Вообще, изначально я хотел написать свой вирус, а потом подумал, что чревато это. Статьи 272 и 273 УК РФ никто не отменял, поэтому пойдём другим путём - рассмотрим, как вирус работает и проделаем то же самое, только вручную. В ознакомительных, так сказать, целях. Разумеется, под Linux: развеем миф о том, что в этой ОС не существует вирусов. И кто только такие слухи распускает?

Что такое компьютерный вирус
Если оставить за скобками, что это программа, которая наносит какой-то вред, то остаётся только саморазмножающееся приложение: запущенный вирус находит исполняемый файл и внедряется в него, после чего, в случае запуска, инфицированный файл, также, пытается инфицировать другие файлы.
Исходные данные
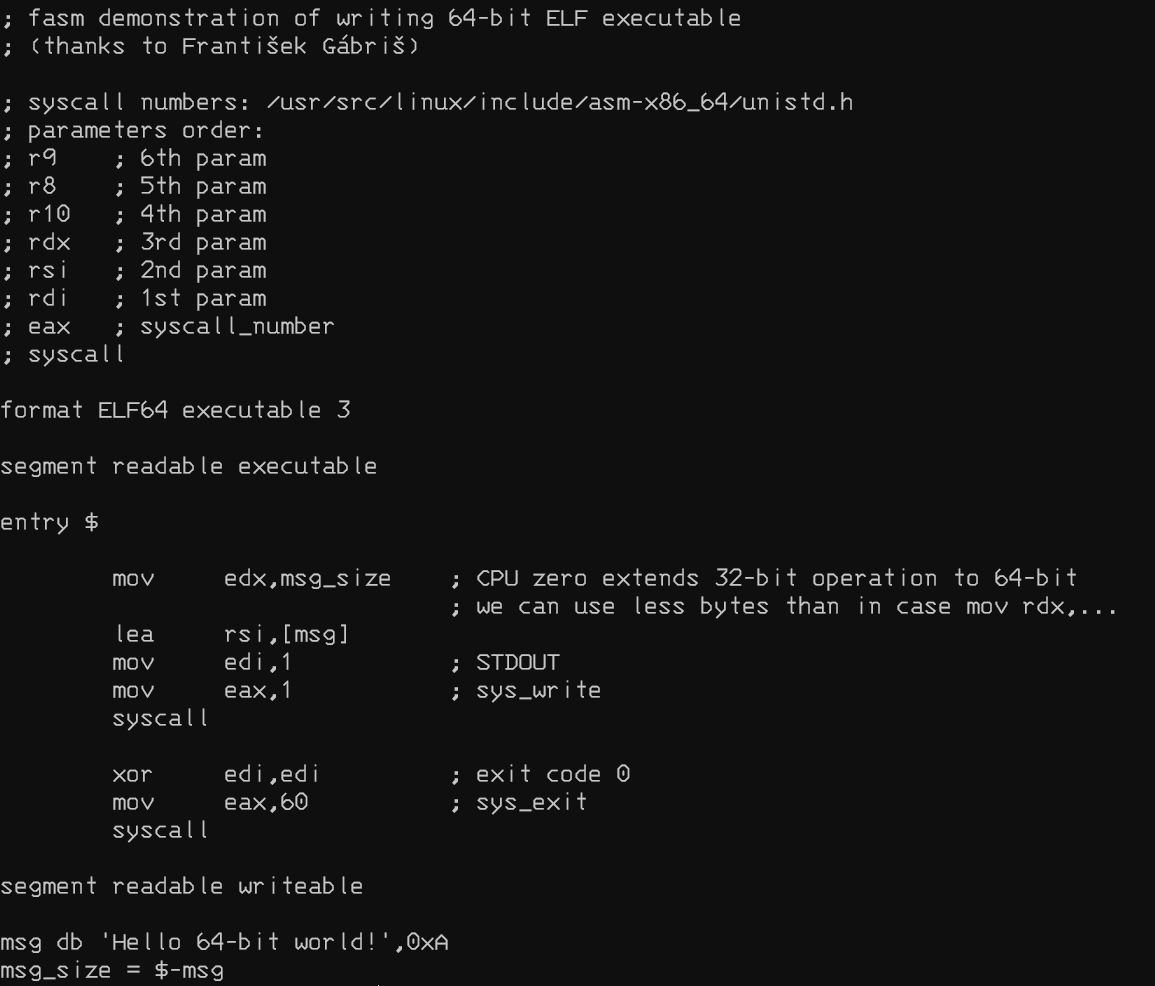
Для оттачивания навыков хакерствования, я создам два файла: первый напишу на FASM (это ассемблер такой), второй - на C++. Каждый файл делает всего одну вещь: выводит текстовую строку типа "привет, мир". И вот это-то поведение мы менять и будем. И весь фокус заключается в том, что изменение текстовой строки и внедрение зловредного кода в исполняемый файл, с точки зрения работы приложения - одно и то же. Поэтому мы будем, конечно, менять текст.
Немного подробностей
Вообще, поменять внутри исполняемого файла текст совершенно не сложно; главное, чтобы он был той же длины. В нашем случае, есть разные способы вывода текста на экран, например, функция printf (чем мы воспользуемся в случае С++). А можно использовать системный вызов операционной системы, отправляющий сообщение на стандартный вывод (а это решение для FASM).
Я уже собрал из исходников 2 исполняемых файла, которые выводят некоторую текстовую строку.
Что ещё надо знать
Любой высокоуровневый код (при условии, что он не будет обрабатываться интерпретатором) компилируется в машинные коды, которые, затем, можно дизассемблировать, то есть превратить в ассемблерный код.
А вот ассемблерный код, как раз, показывает то, как всё будет работать.
Если коротко, то любая ассемблерная программа - это просто набор инструкций процессору (что делать) и данных, идущих одним блоком, но связанных метками переходов при помощи адресов.
Можно проиллюстрировать это как-то так:
- [адрес ААА] сделать что-то
- [адрес ААА + 2] сделать ещё что-нибудь
- [адрес ААА + 4] перейти на адрес XXX
- [адрес ААА + 8] какие-то данные
- [адрес ХХХ] сделать что-то ещё с данными, начинающимися по адресу ААА+8
Но это упрощённо конечно. Обычно, в программах всё организовано более гармонично и структурировано. Если, например, открыть утилитой objdump -h, то можно увидеть заголовки столь простой программы:
А попытка поглядеть заголовки файла, созданного из ассемблерного кода - ни к чему не приведёт: там вообще нет никаких заголовков секций, потому что они не являются чем-то обязательным для работы приложения.
Всё то, что начинается с точки (например .rodata) - это название секций. Каждая секция содержит нечто своё, нужное и важное, однако весь этот вывод возможен только потому, что в конце файла есть нечто вроде оглавления, содержащее описание того, что внутри файла. Но оно необязательно и его можно и не добавлять. Однако компилятор gcc (а именно им я собирал приложение) это делает и мы, в результате, можем посмотреть, что внутри.
Про секции
Хотя секции и выглядят чем-то отдельным и автономным, на самом деле это просто набор байт, который даже никак не разделяется. Благодаря "оглавлению", мы можем найти ту или иную секцию в уже скомпилированном файле, однако, если оглавление убрать, понять где какая секция - практически невозможно.
У каждой секции есть своя цель: например секция . rodata, которую я уже упоминал, отвечает за хранение данных только для чтения. А вот .bss содержит переменные (то есть для переменных изначально зарезервировано место). Ну и так далее, разбирать это особого смысла нет.
Зато в секции .text находится исходный код приложения.
