Хэш-таблицы широко используются в программировании, и даже новички знакомятся с ними практически сразу. Сами по себе они, однако, встречаются редко. Чаще на их основе делаются другие структуры, такие как множества или ассоциативные массивы.
Чтобы было понятно, что и откуда и зачем и как, возьмём практическую задачу. Нужно реализовать множество. Для простоты скажем, что там может быть не более 10 элементов.
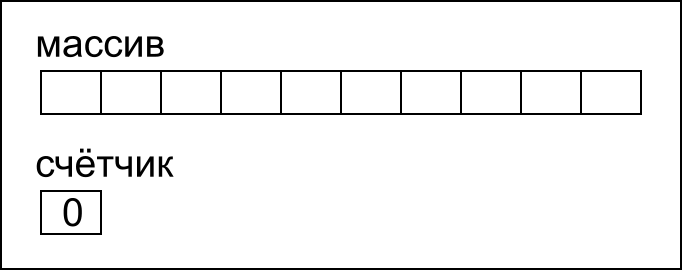
Мы можем создать массив длиной в 10 элементов, и добавить к нему счётчик элементов:
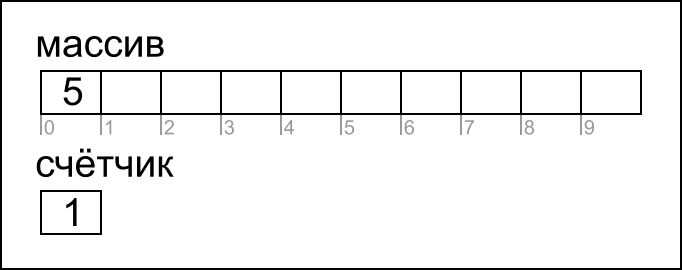
Добавим в множество значение 5. Для этого запишем в первую свободную позицию массива (0) значение 5, и увеличим счётчик на 1:
Аналогично добавим значения 3, 8, 2:
Теперь в чём трудность? Множество должно содержать только уникальные элементы. Если сейчас попробовать снова добавить значение 8, то ничего не должно произойти, потому что такое значение в множестве уже есть.
Следовательно, перед добавлением элемента нужно проверить, если ли он в массиве.
Посмотрите, как легко ответить на вопрос "Какое значение у элемента с индексом 2?" Нужно к адресу начала массива добавить 2, получится новый адрес, и вот мы нашли значение, которое там лежит: 8.
Индекс может быть хоть 0, хоть 999999 – нет никакой разницы, это всегда делается за одну операцию.
А вот вопрос в обратную сторону: "Какой индекс у элемента со значением 8?" не решается так же тривиально, но именно на него нужно ответить, чтобы найти элемент в множестве.
Для этого нужно перебрать все уже добавленные элементы. Начиная с первого, мы смотрим:
- По индексу 0, значение 5 = 8? Нет.
- По индексу 1, значение 3 = 8? Нет.
- По индексу 2, значение 8 = 8? Да.
Значит, 8 уже есть, индекс у него 2, дальше можно уже не проверять.
То же самое происходит, когда нужно удалить элемент из множества. Чтобы его удалить, нужно знать, какой у него индекс. И значит, опять всё проверять.
Лучший и худший случай
Если мы попробуем добавить значение 5, то с помощью перебора найдём дубликат сразу же, так как он расположен первым. Это лучший случай.
Если попробуем добавить 2, то придётся перебрать весь список, потому что дубликат находится в конце. Это худший случай.
При реальном использовании количество перебираемых элементов в среднем окажется где-то посередине, то есть N/2.
Предположим, что длина массива – миллион. Теперь нам придётся совершить до миллиона операций сравнения, чтобы найти элемент. И конечно, проблема становится видна: при том, что алгоритм работает правильно, он будет очень медленный на больших множествах.
Тут нам и приходит на помощь таинственная
Хэш-функция
Пока просто пофантазируем. Допустим, у нас есть волшебная функция. Если передать ей значение элемента, то она вернёт его индекс в массиве. Тогда задача поиска в массиве по значению станет такой же тривиальной, как и поиск по индексу, и поиск будет осуществляться за одну операцию.
Такую функцию назовём хэш-функцией. Слово hash переводится как "рубить, перемешивать", и хорошо подходит для описания сути функции. Она берёт исходное значение, рубит его на кусочки, перемешивает эти кусочки, ахалай-махалай...
...и из этих кусочков получается новое значение, которое каким-то волшебным образом оказывается индексом элемента в массиве. В нашем случае, передав в функцию значение 8, мы получим 2.
