Как Greenplum хранит и обрабатывает XML-документы, зачем для этого нужны утилиты gpfdist и gpload, каковы их конфигурации для выполнения XSLT-преобразований XML-файлов и их загрузки/выборки во внешние таблицы MPP-СУБД.
Работа с XML-документами и XSLT-преобразования в Greenplum
Greenplum, как и PostgreSQL, также поддерживает работу со сложными типами данных и может вести себя подобно документо-ориентированной СУБД, обрабатывая не только JSON, но и XML-документы. Для этого есть специальный тип данных – xml, который проверяет правильность входных значений XML-документа, а также позволяет выполнять над этими данными типобезопасные операции. Для использования этого типа данных конфигурация развертывания с библиотекой libxml, что включено по умолчанию для сборок VMware Greenplum.
Тип данных xml хранит правильно сформированные XML-документы, как определено стандартом XML, а также фрагменты содержимого, которые определяются путем ссылки на более разрешительный узел документа модели XQuery и XPath. Это означает, что фрагменты контента могут иметь более одного элемента верхнего уровня или символьного узла. Выражение IS DOCUMENT позволяет оценить, является ли конкретное xml-значение полным документом или только фрагментом содержимого.
Чтобы избежать ошибок из-за разной кодировки XML-документов на клиенте и на сервере, рекомендуется делать их одинаковыми. Поскольку XML-данные в Greenplum обрабатываются в UTF-8, вычисления будут наиболее эффективными, если кодировка сервера также будет UTF-8.
Тип данных xml не содержит операторов сравнения, поскольку не существует четко определенного и универсально полезного алгоритма сравнения данных XML. Поэтому невозможно получить строки таблицы простым сравнением столбца со значением поиска в XML-документе. Хотя значения XML обычно имеют отдельное ключевое поле, например, идентификатор, можно сперва преобразовать значения XML в символьные строки. Из-за отсутствия в этом типе данных операторов сравнения, создать индекс для столбца этого типа тоже нельзя. Поэтому для быстрого поиска в XML-данных можно привести выражение к типу символьной строки и индексировать его или индексировать выражение XPath. Фактический запрос придется корректировать для поиска по индексированному выражению.
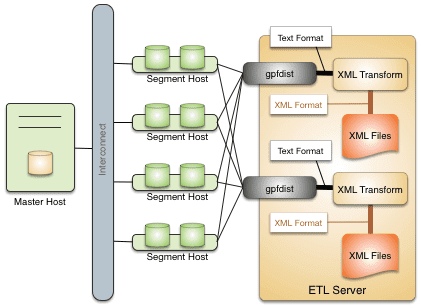
Greenplum может читать и записывать XML-данные во внешние таблицы и из них с помощью утилиты gpfdist, которая работает с форматами данных, не поддерживаемых инструкцией CREATE EXTERNAL TABLE. Преобразование ввода считывает файл в формате внешних данных и выводит строки в формате, указанном в предложении внешней таблицы FORMAT. Выходное преобразование получает строки в текстовом формате и преобразует их в формат внешних данных gpfdist. Чтобы настроить это преобразование формата данных, надо выполнить команду, которую утилита gpfdist может вызываться с именем файла, содержащего XML-данные. Например, написать скрипт, который выполняет XSLT-преобразование XML-файла для вывода строк, чьи столбцы разделены вертикальной чертой |.
Преобразования настраиваются в файле конфигурации в формате YAML, который передается утилите gpfdist в командной строке. Если надо загрузить внешние данные в таблицу Greenplum, можно использовать утилиту gpload для автоматизации задач по созданию внешней таблицы, запуску gpfdist и загрузке преобразованных данных в таблицу базы данных.
Наиболее распространенным сценарием XSLT-преобразований XML-файлов в Greenplum является доступ к данным во внешних XML-файлах. Утилита gpfdist выполняет преобразование файлов XML на ETL-сервере следующим образом:
- определяет схему XSLT-преобразования;
- выполняет XSLT-преобразование согласно настройкам в файле конфигурации gpfdist
- переносит данные в таблицу Greenplum.