В заголовке исполняемого файла (в нашем случае это формат ELF) есть адрес в памяти, с которого начинает работать программа. То есть программа загружается в память, выполняются какие-то действия подготовки её к работе (это для случая С++, FASM такой ерундой не занимается), а потом происходит переход к адресу начала работы приложения. И хотя адрес начала работы приложения всегда указывается явно, это вовсе не значит, что к нему сразу и перейдёт управление; однако, именно с него и начнётся программа.
Я не случайно подробно останавливаюсь на этом: с точки зрения человека, привыкшего работать на языках высокого уровня с набором логики и правил, всё происходящее может показаться каким-то бредом, лишённым логики. Однако логика, как раз, заключается в том, что есть просто набор команд с аргументами и данные, которые выполняются последовательно.
Но в случае с С++, добавляются ещё разные плюшки, так сказать, плавного входа и плавного выхода. С FASM всё жёстче: не добавил системный вызов завершения работы приложения - получил ошибку сегментации и аварийный выход из программы (а ведь мог исполниться какой-нибудь код, который остался в памяти с прошлого запуска какого-то приложения).
В чём проблема
Теперь, когда вы уже, надеюсь, поняли, что секции - это хорошо, организованно, но нам совершенно не поможет, можно переходить к проблеме замены строки.
Начнём с С++. Итак, у нас есть строка. У строки есть определённая длина, которая была записана в секцию .rodata, а секция эта находится хоть и ниже секции .text, но явно выше ещё полутра десятков секций, внутри которых может быть исполняемый код.
Это значит, что если мы увеличим (или уменьшим) строку хотя бы на 1 символ - всё сместится и адреса, которые жёстко установлены, станут неактуальными и при выполнении программы, попытка перейти на некий адрес, чтобы выполнить набор команд, гарантированно приведёт к ошибке segmentation fault. Можете поверить мне на слово, пока я готовил эту статью, проверил это много раз.
Но что намного хуже, это не приведёт нас к желаемому результату.
Таким образом, нам надо сделать следующее: как-то обмануть систему таким образом, чтобы и строку вставить нужной нам длины, и работоспособность программы не повредить.
Особенности решения
На самом деле, не существует универсального решения для этой задачи для приложения, собранного при помощи FASM и C++ и всё потому, что там используется разные способ вывода.
В случае с FASM (не поленитесь глянуть исходный код) в регистр edx записывается длина строки, в регистр rsi записывается актуальный адрес начала строки; затем в регистры edi и eax записываются параметры системного вызова - вывод в стандартный вывод (пардон за тавтологию) и производится оный системный вызов.
Если открыть в HEX редакторе, то можно увидеть следующее:
Чтобы изменить строку, надо, всего лишь, определить адрес её начала (справа внизу можете увидеть текст "Hello 64-bit world!") и подсчитать длину: 20 символов - 0x14 в шестнадцатеричном исчислении.
Всего в коде есть несколько мест, где используется 14, однако, ориентируясь на цифровые интерпретации команды MOV - можно найти нужную величину в строке 0000B0; теперь всё, что нужно сделать - это изменить величину с 14 (напомню, это эквивалент 20 в десятичном исчислении на нечто другое). Давайте заменим текст на строку
d09e20d18dd182d0bed18220d0b4d0b8d0b2d0bdd18bd0b920d0bdd0bed0b2d18bd0b920d0bcd0b8d180
Это код в кодировке UTF-8 длиной 84 (0x54) символа: обновим строку и изменим длину в редакторе (я использую hexedit, но вы можете использовать любой другой). Добавим в конце 0A (перенос строки) и увеличим длину на 1 символ. Запускаем файл и видим:
О этот дивный новый мир
Итак, тут мы справились. Но тут была задача относительно простая - ничего двигать не нужно было и текст был в самом конце. А что же делать в с файлом, написанном на С++?
Для начала давайте откроем его и посмотрим внутрь.
Однако, если покрутить файл вниз, можно обнаружить, что есть какое-то пространство, где неприлично много нулей. Ну прямо сплошные нули.
По смещению в файле, благодаря любезно предоставленному "содержимому" мы можем определить, что данный сегмент полностью относится к секции .eh_frame, которая в файле начинается со смещения 0x620 и продолжается неприличные 244 байта.
Вообще, секция .eh_frame используется при обработке исключений, но в нашем случае - там относительно пусто. Воспользуемся этим. Давайте туда впишем нашу строку. На адресе 770 данные начинаются с 0A; пропустим 4 байта, включая тот самый 0A и впишем свою строку.
Возможно, сиё действие немного непонятно, но это потому, что я несколько забежал вперёд (у меня есть небольшое преимущество, я всё это уже проделал ранее, так что некоторые подготовительные действия делаю ещё до того, как они потребуются).
Но теперь главный вопрос, а что нам с этим делать? Правильно, запускать исполняемый файл в отладчике gdb.
И что же мы видим? А видим мы вызов функции printf, но, по какой-то причине, в регистр edi передаётся только адрес нашей строки 0х4005e0 (ниже расскажу, как я это определил), но не передаётся длина. А потому, что длина нам и не нужна. Функция printf принимает на вход всего 1 аргумент - начало строки. И выводит текст до тех пор, пока не встретит символ 0x0. То есть, если передать какой-то адрес, функция будет выводить всё, начиная с этого адреса и до тех пор, пока не упрётся в нуль-символ.
Сразу отвечаю на вопрос, как же я узнал адрес строки. Это сделать довольно несложно. Данная строка находится в секции .rodata (это можно увидеть если открыть файл objdump -sj .rodata <имя файла>).
Ну вот мы и нашли значение, место использования. Давайте же теперь найдём этот адрес в файла и заменим его на новый: 0x770 + 4 (помните, 4 символа мы пропустили) = 0x774. Однако, надо это привести к правильному виду, который используется для адресации.
У каждой секции есть несколько параметров: размер, адрес в памяти (VMA и LMA - чаще всего они одинаковые), смещение в файле.
Можно заметить, что адрес в памяти на 0x400000 больше смещения в файле. На то есть определённые причины, связанные с правилами адресации, но они нам не так нужны. Что мы можем уяснить, так это то, что если к адресу смещения в файле прибавить 0x400000, то получим адрес в памяти.
Это не совсем правильный подход; правильней было бы брать начальный VMA адрес и брать его за основу, но в нашем случае это не столь важно.
Таким образом, адрес в памяти, с которого начинается наша строка составляет 0x400774. Давайте же теперь найдём адрес 0х4005e0 и заменим его на новый.
Пробуем в hexedit найти строку 4005e0 и ничего не находим. Нет такой строки. Но паниковать рано. Дело в том, что в файле используется Little Endian формат (это описано в заголовке программы, но я об этом ещё не упоминал). Это можно узнать, если открыть файл при помощи readelf -h.
Что нам это даёт? Практически ничего, за исключением формы записи: их следует записывать от младших байт к старшим. То есть 40 05 e0 надо записать как e0 05 40. В обратном порядке то есть.
Итак, меняем на наш адрес и получаем
Послесловие
Если вы попробуете повторить всё это, то ваши адреса могут отличаться от моих. Просто имейте это в виду и делайте по аналогии. Но мы только что хакнули файл, заменив одни данные другими.
Что ещё можно было сделать? Например, можно было добавить под всеми секциями ещё одну и записать текст туда, чтобы не менять прочие секции. К слову, туда можно было бы записать и какой-то код, после чего передать ему управление из функции main. А уж что будет делать этот код - вариантов много.
Правда, должен заметить, что внедрение своего кода в исполняемый файл может не сработать: некоторые файлы имеют подпись, что препятствует запуску, если файл был модифицирован. А некоторые - отслеживаются по размеру и, если он данных прибавилось, то он отказывается запускаться. Это хоть и обходится, но просто имейте в виду, что борьба брони и снаряда продолжается.
Интересна ли вам эта тема? Желаете продолжение?