросов — даже при использовании индекса — может быть объяснена простыми вещами.
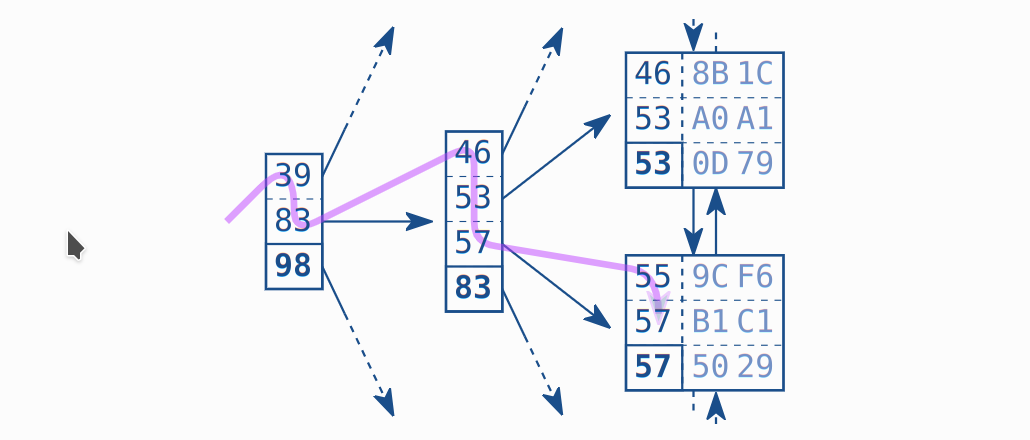
Первым фактором медленного поиска по индексу является цепочка листовых узлов. Рассмотрим снова поиск значения "57" на рисунке выше. Очевидно, что в индексе есть две совпадающие записи. По крайней мере две записи одинаковы, если быть точнее: следующий листовой узел может содержать еще записи для "57". База данных должна прочитать следующий листовой узел, чтобы проверить, есть ли еще совпадающие записи. Это означает, что поиск по индексу требует не только обхода дерева, но и следования по цепочке листовых узлов.
Вторым фактором медленного поиска по индексу является доступ к таблице. Даже один листовой узел может содержать множество совпадений — часто сотни. Соответствующие данные таблицы обычно разбросаны по многим блокам таблицы. Это означает, что для каждого совпадения требуется дополнительный доступ к таблице.
Поиск по индексу требует три шага: (1) обход дерева; (2) следование по цепочке листовых узлов; (3) получение данных таблицы. Обход дерева — единственный шаг, для которого существует верхняя граница по количеству доступных блоков — глубина индекса. Другие два шага могут требовать доступа к множеству блоков, что вызывает медленный поиск по индексу.
Происхождение мифа о "медленных индексах" связано с неверным представлением, что поиск по индексу заключается только в обходе дерева, отсюда и идея, что медленный индекс должен быть вызван "сломленным" или "несбалансированным" деревом. На самом деле, большинство баз данных позволяют узнать, как они используют индекс. База данных Oracle достаточно многословна в этом отношении и имеет три различных операции, описывающих базовый поиск по индексу:
INDEX UNIQUE SCAN
INDEX UNIQUE SCAN выполняет только обход дерева. База данных Oracle использует эту операцию, если уникальное ограничение гарантирует, что критерии поиска соответствуют не более чем одной записи.
INDEX RANGE SCAN
INDEX RANGE SCAN выполняет обход дерева и следует по цепочке листовых узлов, чтобы найти все совпадающие записи. Это операция по умолчанию, если по критериям поиска может совпадать несколько записей.
TABLE ACCESS BY INDEX ROWID
Операция TABLE ACCESS BY INDEX ROWID извлекает строку из таблицы. Эта операция (часто) выполняется для каждой совпадающей записи из предшествующей операции поиска по индексу.
Важно отметить, что INDEX RANGE SCAN потенциально может прочитать большую часть индекса. Если для каждой строки требуется дополнительный доступ к таблице, запрос может стать медленным даже при использовании индекса.