Ссылка https://docs.oracle.com/en/java/javase/21/core/virtual-threads.html
Виртуальные потоки - это легковесные потоки, которые сокращают усилия по написанию, обслуживанию и отладке высокопроизводительных параллельных приложений. Для получения справочной информации о виртуальных потоках см. JEP 444. Поток - это наименьшая единица обработки, которую можно запланировать. Он выполняется одновременно с другими подобными единицами и в значительной степени независимо от них. Это экземпляр java.lang.Thread. Существует два вида потоков: потоки платформы и виртуальные потоки.
Что такое поток платформы?
Поток платформы реализован как тонкая оболочка вокруг потока операционной системы. Поток платформы выполняет Java-код в базовом потоке операционной системы на протяжении всего срока исполнения. Следовательно, количество доступных потоков платформы ограничено количеством потоков операционной системы. Потоки платформы обычно имеют большой стек потоков, они подходят для выполнения всех типов задач, но ограниченны ресурсами.
Что такое виртуальный поток?
Как и поток платформы, виртуальный поток также является экземпляром java.lang.Thread. Однако виртуальный поток не привязан к конкретному потоку операционной системы. Виртуальный поток по-прежнему выполняет код в потоке операционной системы. Однако, когда код, выполняемый в виртуальном потоке, вызывает блокирующую операцию ввода-вывода, среда выполнения Java приостанавливает работу виртуального потока до тех пор, пока его нельзя будет возобновить. Поток операционной системы, связанный с приостановленным виртуальным потоком, теперь свободен для выполнения операций для других виртуальных потоков.
Виртуальные потоки реализованы аналогично виртуальной памяти. Для имитации большого объема памяти операционная система сопоставляет большое виртуальное адресное пространство с ограниченным объемом оперативной памяти. Аналогично, для имитации большого количества потоков среда выполнения Java сопоставляет большое количество виртуальных потоков небольшому количеству потоков операционной системы.
В отличие от потоков платформы, виртуальные потоки обычно имеют неглубокий стек вызовов, выполняя всего один вызов HTTP-клиента или один запрос JDBC. Хотя виртуальные потоки поддерживают локальные переменные потока и наследуемые локальные переменные потока, вам следует тщательно продумать их использование, поскольку одна JVM может поддерживать миллионы виртуальных потоков.
Виртуальные потоки подходят для выполнения задач, которые большую часть времени проводят заблокированными, часто ожидая завершения операций ввода-вывода. Однако они не предназначены для длительных операций с интенсивным использованием ЦП.
Зачем использовать виртуальные потоки?
Используйте виртуальные потоки в высокопроизводительных параллельных приложениях, особенно в тех, которые состоят из большого количества параллельных задач, которые тратят большую часть своего времени на ожидание. Серверные приложения являются примерами приложений с высокой пропускной способностью, поскольку они обычно обрабатывают множество клиентских запросов, которые выполняют блокирующие операции ввода-вывода, такие как извлечение ресурсов.
Виртуальные потоки не являются более быстрыми потоками; они выполняют код не быстрее, чем потоки платформы. Они существуют для обеспечения масштаба (более высокой пропускной способности), а не скорости (меньшей задержки).
Создание и запуск виртуального потока
API-интерфейсы Thread и Thread.Builder предоставляют способы создания как платформенных, так и виртуальных потоков. Класс java.util.concurrent.Executors также определяет методы для создания ExecutorService, который запускает новый виртуальный поток для каждой задачи.
Создание виртуального потока с помощью класса Thread и интерфейса Thread.Builder
Вызовите Thread.ofVirtual() метод для создания экземпляра Thread.Builder для создания виртуальных потоков.
В следующем примере создается и запускается виртуальный поток, который печатает сообщение. Он вызывает join метод для ожидания завершения виртуального потока. (Это позволяет вам увидеть напечатанное сообщение до завершения основного потока.)
КопироватьThread thread = Thread.ofVirtual().start(() -> System.out.println("Hello"));
thread.join();
Thread.Builder Интерфейс позволяет создавать потоки с общими Thread свойствами, такими как имя потока. Подинтерфейс Thread.Builder.OfPlatform создает потоки платформы, в то время как Thread.Builder.OfVirtualсоздает виртуальные потоки.
