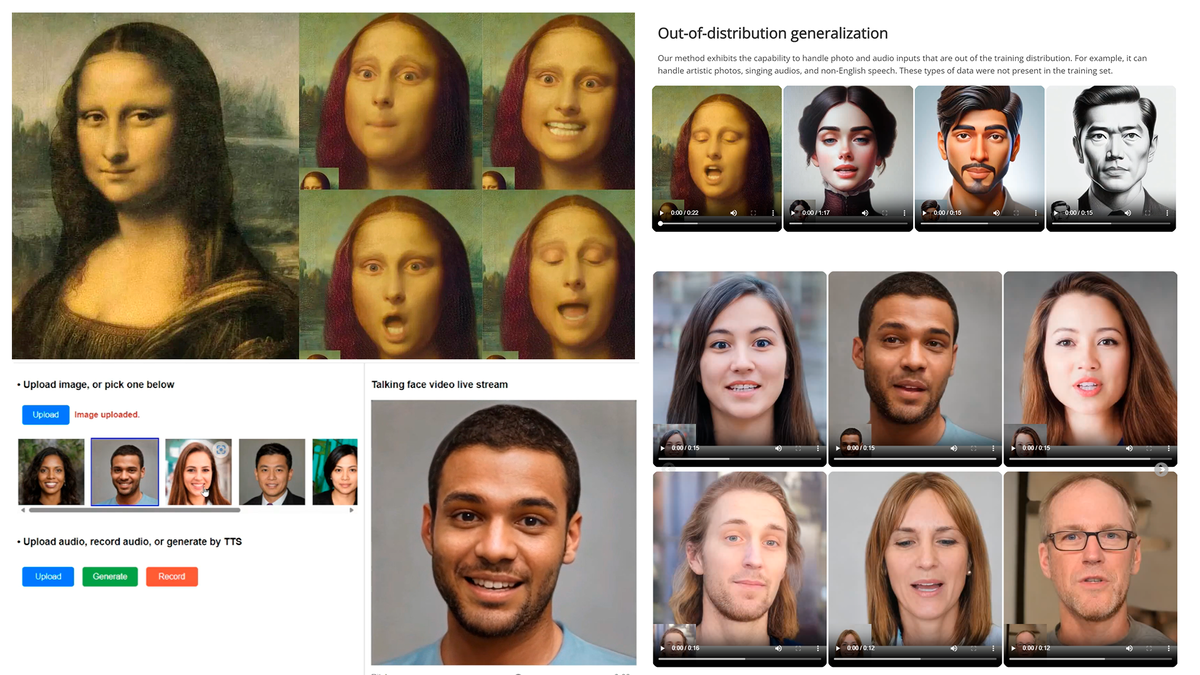
Microsoft продемонстрировала VASA-1, которая превращает фото в видео с говорящими лицами
Корпорация Microsoft разработала инновационную технологию, известную как VASA-1, которая способна трансформировать статичные портреты в динамичные видеоролики, где персонажи обретают голос. Этот инструмент ИИ с легкостью оживляет лица на фотографиях, синхронизируя их с аудиозаписями, что позволяет лицам на изображении разговаривать или петь.
VASA-1, расшифровывающаяся как Visual Affective Skills Animation, является революционным подходом в создании анимированных видео с реалистично разговаривающими персонажами на основе единственного снимка.
Пример видео.
Впечатления от работы данного инструмента вызывают восторг своей достоверностью и высоким качеством.
Главной задачей является разработка аватаров, которые обеспечивают убедительное взаимодействие между человеком и искусственным интеллектом, работающих в непрерывном режиме. Синтезированное изображение характеризуется высокой чёткостью с разрешением в 512x512 пикселей, дополняющим его качество. Важной чертой является способность имитировать мимику лица с высокой точностью, включая детализированные движения губ синхронно со звуками, что способствует усилению эффекта реальности. Кроме того, аватары способны воспроизводить естественные жесты головы, которые гармонично сочетаются с голосом. Эти особенности в совокупности обеспечивают сгенерированным видео плавность и натуральность, достигая скорости в 40 кадров в секунду в реальном времени.
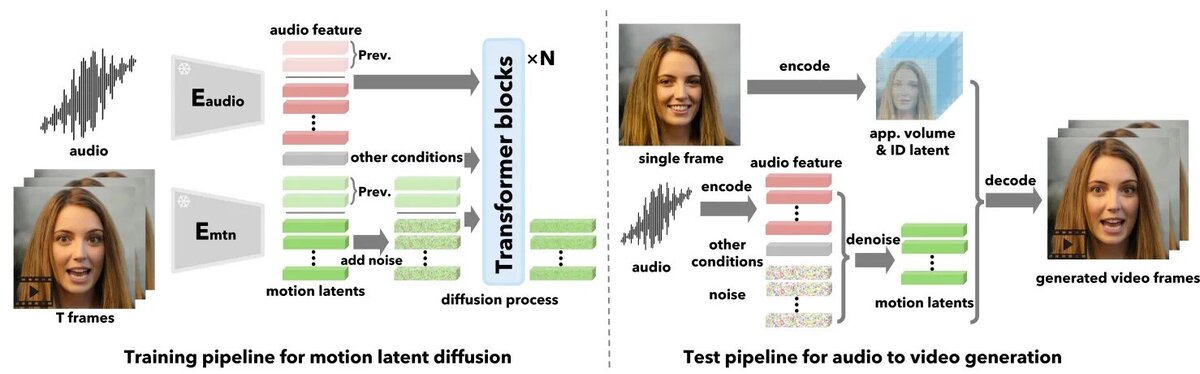
VASA не создает видеоизображения напрямую. Вместо этого, система использует скрытое пространство для моделирования динамичных аспектов лицевой анимации и движений головы, которые запускаются аудиосигналами и другими входными данными.