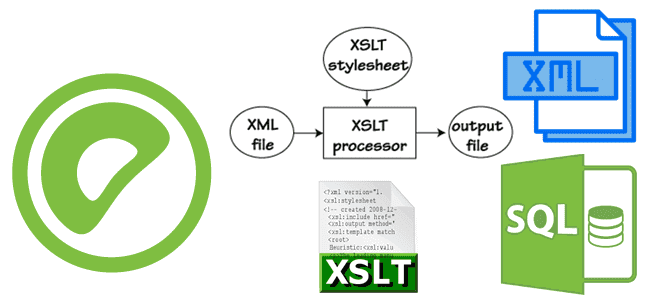
Напомним, XSLT (eXtensible Stylesheet Language Transformations) — язык преобразования XML-документов. XSLT позволяет отделить данные от их представления и преобразовать XML-документы из одной XSD-схемы в другую. Правила преобразования данных из исходного дерева XML-документа пишутся на языке запросов XPath. XSLT-процессор получает на входе два документа: входной XML-документ и таблицу стилей XSLT, чтобы создать выходной документ.
Язык XSLT является декларативным: он определяет правила, которые будут применяться к XML-документу во время преобразования по фиксированному алгоритму. Сначала XSLT-процессор разбирает файл преобразования и строит XML-дерево входного файла, затем ищет подходящий для корневого узла шаблон и вычисляет его содержимое. Инструкции в каждом шаблоне декларируют XSLT-процессору создание определенного тега или обработку какого-либо узла по какому-то правилу. Как это сделать, рассмотрим далее на примере.
Практический пример
В качестве практического примера возьмем исходный XML-документ, который содержит набор данных по заявкам слушателей на курсы по бизнес-анализу:
Предположим, необходимо преобразовать эти данные в текстовый формат с разделителями в несколько столбцов: course, name, phone, email, corp, wishes. XSLT-спецификация, которая будет описывать это преобразование, выглядит так:
Этот XSLT-шаблон преобразует исходный XML в текстовый формат с разделителями. Для полей email и wishes, которые могут отсутствовать, преобразование может выводить пустую строку. Также, информация из wishes объединяется в одно поле, окружённое кавычками.
Целью этого преобразования является импорт всех данных во внешнюю таблицу Greenplum назавнием applications_table с текстовыми полями course, name, phone, email, corp, wishes. Для этого нужно запустить утилиту gpfdist с настроенным файлом конфигурации, создать внешнюю таблицу и загрузить туда данные, а потом остановить gpfdist. XLST-преобразование указывается в предложении CREATE EXTERNAL TABLE определения LOCATION:
Файл конфигурации gpfdist использует YAML-формат версии 1.1 и реализует схему для определения параметров преобразования. Утилита gpfdist обрабатывает документ по порядку и использует отступы (пробелы) для определения иерархии документа и взаимоотношений разделов друг с другом. Базовая структура файла конфигурации для рассматриваемого примера выглядит так:
Можно автоматизировать процесс переноса данных с помощью утилиты gpload, которая создает внешнюю таблицу в Greenplum, запустит экземпляры gpfdist с файлом конфигурации, содержащим преобразование и выполнит команду вставки INSERT INTO или выборки данных SELECT FROM, а также удалит определение внешней таблицы. Для этого необходимо задать настройки преобразования TRANSFORM и TRANSFORM_CONFIG в разделе INPUT управляющего файла утилиты gpload. Параметр TRANSFORM_CONFIG указывает имя файла конфигурации gpfdist, а TRANSFORM указывает имя преобразования, описанного в файле с именем TRANSFORM_CONFIG.
Имя преобразования должно появиться в двух местах: в настройке TRANSFORM файла конфигурации gpfdist и в разделе TRANSFORMATIONS файла, указанного в TRANSFORM_CONFIG. В управляющем файле gpload можно задать необязательный параметр MAX_LINE_LENGTH, который указывает максимальную длину строки в данных преобразования XML, передаваемых в gpload.
После загрузки данных из XML-документов во внешние таблицы Greenplum, к ним можно обращаться с помощью стандартных SQL-операторов, которые поддерживает эта MPP-СУБД.
Узнайте больше про администрирование и эксплуатацию Greenplum для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Статья: https://bigdataschool.ru/blog/news/greenplum/xml-processing-in-greenplum.html
Курсы: https://bigdataschool.ru/courses/greenplum-for-data-engineers https://bigdataschool.ru/courses/greenplum-arenadata-administration
Наш сайт: https://bigdataschool.ru
Копирование, размножение, распространение, перепечатка (целиком или частично), или иное использование материала допускается только с письменного разрешения правообладателя ООО "УЦ Коммерсант"