В следующем примере создается виртуальный поток с именем MyThread с Thread.Builder интерфейсом:
КопироватьThread.Builder builder = Thread.ofVirtual().name("MyThread");
Runnable task = () -> {
System.out.println("Running thread");
};
Thread t = builder.start(task);
System.out.println("Thread t name: " + t.getName());
t.join();
В следующем примере создаются и запускаются два виртуальных потока с помощью Thread.Builder:
КопироватьThread.Builder builder = Thread.ofVirtual().name("worker-", 0);
Runnable task = () -> {
System.out.println("Thread ID: " + Thread.currentThread().threadId());
};
// name "worker-0"
Thread t1 = builder.start(task);
t1.join();
System.out.println(t1.getName() + " terminated");
// name "worker-1"
Thread t2 = builder.start(task);
t2.join();
System.out.println(t2.getName() + " terminated");
В этом примере выводятся данные, аналогичные приведенным ниже:
КопироватьThread ID: 21
worker-0 terminated
Thread ID: 24
worker-1 terminated
Создание и запуск виртуального потока с исполнителями. Метод newVirtualThreadPerTaskExecutor()
Исполнители позволяют вам отделить управление потоками и их создание от остальной части вашего приложения.
В следующем примере создается ExecutorService с помощью Executors.newVirtualThreadPerTaskExecutor() метода. Всякий раз, когда ExecutorService.submit(Runnable) вызывается, создается новый виртуальный поток и запускается для выполнения задачи. Этот метод возвращает экземпляр Future. Обратите внимание, что метод Future.get() ожидает завершения задачи потока. Следовательно, в этом примере выводится сообщение после завершения задачи виртуального потока.
Копироватьtry (ExecutorService myExecutor = Executors.newVirtualThreadPerTaskExecutor()) {
Future<?> future = myExecutor.submit(() -> System.out.println("Running thread"));
future.get();
System.out.println("Task completed");
// ...
Пример многопоточного клиент-сервера
Следующий пример состоит из двух классов. EchoServer это серверная программа, которая прослушивает порт и запускает новый виртуальный поток для каждого соединения. EchoClient это клиентская программа, которая подключается к серверу и отправляет сообщения, введенные в командной строке.
EchoClient создает сокет, тем самым получая соединение с EchoServer. Он считывает входные данные от пользователя в стандартном потоке ввода, а затем пересылает этот текст в EchoServer, записывая текст в сокет. EchoServer передает входные данные обратно через сокет на EchoClient. EchoClient считывает и отображает данные, переданные обратно на него с сервера. EchoServer может обслуживать несколько клиентов одновременно через виртуальные потоки, по одному потоку на каждое клиентское соединение.
Копироватьpublic class EchoServer {
public static void main(String[] args) throws IOException {
if (args.length != 1) {
System.err.println("Usage: java EchoServer <port>");
System.exit(1);
}
int portNumber = Integer.parseInt(args[0]);
try (
ServerSocket serverSocket =
new ServerSocket(Integer.parseInt(args[0]));
) {
while (true) {
Socket clientSocket = serverSocket.accept();
// Accept incoming connections
// Start a service thread
Thread.ofVirtual().start(() -> {
try (
PrintWriter out =
new PrintWriter(clientSocket.getOutputStream(), true);
BufferedReader in = new BufferedReader(
new InputStreamReader(clientSocket.getInputStream()));
) {
String inputLine;
while ((inputLine = in.readLine()) != null) {
System.out.println(inputLine);
out.println(inputLine);
}
} catch (IOException e) {
e.printStackTrace();
}
});
}
} catch (IOException e) {
System.out.println("Exception caught when trying to listen on port "
+ portNumber + " or listening for a connection");
System.out.println(e.getMessage());
}
}
}
Копироватьpublic class EchoClient {
public static void main(String[] args) throws IOException {
if (args.length != 2) {
System.err.println(
"Usage: java EchoClient <hostname> <port>");
System.exit(1);
}
String hostName = args[0];
int portNumber = Integer.parseInt(args[1]);
try (
Socket echoSocket = new Socket(hostName, portNumber);