Но есть нюанс
Чтобы найти индекс элемента по значению с помощью хэш-функции, мы должны добавлять элемент в массив также с помощью хэш-функции. То есть при добавлении мы теперь берём не первый свободный индекс, а тот, который выдаст хэш-функция.
Таким образом, хэш-функция не угадывает магически, какой индекс у элемента. Она просто преобразовывает одно значение в другое, которое считается индексом при добавлении, а когда ищем то же значение с помощью той же самой функции, то естественно получаем тот же индекс.
Давайте попробуем добавить в наше множество те же элементы, используя самую простую хэш-функцию: она просто ничего не делает и возвращает то же самое число, которое ей передали.
При добавлении числа 5 мы получим индекс 5:
При добавлении чисел 3, 8, 2 получим соответственно индексы 3, 8, 2:
Видите, на этот раз элементы лежат в массиве не подряд, как добавлялись ранее, а раскиданы по разным индексам, которые "вычислила" хэш-функция. Теперь и найти их очень просто. Какой индекс у значения 8? Хэш-функция даёт ответ: 8. Какой индекс у значения 2? Ответ: 2.
А какой индекс у значения 7? Функция даст ответ: 7. Но мы не добавляли такой элемент, поэтому нужна дополнительная информация: был он добавлен или нет. Для хранения такой информации можно выделить дополнительный массив с теми же самыми индексами:
Тогда, добавляя значение, мы в массиве признаков ставим признак 1 по тому же индексу. При поиске значения проверяем признак: если он равен 1, значит значение было добавлено.
Легко заметить, что когда индекс равен значению, нет нужды держать два массива. Достаточно оставить массив признаков:
Он содержит и информацию о добавленных значениях, и сами значения в виде индексов.
Такие массивы очень удобно использовать, когда у нас есть ограниченное количество значений. Например, 16-битное число это диапазон от 0 до 65535. Сделав массив длиной 65536 элементов, мы можем организовать хэш-таблицу для хранения множества любых уникальных 16-битных значений. С поиском любого из них за одну операцию.
Такие решения довольно часто применяются на практике, но всё же не покрывают всех потребностей. Да и хэш-функция, которая ничего не делает, вроде как и не хэш, и не функция вовсе, не говоря уж про ахалай-махалай и даже банальный трах-тибидох.
А вот банальный трах-тибидох мы можем сделать прямо сейчас.
Давайте добавлять не значения 2, 3, 5, 8, а значения 158352, 834633, 486925, 137928. Хмм... прежний подход не работает. У числа 158352 индекс получится тоже 158352, но длина нашего массива всего 10, в него физически не влезет такой индекс.
Давайте увеличим массив? Но ресурсы компьютера не бесконечны, и ограничение всё равно когда-то возникнет, поэтому дело не в размере массива.
Пусть числа будут большие, но если их будет всего 10, то и разместить их можно в 10-местном массиве, ведь так?
Для этого нужно по-прежнему переводить значение в индекс, но становится очевидным, что для любого значения индекс должен находиться в пределах 0..9.
Мы можем добиться этого, если будем брать у каждого значения остаток от деления на 10, который и находится в пределах 0..9. Тогда наши большие числа получат такие индексы:
Можно экстраполировать на другую длину массива, например 1024: будем брать остаток от деления на 1024, который будет находиться в пределах 0..1023, и т.д.
Вот мы уже получили вполне себе хэш-функцию, которая взаправду манипулирует исходным значением и получает из него другое. И этого было бы вполне достаточно, если бы не одна неприятная вещь.
Коллизии
Структуры данных на основе хэш-таблиц преподносятся изучающим программирование как очень быстрые, потому что поиск в них делается за 1 операцию. Но это лишь половина правды.
Попробуем добавить в наше множество числа 158352, 724532, 842782. Если у каждого из них взять остаток от деления на 10, то получим 2. То есть значения разные, но результат хэш-функции у них одинаковый, и все они претендуют на одну и ту же ячейку массива с индексом 2.
Возникла коллизия. Что делать? Надо менять хэш-функцию. По сути, остаток от деления на 10 это просто последняя цифра числа. Если брать не последнюю, а к примеру первую цифру, то получим индексы 1, 7, 8, которые прекрасно распределятся в массиве:
Но также понятно, что это не панацея. Данный способ работает только для вышеуказанных чисел, и всегда можно подобрать такие, которые создадут коллизию.
Дальше начинается уже конкретный ахалай-махалай. Можно брать цифры из середины. Можно переставлять их местами. Можно их с чем-то складывать.
