
Основная цель индекса — обеспечить упорядоченное представление индексированных данных. Однако хранить данные последовательно невозможно, потому что оператор вставки должен перемещать последующие записи, чтобы освободить место для новой. Перемещение большого объема данных занимает много времени, поэтому оператор вставки будет очень медленным. Решение этой проблемы заключается в установлении логического порядка, который не зависит от физического порядка в памяти.
Логический порядок устанавливается с помощью двусвязного списка. Каждый узел имеет ссылки на два соседних элемента, подобно цепочке. Новые узлы вставляются между двумя существующими узлами путем обновления их ссылок для указания на новый узел. Физическое расположение нового узла не имеет значения, так как двусвязный список поддерживает логический порядок.
Эта структура данных называется двусвязным списком, потому что каждый узел ссылается на предыдущий и следующий узел. Это позволяет базе данных читать индекс вперед или назад по мере необходимости. Таким образом, возможно вставлять новые записи без перемещения большого объема данных — требуется лишь изменить несколько указателей.
Двусвязные списки также используются для коллекций (контейнеров) во многих языках программирования.
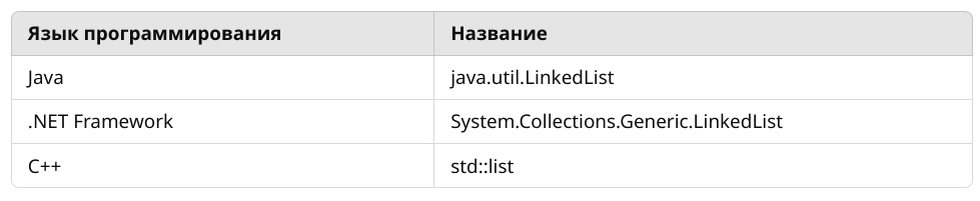
Диаграмма иллюстрирует узлы индекса и их связь с данными таблицы. Каждая запись индекса состоит из индексированных столбцов (ключ, column 2) и ссылается на соответствующую строку таблицы (через ROWID или RID). В отличие от индекса, данные таблицы хранятся в структуре кучи и вовсе не отсортированы. Нет ни взаимосвязи между строками, хранящимися в одном блоке таблицы, ни связи между блоками.