Статья в работе. Не все параметры описаны.
Парсинг файлов Excel - всегда актуальная задача для аналитиков.
К сожалению, я не нашла полной готовой шпаргалки на русском языке по параметрам команды read_excel. Поэтому потихоньку начну писать свою.
Команда чтения файла имеет следующий синтаксис:
pandas.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None, usecols=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=_NoDefault.no_default, date_format=None, thousands=None, decimal='.', comment=None, skipfooter=0, storage_options=None, dtype_backend=_NoDefault.no_default, engine_kwargs=None)
Источник: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html#pandas.read_excel
Помним, чтобы использовать команды библиотеки pandas, она должна быть сначала импортирована в проект.
import pandas as pd
И дальше, мы используем алиас (псевдоним) для библиотеки, чтобы вызывать её команды. У нас алиас это pd.
Параметры вызова команды read_excel
✔️ io: str, bytes, ExcelFile, xlrd.Book, path object, or file-like object
io - это название файла или название файла вместе с путем до него. Если файл лежит в той же папке, что и проект - достаточно названия, если нет, то пишем полный путь. В пути все слэши (\) надо дублировать, иначе файл не найдется, выполнение команды вызовет ошибку (SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape).
Пример:
pd.read_excel('RP2.xlsx')
pd.read_excel('C:\\Users\\n.britseva\\Downloads\\RP2.xlsx')
✔️sheet_name: str, int, list, or None, default 0
sheet_name - это название листа в файле Excel.
✔️header: int, list of int, default 0
header - это номер строки (строк), с которой начинается обработка файла. До этой строки от начала файла все данные отбрасываются и не используются. Отсчет строк начинается с 0. Если не задан параметр names (следующий по списку), то содержимое строки становится заголовками для столбцов.
Пример:
pd.read_excel('RP2.xlsx',header=2)
Обработка файла начнется с третьей строки.
✔️names: array-like, default None
names - это имена столбцов. Корректно сработает, если содержит столько же наименований, сколько обрабатывается столбцов.
Пример:
pd.read_excel('RP2.xlsx', usecols=[1,2,3], names=['Один','Два','Три'])
Немного забегая вперед, параметр usecols выбирает второй, третий и четвертый столбцы из файла, параметр names присваивает им заголовки.
✔️ index_col: int, str, list of int, default None
index_col - это номер столбца загружаемого диапазона (или всего листа), который станет первым столбцом и из значений которого сформируются названия строк таблицы (датафрейма). Можно указывать не один столбец, а несколько столбцов.
Пример:
pd.read_excel('RP2.xlsx',index_col=1)
Если вы загружаете весь лист, то названия строк сформируются из столбца B (столбец А = 0, столбец B = 1 и т.д.)
pd.read_excel('RP2.xlsx',index_col=[1,2])
Можно указать в качестве названий строк значения сразу нескольких столбцов.
pd.read_excel('RP2.xlsx',index_col='ОТЧЕТ')
Если у вас структурированная таблица и у столбцов есть уникальные заголовки, то можно указать и название столбца. В примере выбран столбец с заголовком "ОТЧЕТ".
✔️ usecols: str, list-like, or callable, default None
usecols - перечень столбцов, которые будут парситься (обрабатываться). Задать можно несколькими способами.
Пример:
pd.read_excel('RP2.xlsx',usecols='B,D,E')
Можно указать названия столбцов через запятую, как строковую переменную.
pd.read_excel('RP2.xlsx',usecols='B:E')
Можно указать диапазон столбцов.
pd.read_excel('RP2.xlsx',usecols='B:E,Q')
Можно совместить способы, указать и диапазон, и конкретные столбцы.
pd.read_excel('RP2.xlsx',usecols=[2,5,7])
Можно указать номера столбцов листа (диапазона), которые нужно обработать.
pd.read_excel('RP2.xlsx',usecols=['ОТЧЕТ'])
Можно обработать столбцы, перечислив их заголовки.
✔️ dtype: Type name or dict of column -> type, default None
✔️ engine: {‘openpyxl’, ‘calamine’, ‘odf’, ‘pyxlsb’, ‘xlrd’}, default None
engine - это прямое указание на формат обрабатываемого файла. По-умолчанию он не указывается. Команда использует следующую логику: если она обнаружила, что формат датасета (файла) OpenDocument (.odf, .ods, .odt), то будет использоваться odf. Если xls, то будет использоваться xlrd. Если xlsb, то будет использоваться pyxlsb. Если все предыдущее не подошло, то будет использоваться openpyxl.
openpyxl поддерживает новые форматы файлов Excel.
calamine поддерживает форматы файлов Excel (.xls, .xlsx, .xlsm, .xlsb) и OpenDocument (.ods).
odf поддерживает форматы файлов OpenDocument (.odf, .ods, .odt).
pyxlsb поддерживает двоичные файлы Excel.
xlrd поддерживает файлы Excel старого стиля (.xls).
В большинстве случаев, указывать engine необходимости нет. Даже если вы файлу excel измените расширение на odf и не укажете engine, команда распознает датасет. А вот если вы попробуете открыть excel-файл с engine='odf', получите ошибку.
Команда применяется, когда io не содержит путь к файлу и не является буфером. Редко встречаемый вариант.
Пример вызова:
pd.read_excel('RP3.odf', engine='odf')
✔️ converters: dict, default None
converters - параметр, с помощью которого можно конвертировать (изменить) содержимое загружаемых столбцов. Для этого требуется сформировать словарь, в котором будет имя столбца и функция конвертации (изменения).
Пример:
slovar={'Цифры': lambda x: x*2}
pd.read_excel('RP2.xlsx',converters=slovar)
или
pd.read_excel('RP2.xlsx',converters={'Цифры': lambda x: x*2})
В загружаемом столбце с заголовком "Цифры" содержимое (число) удваивается.
