
Недавно модель OpenAI Sora быстро завоевала популярность благодаря своим выдающимся возможностям по созданию видео, выделяясь среди других систем преобразования текста в видео и привлекая внимание на международном уровне. С запуском функции Sora Replication, которая позволяет сократить затраты на обучение и вывод данных на 46%, команда Colossal-AI представила новую открытую версию «Open-Sora 1.0». Эта версия охватывает весь процесс обучения, включая обработку данных, детали тренировочного процесса и сохранение контрольных точек модели, что позволяет объединяться энтузиастам искусственного интеллекта по всему миру для продвижения новой эры в создании видео. Теперь давайте взглянем на видео, демонстрирующее шумную городскую ночную сцену, созданное с использованием модели «Open-Sora 1.0» от команды Colossal-AI.
Это только начало возможностей технологии Open-Sora. Команда Colossal-AI открыла доступ ко всему: от исходного кода архитектуры модели до обученных контрольных точек, от деталей процесса обучения до подготовки данных, а также видео-демонстраций и обучающих материалов на нашем ресурсе в GitHub. Это позволяет всем заинтересованным в моделях преобразования текста в видео свободно изучать и применять эти технологии. Мы будем продолжать обновлять и развивать решения, связанные с Open-Sora, предоставляя последние новости и разработки в этом GitHub репозитории. Приглашаем всех оставаться в курсе последних обновлений!
Адрес открытого исходного кода Open-Sora: https://github.com/hpcaitech/Open-Sora
Глубокое погружение в технологию Open Sora В следующих разделах мы представим всестороннее объяснение основных элементов технологии воспроизведения Sora. Освещены будут такие темы, как разработка архитектуры модели, методы обучения, подготовка данных перед началом работы, визуализация результатов работы модели и наиболее эффективные стратегии оптимизации процесса обучения.
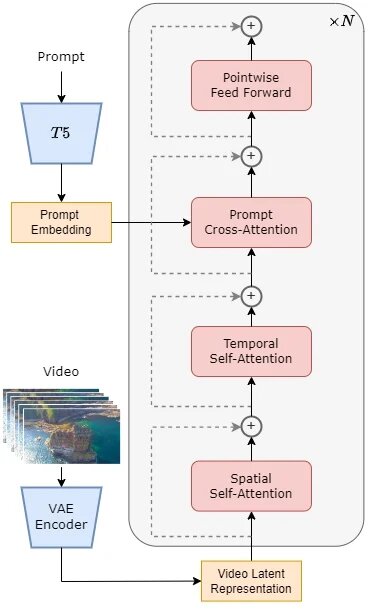
Архитектура модели в новой перспективе Наша модель использует современную архитектуру диффузионного трансформатора (DiT), которая в настоящее время пользуется большой популярностью. В качестве базы мы выбрали PixArt-α, открытую высококачественную модель для преобразования текста в изображения, основанную на DiT, и адаптировали её для создания видео, добавив уровень временного внимания. В центре нашей архитектуры находится предварительно обученный VAE, кодировщик текста и модель STDiT (преобразователь пространственной временной диффузии), применяющая механизм пространственно-временного внимания. В структуре STDiT особое внимание уделено последовательному наложению одномерного модуля временного внимания на двухмерный модуль пространственного внимания для точного моделирования временных связей. Это позволяет модулю перекрестного внимания более эффективно выравнивать текст с видеоконтентом, значительно уменьшая требования к ресурсам на этапах обучения и вывода. Наша модель STDiT, по сравнению с моделью Латте, которая также использует механизм пространственно-временного внимания, позволяет эффективнее использовать предварительно обученные веса DiT для обучения на видеоданных.
Описание процесса обучения и вывода в нашей модели В рамках этапа обучения наша модель начинает с использования предварительно обученного вариационного автоэнкодера (VAE), который компрессирует видеоданные. Далее, нашу модель STDiT обучают на внедрении текста в скрытое пространство после его сжатия. В фазе вывода мы выбираем гауссовский шум из скрытого пространства VAE случайным образом и подаем его в STDiT вместе с текстовым внедрением. Это позволяет получить особенности после шумоподавления, которые затем подаются в декодер VAE для восстановления окончательного видео. Этот подход позволяет нашей модели эффективно генерировать видео с высоким качеством и релевантностью к введенному тексту.
Многоуровневый процесс обучения в Open-Sora Наш подход к обучению модели Open-Sora вдохновлён работой по Stable Video Diffusion (SVD) и разделён на три ключевых этапа:
- Предварительная подготовка изображений крупного масштаба — на этом этапе мы фокусируемся на обработке и адаптации больших наборов изображений для создания солидной основы для видеообработки.