PrintWriter out =
new PrintWriter(echoSocket.getOutputStream(), true);
BufferedReader in =
new BufferedReader(
new InputStreamReader(echoSocket.getInputStream()));
) {
BufferedReader stdIn =
new BufferedReader(
new InputStreamReader(System.in));
String userInput;
while ((userInput = stdIn.readLine()) != null) {
out.println(userInput);
System.out.println("echo: " + in.readLine());
if (userInput.equals("bye")) break;
}
} catch (UnknownHostException e) {
System.err.println("Don't know about host " + hostName);
System.exit(1);
} catch (IOException e) {
System.err.println("Couldn't get I/O for the connection to " +
hostName);
System.exit(1);
}
}
}
Планирование виртуальных потоков и Закрепленные виртуальные потоки
Операционная система составляет расписание при запуске потока платформы. Однако среда выполнения Java составляет расписание при запуске виртуального потока. Когда среда выполнения Java планирует виртуальный поток, она назначает или монтирует виртуальный поток в потоке платформы, затем операционная система планирует этот поток платформы как обычно. Этот поток платформы называется несущей. После выполнения некоторого кода виртуальный поток может размонтироваться со своей несущей. Обычно это происходит, когда виртуальный поток выполняет блокирующую операцию ввода-вывода. После того, как виртуальный поток отключается от своего носителя, носитель свободен, что означает, что планировщик среды выполнения Java может подключить к нему другой виртуальный поток.
Виртуальный поток не может быть размонтирован во время операций блокировки, когда он закреплен на своем носителе. Виртуальный поток закрепляется в следующих ситуациях:
- Виртуальный поток выполняет код внутри synchronized блока или метода
Закрепление не делает приложение некорректным, но может снизить его масштабируемость. Попробуйте избежать частого и долговременного закрепления, изменив synchronized блоки или методы, которые выполняются часто, и защитив потенциально длительные операции ввода-вывода с помощью java.util.concurrent.locks.ReentrantLock.
Отладка виртуальных потоков
Виртуальные потоки по-прежнему остаются потоками. Отладчики могут работать с ними, как с потоками платформы. JDK Flight Recorder и jcmd инструменты имеют дополнительные функции, помогающие вам наблюдать за виртуальными потоками в ваших приложениях.
События JDK Flight Recorder для виртуальных потоков
JDK Flight Recorder (JFR) может выдавать события, связанные с виртуальными потоками:
- jdk.VirtualThreadStart и jdk.VirtualThreadEnd указывают, когда начинается и заканчивается виртуальный поток. По умолчанию эти события отключены.
- jdk.VirtualThreadPinned указывает, что виртуальный поток был закреплен (и его поток-носитель не был освобожден) на время, превышающее пороговое значение. Это событие включено по умолчанию с пороговым значением 20 мс.
- jdk.VirtualThreadSubmitFailed указывает, что произошел сбой при запуске или отключении виртуального потока, вероятно, из-за проблемы с ресурсами. Парковка виртуального потока освобождает базовый поток-носитель для выполнения другой работы, и распаковка виртуального потока планирует его продолжение. Это событие включено по умолчанию.
Включите события jdk.VirtualThreadStart и jdk.VirtualThreadEnd через JDK Mission Control или с помощью пользовательской конфигурации JFR, как описано в Java Platform Standard Edition Flight Recorder API Programmer's Guide/17 Flight Recorder Configurations.
Чтобы распечатать эти события, выполните следующую команду, где recording.jfr - имя файла вашей записи:
jfr print --events jdk.VirtualThreadStart,jdk.VirtualThreadEnd,jdk.VirtualThreadPinned,jdk.VirtualThreadSubmitFailed recording.jfr
Просмотр виртуальных потоков в дампах потоков jcmd
Вы можете создать дамп потока как в обычном текстовом формате, так и в формате JSON:
Копироватьjcmd <PID> Thread.dump_to_file -format=text <file> jcmd <PID> Thread.dump_to_file -format=json <file>
Формат JSON идеально подходит для инструментов отладки, которые принимают этот формат.
В jcmd дампе потоков перечислены виртуальные потоки, которые блокируются при сетевых операциях ввода-вывода, и виртуальные потоки, которые создаются ExecutorService интерфейсом. Он не включает адреса объектов, блокировки, статистику JNI, статистику кучи и другую информацию, которая появляется в традиционных дампах потоков.
Виртуальные потоки: руководство по внедрению
Виртуальные потоки - это потоки Java, которые реализуются средой выполнения Java, а не операционной системой. Основное различие между виртуальными потоками и традиционными потоками, которые мы привыкли называть платформенными потоками, заключается в том, что у нас может быть очень много активных виртуальных потоков, даже миллионы, запущенных в одном и том же процессе Java. Именно их большое количество придает виртуальным потокам их мощь: они могут более эффективно запускать серверные приложения, написанные в стиле "поток на запрос", позволяя серверу обрабатывать гораздо больше запросов одновременно, что приводит к более высокой пропускной способности и меньшим затратам оборудования.
Поскольку виртуальные потоки являются реализацией java.lang.Thread и соответствуют тем же правилам, которые указаны java.lang.Thread начиная с Java SE 1.0, разработчикам не нужно изучать новые концепции, чтобы использовать их. Однако невозможность создавать очень много потоков платформы — единственная реализация потоков, доступная в Java в течение многих лет, — породила методы, разработанные для решения проблемы их высокой стоимости. Эти методы контрпродуктивны при применении к виртуальным потокам, и от них следует отказаться. Более того, огромная разница в стоимости формирует новый взгляд на потоки, которые на первый взгляд могут показаться чужеродными.
Это руководство не претендует на то, чтобы быть исчерпывающим и охватывать все важные детали виртуальных потоков. Оно предназначено лишь для того, чтобы предоставить вводный набор рекомендаций, помогающих тем, кто хочет начать использовать виртуальные потоки, извлечь из них максимум пользы.
Напишите простой синхронный код, использующий блокирующие API ввода-вывода в стиле Поток-на-запрос
Виртуальные потоки могут значительно повысить пропускную способность — не задержку — серверов, написанных в стиле "поток на запрос". В этом стиле сервер выделяет поток для обработки каждого входящего запроса на все его время. Он выделяет по крайней мере один поток, потому что при обработке одного запроса вы можете захотеть задействовать больше потоков для одновременного выполнения некоторых задач.
Блокировка потока платформы обходится дорого, потому что он удерживает поток — относительно ограниченный ресурс - в то время как он не выполняет много значимой работы. Поскольку виртуальных потоков может быть множество, их блокировка обходится дешево и поощряется. Следовательно, вам следует писать код в простом синхронном стиле и использовать блокирующие API ввода-вывода.
Например, следующий код, написанный в неблокирующем асинхронном стиле, не принесет большой пользы от виртуальных потоков.
КопироватьCompletableFuture.supplyAsync(info::getUrl, pool)
.thenCompose(url -> getBodyAsync(url, HttpResponse.BodyHandlers.ofString()))
.thenApply(info::findImage)
.thenCompose(url -> getBodyAsync(url, HttpResponse.BodyHandlers.ofByteArray()))
.thenApply(info::setImageData)
.thenAccept(this::process)
.exceptionally(t -> { t.printStackTrace(); return null; });
С другой стороны, следующий код, написанный в синхронном стиле и использующий простой блокирующий ввод-вывод, принесет большую пользу:
Копироватьtry {
String page = getBody(info.getUrl(), HttpResponse.BodyHandlers.ofString());
String imageUrl = info.findImage(page);
byte[] data = getBody(imageUrl, HttpResponse.BodyHandlers.ofByteArray());
info.setImageData(data);
process(info);
} catch (Exception ex) {
t.printStackTrace();
}
Такой код также проще отлаживать в отладчике, профилировать в профилировщике или наблюдать с помощью дампов потоков. Чтобы наблюдать за виртуальными потоками, создайте дамп потока с помощью команды jcmd:
Копироватьjcmd <pid> Thread.dump_to_file -format=json <file>
Чем больше стека, написанного в этом стиле, тем лучше будут виртуальные потоки как с точки зрения производительности, так и с точки зрения наблюдаемости. Программы или фреймворки, написанные в других стилях которые не выделяют поток для каждой задачи, не должны рассчитывать на значительную выгоду от виртуальных потоков. Избегайте смешивания синхронного блокирующего кода с асинхронным фреймворки.