Лучше всего представить биты числа (не цифры, а прямо биты) в виде колоды карт, которую мы перемешиваем. При этом части колоды сдвигаются и меняются местами, отдельные карты вынимаются и вклиниваются между другими картами, и таким образом происходит перемешивание, результат которого будет слабо зависеть от начального расположения карт.
Это и есть настоящий хэш.
Сами алгоритмы хэширования просто так не опишешь. Если посмотреть на какие-нибудь исходники, вразумительного там будет мало. Какие-то магические константы, какие-то операции битового сдвига и XOR... Но в итоге цель это просто качественное перемешивание.
Универсального решения "делай вот так" нет, зачастую подбирать хэш-функцию и магические константы нужно методом проб и ошибок на каком-то определённом наборе данных, с которым собираемся работать. Чем более ограничен набор, и чем больше его характеристик можно формализовать, тем проще будет получить для него оптимальную хэш-функцию.
Вёдра
Но всё же, какой бы хорошей ни была хэш-функция, коллизий не всегда можно избежать. Представим, что есть тысяча возможных значений, которые должны каким-то образом трансформироваться в индексы 0..9. Очевидно, что на каждый индекс будет приходиться в среднем по 100 значений. Это не решается никаким алгоритмом. Если индексов меньше, чем возможных значений – коллизии будут.
Для хранения элементов с коллизиями в хэш-таблице предусмотрены так называемые "вёдра" (buckets). К примеру, два значения 123 и 333 порождают коллизию на индексе 3. По индексу 3 в массиве хранится не какое-то значение, а ведро – ещё один массив. И в это ведро складываются все элементы, которые получили индекс 3.
В таком случае становится ясно, что поиск индекса по значению 333 уже не будет занимать одну операцию. С помощью одной операции можно найти только ведро с индексом 3, а далее нужно по старинке перебирать элементы внутри ведра, пока не найдём нужный.
Всё это можно пытаться как-то оптимизировать, но основной вывод в том, что коллизии внутри хэш-таблицы предполагаются всегда.
Можно говорить, что в хорошо спроектированной хэш-таблице на наборе из более-менее независимых значений поиск чаще всего будет происходить за одну операцию.
Но либо сама таблица может быть маленькой при большом количестве значений. Либо сами значения могут подобраться так, что хэш-функция будет генерировать много коллизий, и значения начнут складываться в вёдра в больших количествах. Тогда поиск в вёдрах сильно замедлит работу хэш-таблицы и мы фактически вернёмся к первоначальному примитивному варианту реализации.
В качестве практического примера я возьму 10 чисел, у которых совпадают первая, последняя и средняя цифры:
11121, 12131, 13141, 14151, 15161, 16171, 17181, 18191, 19101, 10111
И попробую разместить их в 10-местном массиве. Я не могу взять такую хэш-функцию, которая возвращает первую, последнюю или среднюю цифру, так как очевидно, что будут коллизии у всех вообще чисел. Можно было бы взять вторую или предпоследнюю, но это просто пример, так что будем считать, что брать любую цифру – не катит.
В то же время написать какую-то продвинутую хэш-функцию я пока не могу, и поэтому вместо неё возьму генератор случайных чисел. Его особенность в том, что если его проинициализировать (засеять) каким-то определённым числом, то следующее выданное им случайное число будет тоже определённым, но никак не похожим на значение засева. Так что его можно использовать как хэш-функцию: засевать значением и получать другое значение, которое интерпретировать как индекс.
Я сделал проверочную программу в онлайн-компиляторе PHP:
Функция mt_rand() использует алгоритм "Вихрь Мерсенна". И вот результат:
Получилось по одной коллизии на индексах 0, 1, 4, и нет коллизий на индексах 2, 5, 6, 9. При этом индексы 3, 7, 8 остались неиспользованными.
Другой вариант генератора случайных чисел – алгоритм xoshiro. Фрагмент из адаптированной версии в онлайн-компиляторе языка C:
И результат:
Здесь по одной коллизии на индексах 4 и 6, нет коллизий на индексах 0, 1, 2, 3, 5, 8, и не использованы индексы 7, 9. Лучше, но в рамках статистической погрешности.
В целом, оба результата неплохи для неспециализированных функций. Дело не в том, что есть коллизии или неиспользованные индексы (что, конечно, плохо). Дело в том, что вот на этих данных получился относительно приемлемый результат, и на других данных он также получится относительно приемлемым, то есть будет в среднем вот такая стабильность показателей.
Это лучше, чем если бы функция идеально отработала на текущем наборе данных (взяв, к примеру, вторую цифру из числа), но полностью провалилась бы на другом наборе (где вторые цифры оказались бы одинаковы).
Читайте дальше: