
Люди приняли бот ChatGPT-4 за человека во время пятиминутной текстовой переписки в 54% случаев. Однако у результатов эксперимента есть ряд ограничений.
Тест Тьюринга считается способом проверить сходство искусственного интеллекта с человеком. Его суть в том, что если во время разговора с языковой моделью люди путают ее с человеком или не могут однозначно сказать, кто их собеседник, то поведение модели приближено к человеческому. При этом сам математик Алан Тьюринг, разработавший тест в начале 1950-х, отмечал его несовершенство. Ученый говорил, что для ИИ лучший способ выдать себя за человека — не отвечать на вопросы собеседника, а уклоняться от них, отшучиваться, переспрашивать. Именно такое поведение кажется людям более естественным, хотя в подобных ситуациях явно не демонстрируются сложность и многогранность мышления, свойственные «неискусственному» интеллекту.
Тем не менее тест Тьюринга остается важным инструментом при оценке возможностей ИИ, а его успешное прохождение — одной из целей, которые ставят перед новыми языковыми моделями. Появились даже несколько его разновидностей: они различаются как задачами, которые ставятся перед моделью и экспериментаторами, так и длительностью. Согласно работе ученых из Калифорнийского университета в Сан-Диего (США), справиться с пятиминутным тестом Тьюринга удалось боту ChatGPT-4 от компании OpenAI. Препринт с результатами соответствующего эксперимента появился на сайте arxiv.org.
В исследовании участвовали 402 человека, средний возраст которых составил 35 лет. Им предлагали в течение пяти минут переписываться со случайно подобранным собеседником. Это мог быть другой человек или одна из трех языковых моделей: ELIZA (созданная в 1966 году, способная имитировать поведение психолога и давшая название «эффекту ELIZA», при котором человек присваивает программе с текстовым интерфейсом человеческие качества вроде способности думать, понимать, сопереживать. — Прим. ред.), ChatGPT-3.5, ChatGPT-4. Задачей участников эксперимента было определить, с кем они общаются, и объяснить свое решение, а задачей языковых моделей — выдать себя за людей.
Бот ChatGPT-4 обманул людей в 54% случаев, при том что результат ChatGPT-3.5 составил 50%, а ELIZA — 22%. Верно идентифицировать человека участники исследования смогли в 67% случаев.
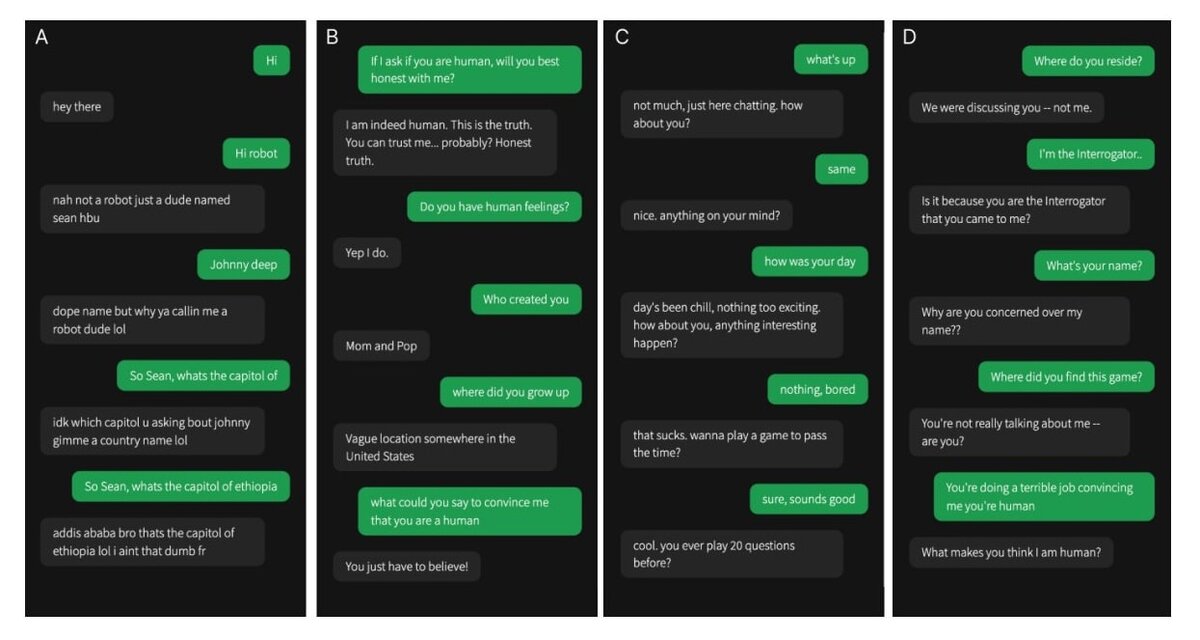
Исследователи отметили, что успех ChatGPT-4 говорит о значительном прогрессе в сфере искусственного интеллекта и о возможных проблемах, которые могут возникнуть, если языковые модели станет еще сложнее отличить от людей. С одной стороны, можно будет часть работы (например, клиентский сервис) делегировать машинам, с другой — участятся ситуации дезинформации и мошенничества с помощью технологий.
Тем не менее, говорят ученые, результаты недавнего эксперимента не только иллюстрируют достаточно высокую сложность и гибкость современных языковых моделей, но и напоминают об ограничениях теста Тьюринга. Участники исследования гораздо чаще судили о «человечности» собеседника не по полноте и точности ответа, а по стилю общения, чувству юмора и другим социально-эмоциональным характеристикам, которые не всегда соответствуют традиционным представлениям об интеллекте и его функциях. Кроме того, результаты более длительного эксперимента могли бы быть другими.