Представляют каждую параллельную задачу как виртуальный поток; Никогда не объединяйте виртуальные потоки в пул
Самое сложное для усвоения в отношении виртуальных потоков заключается в том, что, хотя они ведут себя так же, как потоки платформы, они не должны представлять ту же программную концепцию.
Потоков платформы мало, и поэтому они являются ценным ресурсом. Драгоценными ресурсами необходимо управлять, и наиболее распространенный способ управления потоками платформы - это использование пулов потоков. Затем вам нужно ответить на вопрос, сколько потоков у нас должно быть в пуле?
Но виртуальных потоков множество, и поэтому каждый должен представлять не какой-то общий, объединенный в пул ресурс, а задачу. Из управляемого ресурса потоки превращаются в объекты предметной области приложения. Вопрос о том, сколько виртуальных потоков у нас должно быть, становится очевидным, так же как очевиден вопрос о том, сколько строк мы должны использовать для хранения набора имен пользователей в памяти: количество виртуальных потоков всегда равно количеству одновременных задач в вашем приложении.
Преобразование n потоков платформы в n виртуальных потоков дало бы мало пользы; скорее, это задачи, которые необходимо преобразовать.
Чтобы представить каждую задачу приложения в виде потока, не используйте исполнителя общего пула потоков, как в следующем примере:
КопироватьFuture<ResultA> f1 = sharedThreadPoolExecutor.submit(task1);
Future<ResultB> f2 = sharedThreadPoolExecutor.submit(task2);
// ... use futures
Вместо этого используйте исполнителя виртуальных потоков, как в следующем примере:
Копироватьtry (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
Future<ResultA> f1 = executor.submit(task1);
Future<ResultB> f2 = executor.submit(task2);
// ... use futures
}
Код по-прежнему использует ExecutorService, но тот, который возвращается из Executors.newVirtualThreadPerTaskExecutor() не использует пул потоков. Скорее, он создает новый виртуальный поток для каждой отправленной задачи.
Кроме того, это ExecutorService само по себе является легким, и мы можем создать новый точно так же, как мы сделали бы с любым простым объектом. Это позволяет нам полагаться на недавно добавленный ExecutorService.close() метод и конструкцию try-with-resources . Метод close, который неявно вызывается в конце блока try, автоматически ожидает завершения всех задач, отправленных в ExecutorService, то есть всех виртуальных потоков, порожденных ExecutorService.
Это особенно полезный шаблон для сценариев разветвления, когда вы хотите одновременно выполнять несколько исходящих вызовов в разные службы, как в следующем примере:
Копироватьvoid handle(Request request, Response response) {
var url1 = ...
var url2 = ...
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
var future1 = executor.submit(() -> fetchURL(url1));
var future2 = executor.submit(() -> fetchURL(url2));
response.send(future1.get() + future2.get());
} catch (ExecutionException | InterruptedException e) {
response.fail(e);
}
}
String fetchURL(URL url) throws IOException {
try (var in = url.openStream()) {
return new String(in.readAllBytes(), StandardCharsets.UTF_8);
}
}
Вы должны создать новый виртуальный поток, как показано выше, даже для небольших и недолговечных задач. параллельные задачи.
Для получения еще большей помощи в написании шаблона разветвления и других распространенных шаблонов параллелизма с лучшей наблюдаемостью используйте структурированный параллелизм.
Как правило, если в вашем приложении никогда не бывает 10 000 виртуальных потоков или более, виртуальные потоки вряд ли принесут ему пользу. Либо он испытывает слишком легкую нагрузку, чтобы требовать большей пропускной способности, либо вы представили недостаточно много задач виртуальным потокам.