После получения звуковой дорожки, VASA преобразует ее в последовательности движений головы и экспрессии лица, включая мимику, движение глаз и моргание, в рамках предварительно обученного латентного пространства. Диффузная модель трансформации, которую обучают с использованием звуковых характеристик и других контрольных сигналов, таких как направление взгляда, проксемика и эмоциональные особенности, обеспечивает этот процесс.
Обученная система VASA, работающая с визуальными и аудиальными данными, начинает свою работу, обрабатывая изображение человеческого лица вместе с соответствующей звуковой дорожкой. В процессе обработки, она использует специализированный кодировщик для выявления уникальных черт и индивидуальности лица. После этого, на основе аудио, система применяет сложный алгоритм диффузии, который был подготовлен на большом количестве видеоматериалов с разговаривающими людьми, для создания последовательности движений губ и лица. В завершающей стадии, с помощью декодирования, идентифицированные латентные параметры преобразуются в реалистичное видео, демонстрирующее движущееся и разговаривающее лицо.
В отличие от альтернативных подходов, VASA-1 выделяется своей способностью точно синхронизировать движения губ с аудио, а также передавать широкий спектр эмоций и тонкие выражения лица, добавляя к видео ощущение подлинности и динамичности. Это подтверждается заметно более низким показателем FVD, что указывает на высокое качество и реалистичность получаемого результата. Для глубокого понимания механизмов работы метода рекомендуется ознакомиться с техническими деталями.
Ваши персонализированные цифровые представления могут отражать широкий спектр чувств, от радости до печали, вплоть до полного недоумения — это легко настраивается. Есть возможность даже регулировать внешность в зависимости от того, куда направлен взгляд персонажа.
Что касается качества, то достигнутый уровень реализма поражает: выражения лица персонажей выглядят удивительно гладкими и живыми. Они настолько точно имитируют настоящие эмоции, что это может показаться даже немного жутким.
Обратите внимание, что звук в этих GIF-образцах отсутствует. Однако вы можете ознакомиться с видео, сопровождающимися аудио, посетив официальный блог Microsoft, чтобы получить более полное представление.
Несмотря на заметный прогресс и стремительное развитие искусственного интеллекта сегодня, создаваемые им изображения лиц до сих пор сохраняют некоторую артифициальность. Элементы неподражаемости человеческой природы все еще проглядывают сквозь цифровые портреты.
Однако, прогресс в данной области неумолим, и нововведения появляются настолько быстро, что порой удивляют своей неожиданностью. И хотя прототип VASA-1 может выглядеть несколько необычно и отдают машинным происхождением, я полон предвкушения относительно того, какие улучшения и новшества представит нам версия 2.0.
В недавнем объявлении от Google стало известно о VLOGGER – инструменте, который оживляет статичные портреты, создавая из них трепещущие аватары. Однако такие технологии часто сталкиваются с огромными вычислительными затратами, делая невозможным их функционирование в режиме непрерывного времени.
VASA-1 приходит на помощь с новаторским подходом, используя звук для активации своей мощной генеративной модели, которая оперирует в латентном пространстве жестов и мимики. Этот метод значительно уменьшает необходимость в вычислительных ресурсах, не ущербяя качеству и детализации движений лица, и позволяет функционировать в синхроне с реальным временем.
В основе лежит интеллектуальный метод, который эффективно ускоряет рабочий процесс.
Рассмотрим случай, когда видеоматериал был создан на ПК с использованием видеокарты NVIDIA RTX 4090. Этот контент, произведенный в высоком разрешении 512x512 пикселей, демонстрируется с частотой 45 кадров в секунду для обработки данных без подключения к интернету. При этом он способен сохранять производительность до 40 кадров в секунду при трансляции в сети, с задержкой всего в 170 миллисекунд.
Реально-временные функции VASA-1 раскрывают обширные возможности для различных практических сценариев, где критически важны быстродействие и возможность взаимодействия. Вот несколько сценариев использования, которые я могу представить:
VASA-1, аналогично функционалу Vision Pro от компании Apple, применяется в сфере телеконференций и виртуального присутствия. Возможность создания синтезированных лиц, которые говорят в режиме онлайн, открывает новые перспективы для образовательных и тренировочных виртуальных программ, включая сферы здравоохранения и военные учения. Рассмотрим ситуацию: вы записываете текст, а после этого он оживает на экране благодаря технологии, которая анимирует вашу фотографию, создавая иллюзию вашего присутствия и речи. В контексте обслуживания клиентов, виртуальные помощники с реалистичными анимированными лицами способны предложить более индивидуализированное и чуткое взаимодействие, что способствует повышению лояльности и доверия со стороны потребителей.
Компания подтвердила свое решение не предоставлять общественности доступ к своей модели искусственного интеллекта. В то же время, мне любопытно представить, какие невероятные идеи для приложений могли бы возникнуть у людей, если бы у них была возможность использовать эту технологию.
Посмотрите примеры видео со звуком в официальном блоге Microsoft.
Больше новостей 📚 из мира искусственного интеллекта у нас на канале, давай догоняй!