
Узлы индекса хранятся в произвольном порядке — их расположение на диске не соответствует логическому порядку согласно порядку индекса. Это похоже на телефонный справочник с перемешанными страницами. Если вы ищете "Иванов", но сначала открываете справочник на "Иаков", это вовсе не означает, что за Иаковым следует Иванов. Базе данных нужна вторая структура, чтобы быстро найти запись среди перемешанных страниц: сбалансированное поисковое дерево — кратко: B-tree.
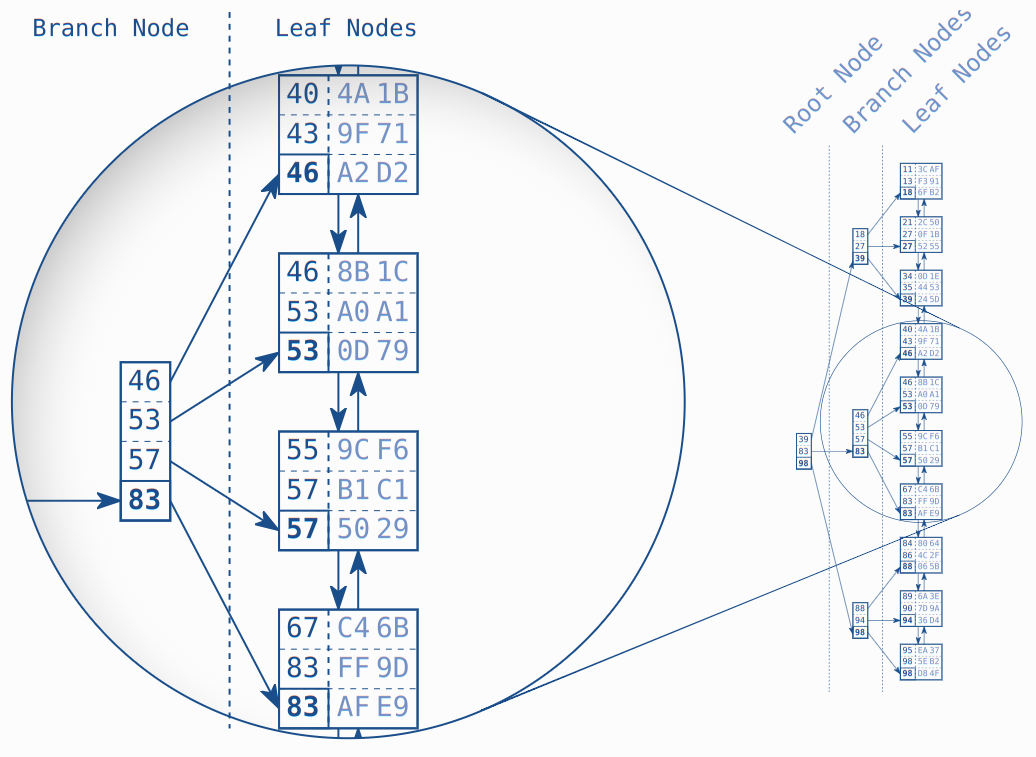
Здесь пример индекс с 30 записями. Двусвязный список устанавливает логический порядок между узлами. Корневые и дочерние узлы обеспечивают быстрый поиск среди листовых узлов.
На рисунке выделен корневой узел и дочерние узлы, к которым он относится. Каждая запись корневого узла соответствует наибольшему значению в соответствующем дочернем узле. Возьмем первый узел в качестве примера: наибольшее значение в этом узле — 46, которое, таким образом, хранится в соответствующей записи корневого узла. То же самое относится и к другим узлам, так что в итоге корневой узел содержит значения 46, 53, 57 и 83. Согласно этой схеме, формируется уровень ветвей до тех пор, пока все листовые узлы не будут охвачены корневым узлом.
Следующий уровень строится аналогичным образом, но поверх первого уровня корневого узла. Процедура повторяется до тех пор, пока все ключи не уместятся в одном узле, который становится корневым узлом. Эта структура представляет собой сбалансированное поисковое дерево, так как глубина дерева одинакова в каждой позиции; расстояние между корневым узлом и листовыми узлами везде одинаково.
B-tree — это сбалансированное дерево, а не двоичное дерево.
После создания базы данных индекс поддерживается автоматически. Каждая вставка, удаление и обновление применяется к индексу, и дерево остается сбалансированным, что вызывает накладные расходы на обслуживание для операций записи.
Здесь показан фрагмент индекса для иллюстрации поиска ключа "57". Обход дерева начинается с корневого узла на левой стороне. Каждая запись обрабатывается в порядке возрастания до тех пор, пока значение не станет больше или равно (>=) искомому значению (57). На рисунке это запись 83. База данных следует ссылке на соответствующий корневой узел и повторяет процедуру до тех пор, пока обход дерева не достигнет конечного узла.
Обход дерева является очень эффективной операцией — настолько эффективной, что я называю её основной силой индексации. Она работает практически мгновенно, даже на огромных наборах данных. Это главным образом благодаря сбалансированности дерева, которая позволяет получать доступ ко всем элементам с одинаковым количеством шагов, и, во-вторых, благодаря логарифмическому росту глубины дерева. Это означает, что глубина дерева растет очень медленно по сравнению с количеством узлов. Индексы реального мира с миллионами записей имеют глубину дерева четыре или пять. Глубина дерева шесть встречается крайне редко
B-дерево позволяет базе данных быстро находить листовой узел.
Логарифмическая сложность
В математике логарифм числа по данному основанию — это степень или показатель, в которую нужно возвести основание, чтобы получить это число.
В дереве основание соответствует количеству записей на ветвь узла, а показатель — глубине дерева. Пример индекса на рисунке ниже содержит до четырёх записей на узел и имеет глубину дерева три. Это означает, что индекс может содержать до 64 (4³) записей. Если он увеличится на один уровень, то сможет уже содержать 256 записей (4⁴). Каждый раз, когда добавляется уровень, максимальное количество записей индекса увеличивается в четыре раза. Логарифм обращает эту функцию. Таким образом, глубина дерева равна log₄(количество-записей-индекса).
Основной фактор, влияющий на глубину дерева и, следовательно, на производительность поиска, — это количество записей в каждом узле дерева. Это число соответствует — с математической точки зрения — основанию логарифма. Чем больше основание, тем мельче дерево и тем быстрее его обход.
Базы данных максимально используют эту концепцию и помещают как можно больше записей в каждый узел — часто сотни. Это означает, что каждый новый уровень индекса поддерживает в сто раз больше записей.