Используют семафоры для ограничения параллелизма
Иногда возникает необходимость ограничить параллелизм определенной операции. Например, какая-либо внешняя служба может быть не в состоянии обрабатывать более десяти одновременных запросов. Поскольку потоки платформы являются ценным ресурсом, которым обычно управляют в пуле, пулы потоков стали настолько повсеместными, что их используют для ограничения параллелизма, как в следующем примере:
КопироватьExecutorService es = Executors.newFixedThreadPool(10);
...
Result foo() {
try {
var fut = es.submit(() -> callLimitedService());
return f.get();
} catch (...) { ... }
}
Этот пример гарантирует, что существует не более десяти одновременных запросов к ограниченной службе .
Но ограничение параллелизма - это всего лишь побочный эффект работы пулов потоков. Пулы предназначены для совместного использования ограниченных ресурсов, а виртуальных потоков не так уж мало, и поэтому их никогда не следует объединять!
При использовании виртуальных потоков, если вы хотите ограничить параллелизм доступа к какой-либо службе, вам следует использовать конструкцию, разработанную специально для этой цели: Semaphore класс. Следующий пример демонстрирует этот класс:
КопироватьSemaphore sem = new Semaphore(10);
...
Result foo() {
sem.acquire();
try {
return callLimitedService();
} finally {
sem.release();
}
}
Потоки, которые заходят foo будут откладываться, то есть заблокировано, так что только десять из них могут добиться прогресса в то время, пока остальные будут заниматься своими бизнес свободными.
Простая блокировка некоторых виртуальных потоков с помощью семафора может показаться существенно отличной от отправки задач в фиксированный пул потоков, но это не так. Отправка задач в пул потоков ставит их в очередь для последующего выполнения, но внутренний семафор (или любая другая конструкция блокирующей синхронизации, если уж на то пошло) создает очередь заблокированных в нем потоков, которая отражает очередь задач, ожидающих, пока объединенный поток выполнит их. Поскольку виртуальные потоки являются задачами, результирующая структура эквивалентна:
Рисунок 14-1 Сравнение пула потоков с семафором
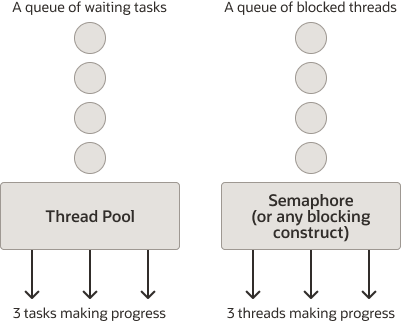
Хотя вы можете думать о пуле потоков платформы как о рабочих, обрабатывающих задачи, которые они извлекают из очереди, а о виртуальных потоках как о самих задачах, заблокированных до тех пор, пока они не смогут продолжить работу, базовое представление в компьютере практически идентично. Признание эквивалентности между задачами в очереди и заблокированными потоками поможет вам максимально использовать виртуальные потоки.
Пулы соединений с базой данных сами по себе служат семафором. Пул соединений, ограниченный десятью соединениями, заблокирует одиннадцатый поток, пытающийся установить соединение. Нет необходимости добавлять дополнительный семафор поверх пула подключений.
Не кэшируйте дорогостоящие повторно используемые объекты в локальных переменных потока
Виртуальные потоки поддерживают локальные переменные потоков так же, как потоки платформы. Смотрите Локальные переменные потоков для получения дополнительной информации. Обычно локальные переменные потока используются для связывания некоторой контекстно-зависимой информации с текущим запущенным кодом, такой как текущая транзакция и идентификатор пользователя. Такое использование локальных переменных потока вполне разумно для виртуальных потоков. Однако рассмотрите возможность использования более безопасных и эффективных значений с ограниченной областью действия. Смотрите Значения с ограниченной областью действия для получения дополнительной информации.
Существует еще одно применение локальных переменных потока, которое в корне расходится с виртуальными потоками: кэширование повторно используемых объектов. Эти объекты, как правило, дороги в создании (и потребляют значительный объем памяти), изменяемы и не потокобезопасны. Они кэшируются в локальной переменной потока, чтобы уменьшить количество раз, когда они создаются, и количество их экземпляров в памяти, но они повторно используются несколькими задачами, которые выполняются в потоке в разное время.