Кто не сталкивался с lambda - это анонимная функция, то есть без имени. В ней может быть всего одно выражение.
pd.read_excel('RP2.xlsx', converters={4: lambda x: x*2})
Можно использовать не заголовок, а номер столбца (нумерация начинается с 0).
✔️true_values: list, default None
✔️false_values: list, default None
✔️ skiprows: list-like, int, or callable, optional
skiprows - строки, которые надо исключить из парсинга. Можно задать одной цифрой - и тогда с начала файла отсечется указанное число строк, а следующая строка станет заголовками столбцов. Можно задать списком, и тогда исключатся конкретные строки. Первая из оставшихся строк от начала файла станет заголовками столбцов.
Пример:
pd.read_excel('RP2.xlsx',skiprows=2)
Первые две строки будут проигнорированы. Загрузка начнется с 3-ей строки файла. По результату ничем не будет отличаться от
pd.read_excel('RP2.xlsx', header=2)
Похожий пример, но со списком приведет к другому результату:
pd.read_excel('RP2.xlsx',skiprows=[2])
Будет проигнорирована третья строка файла (отсчет строк идет с 0).
Через список можно убирать из загрузки несколько строк:
pd.read_excel('RP2.xlsx',skiprows=[2,4,6])
Проигнорируются 3, 5 и 7 строки (отсчет строк в файле идет с 0).
✔️ nrows: int, default None
nrows - количество строк, которое будет парситься (обрабатываться).
Пример:
pd.read_excel('RP2.xlsx',nrows=3)
Прочитает из файла Excel первые три строки. Первая строка и первый столбец станут заголовками столбцов и строк, соответственно.
✔️ na_values: scalar, str, list-like, or dict, default None
✔️ keep_default_na: bool, default True
✔️ na_filter: bool, default True
✔️ verbose: bool, default False
✔️ parse_dates: bool, list-like, or dict, default False
✔️ date_parser: function, optional
✔️ date_format: str or dict of column -> format, default
✔️ thousands: str, default None
thousands - это сепаратор. Он используется только для столбцов, в которых установлен в Excel формат ячейки "Текст". Если в таких столбцах содержатся в текстовом формате числа с разделителем, например "1.525.456", то данным параметром можно убрать "." и преобразовать строку в число. Или из "1 525 456" убрать пробел " ". Команда работает только на тех столбцах, в которых после ее выполнения останется содержимое, которое можно преобразовать в число.
Пример:
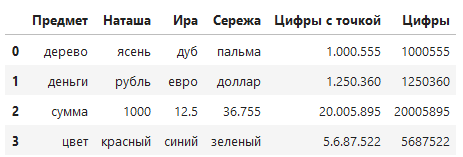
pd.read_excel('RP2.xlsx', thousands='.')
Команда нашла столбец, содержащий цифры и точки. Убрала точки и превратила строковое содержимое в числовое.
Хотя название параметра прямо говорит - что он предназначен для разделителей тысяч (точек, пробелов), его можно использовать и не совсем по назначению. Если параметр встретит "1.5.2.5.4.5.6", то команда выше также уберет из строки все точки и преобразует содержимое в число (как в последней строчке датафрейма-примера).
А можно убрать из чисел, хранящихся в текстовом формате определенные цифры или их последовательность. Но в этом случае, надо помнить, что строка превращается в число. Поэтому если после исключения в начале останутся 0, они тоже исключатся.
Пример:
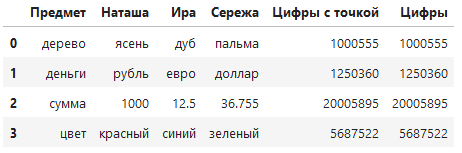
pd.read_excel('RP2.xlsx', thousands='1')
В последнем столбце в первой строке у числа "1000555" исключили "1", осталось "000555", которое превратилось просто в "555".
✔️ decimal: str, default ‘.’
decimal - параметр, который определяет символ десятичной точки для чисел, которые записаны в текстовом формате. Если у вас в столбце записаны числа, например, с запятой вместо точки, и у ячеек при этом текстовый формат, тогда можно применить этот параметр для замены. Если же в Excel десятичным разделителем служит запятая, но формат ячеек "Общий" или "Числовой" - применять параметр необходимости нет. Запятая на точку поменяются автоматически.
Пример:
pd.read_excel('RP2.xlsx', decimal=',')
Команда найдет столбец "Цифры с запятой" (в Excel у ячеек формат "Текстовый") и заменит запятую на точку.
pd.read_excel('RP2.xlsx', decimal='*')
Команда найдет столбец "Цифры со звездочкой" (в Excel у ячеек формат "Текстовый") и заменит звездочку на точку.
✔️ comment: str, default None
comment - это текст, который ищется в каждой строке. При нахождении: от этого текста и до конца строки содержимое стирается. Если в качестве искомого текста передаются цифры, то поиск будет только в ячейках, у которых формат текста.
Пример:
pd.read_excel('RP2.xlsx', comment='1000')
В первой строке (с индексом 0) в столбце "Цифры" находилось число в текстовом формате "1000555". Так как это был текст, команда с параметром нашла в нем содержимое "1000" и до конца строки содержимое удалила.
В третьей строке (с индексом 2) "1000" находится в ячейке с числовым форматом, поэтому команда с параметром comment в ней не сработала.
✔️ skipfooter: int, default 0
✔️ storage_options: dict, optional
✔️ dtype_backend: {‘numpy_nullable’, ‘pyarrow’}, default ‘numpy_nullable’
✔️ engine_kwargs: dict, optional