- Масштабное предобучение видео — после обработки изображений мы переходим к предобучению на видеоданных, расширяя и углубляя наши модели для работы с видеоконтентом.
- Тонкая настройка на видеоданных высокого качества — последний этап включает детальную настройку на высококачественных видеоданных для обеспечения наилучшего качества и точности визуализации.
Каждый этап обучения строится на весах предыдущего, позволяя многоэтапному обучению более эффективно достигать высокой производительности и качества видео. Этот поэтапный подход значительно увеличивает эффективность обучения по сравнению с методами, начинающими с нуля.
Первый этап: Формирование основы с помощью крупномасштабных изображений На первом этапе мы снижаем затраты на предварительное обучение видео, используя широкомасштабное обучение изображений с поддержкой зрелой модели преобразования текста в изображение. С обилием доступных в интернете крупномасштабных изображений и передовыми технологиями в области преобразования текста в изображение, мы разрабатываем высококачественную модель, которая служит отправной точкой для последующего видеообучения. Используя модель Stable Diffusion для предварительного обучения пространственного VAE, мы обеспечиваем не только выдающуюся производительность исходной модели, но и значительное снижение стоимости предварительного обучения видео.
Второй этап: Расширенное предварительное обучение видео Второй этап посвящен интенсивному предварительному обучению видео, целью которого является улучшение обобщающей способности модели и развитие понимания временных связей в видео. Здесь модель обогащается большим объемом видеоданных, что повышает её способность к адаптации к разнообразным видеосценариям. К базовой модели «Текст в изображение» добавляется модуль временного внимания, который помогает анализировать временные отношения. Для ускорения сходимости инициализируем выходы модуля временного внимания нулями, сохраняя при этом остальные модули неизменными и загружая в них веса из первого этапа. Для ускорения обучения и снижения его стоимости используем изображения небольшого разрешения (256x256), а также веса из открытого исходника PixArt-α для модели STDiT и модель T5 в качестве текстового кодировщика на этом этапе.
Третий этап: Финальная настройка на высококачественных видеоданных На заключительном этапе наш процесс обучения включает детальную настройку на данных видео высокого качества. Это существенно улучшает качество генерируемого видео. Видеоданные на этом этапе хоть и меньше по объему по сравнению со вторым этапом, отличаются более высокой длительностью, разрешением и качеством. Благодаря такой точечной настройке мы достигаем плавного перехода от коротких видео к длинным, от низкого к высокому разрешению и от базового к премиальному качеству.
В ходе обучения мы использовали 64 графических процессора H800, при этом затраты на GPU на втором этапе составили 2808 часов или приблизительно 7000 долларов США, а на третьем этапе – 1920 часов или около 4500 долларов США, позволяя нам удерживать общие расходы проекта в районе 10 000 долларов США.
Предварительная обработка данных Для упрощения и снижения сложности репликации Sora, команда Colossal-AI разработала простые в использовании скрипты для предобработки видеоданных, доступные в нашем кодовом репозитории. Эти скрипты помогают загружать общедоступные видеоданные, разделять длинные видео на короткие клипы с сохранением непрерывности кадров и использовать открытую модель большого языкового процессора LLaVA для создания подробных ключевых слов. Мы также предоставляем инструменты для быстрого создания видео-титров, которые с помощью двух GPU могут аннотировать видео всего за 3 секунды, достигая качества, сопоставимого с GPT-4V. Предоставленные пары видео-текст могут быть использованы непосредственно для обучения, значительно снижая технические барьеры и облегчая запуск проектов по репликации Sora.
Оптимизация процесса обучения Наши усилия направлены не только на снижение технического порога для использования технологии воспроизведения Sora, но и на улучшение качества генерации видео по таким параметрам, как продолжительность, разрешение и содержание. Кроме того, мы интегрировали систему ускорения Colossal-AI, что позволяет нам проводить обучение более эффективно. С помощью продвинутых методик обучения, включая оптимизацию ядра и гибридный параллелизм, мы достигли ускорения процессов в 1,55 раза при работе с 64-кадровыми видео разрешением 512x512. Благодаря инновационной гетерогенной системе управления памятью от Colossal-AI, мы также можем выполнить обучение видео высокого разрешения 1080p длительностью 1 минуту на одном сервере с восемью графическими процессорами H800, обеспечивая максимальную эффективность и минимизацию затрат на ресурсы.

Дополнительно, наша разработанная модель STDiT проявляет выдающуюся эффективность в процессе обучения. В сравнении с традиционной моделью DiT, которая использует механизм полного внимания, STDiT достигает ускорения процесса обучения до пятикратного увеличения при обработке увеличенного количества кадров. Это особенно значимо для решения практических задач, связанных с обработкой длинных видеопоследовательностей, где требуется повышенная производительность и скорость обработки.