Например, создание экземпляра SimpleDateFormat обходится дорого и не является потокобезопасным. Возникший шаблон заключается в кэшировании такого экземпляра в ThreadLocal, как в следующем примере:
Копироватьstatic final ThreadLocal<SimpleDateFormat> cachedFormatter =
ThreadLocal.withInitial(SimpleDateFormat::new);
void foo() {
...
cachedFormatter.get().format(...);
...
}
Этот вид кэширования полезен только тогда, когда поток — и, следовательно, дорогостоящий объект кэшированный в локальном потоке — является общим и повторно используется несколькими задачами, как это было бы в случае когда потоки платформы объединены в пул. Многие задачи могут вызываться foo при выполнении в пуле потоков, но поскольку пул содержит всего несколько потоков, объект будет создаваться всего несколько раз — один раз для каждого потока пула — кэшироваться и использоваться повторно.
Однако виртуальные потоки никогда не объединяются в пул и никогда не используются повторно несвязанными задачами. Поскольку у каждой задачи есть свои собственные виртуальные потоки, каждый вызов foo из другой задачи будет вызывать создание экземпляра новой SimpleDateFormat. Более того, поскольку одновременно может выполняться очень много виртуальных потоков, дорогостоящий объект может потреблять довольно много памяти. Эти результаты прямо противоположны тому, чего намерено достичь кэширование в локальных потоках.
Единой общей альтернативы предложить нельзя, но в случае с SimpleDateFormat вам следует заменить ее на DateTimeFormatter. DateTimeFormatter является неизменяемым, и поэтому один экземпляр может быть общим для всех потоков:
Копироватьstatic final DateTimeFormatter formatter = DateTimeFormatter….;
void foo() {
...
formatter.format(...);
...
}
Обратите внимание, что использование локальных переменных потока для кэширования совместно используемых дорогостоящих объектов иногда выполняется асинхронными фреймворками за кулисами, исходя из их неявного предположения, что они используются очень небольшим количеством объединенных потоков. Это одна из причин, по которой смешивать виртуальные потоки и асинхронные фреймворки - плохая идея: вызов метода может привести к созданию дорогостоящих объектов в локальных переменных потока, которые предназначались для кэширования и совместного использования.
Избегайте длительного и частого закрепления
Текущее ограничение реализации виртуальных потоков заключается в том, что выполнение операции блокировки внутри synchronized блока или метода приводит к тому, что планировщик виртуальных потоков JDK блокирует ценный поток операционной системы, тогда как этого не было бы, если бы операция блокировки выполнялась вне synchronized блока или метода. Мы называем эту ситуацию "закреплением". Закрепление может отрицательно повлиять на пропускную способность сервера, если операция блокировки является длительной и частой. Защита кратковременных операций, таких как операции в памяти, или нечастых с помощью synchronized блоков или методов не должна иметь отрицательного эффекта.
Для обнаружения случаев закрепления, которые могут быть вредными, (JDK Flight Recorder (JFR) выдает jdk.VirtualThreadPinned поток, когда закреплена блокирующая операция; по умолчанию это событие включено, когда операция занимает больше 20 мс.
В качестве альтернативы вы можете использовать системное свойство jdk.tracePinnedThreads для создания трассировки стека, когда поток блокируется при закреплении. Запуск с опцией -Djdk.tracePinnedThreads=full выводит полную трассировку стека, когда поток блокируется при закреплении, выделяя собственные фреймы и фреймы, содержащие мониторы. Запуск с опцией -Djdk.tracePinnedThreads=short ограничивает вывод только проблемными фреймами.
Если эти механизмы обнаруживают места, где закрепление является одновременно долговременным и частым, замените использование synchronized на ReentrantLock в этих конкретных местах (опять же, нет необходимости заменять synchronized там, где оно защищает от недолговечных или нечастых операций). Ниже приведен пример длительного и частого использования syncrhonized блока.
Копироватьsynchronized(lockObj) {
frequentIO();
}
Вы можете заменить его следующим:
Копироватьlock.lock();
try {
frequentIO();
} finally {
lock.unlock();
}